







Jmeter简单压测
1、压测常用组件
1.1 线程组
可以看做一组虚拟用户,线程组中的每个线程都可以理解为一个虚拟用户。线程组组件有三部分组成,分别是取样器错误后要执行的动作、线程属性、调度器
-
取样器错误后要执行的动作
- 继续:默认设置
- 启动下一线程循环:假设一次循环中,样本有两个请求,第一个请求遇到错误,那第二个请求不再执行
- 停止线程:相当暂停错误线程参加并发的队列,现实中就是用户遇到系统崩溃后,离开系统操作
- 停止测试:遇到错误时,停止样本数继续执行,已经开始执行的等待完成后停止测试
- 立即停止测试:遇到错误整个测试停止
在3秒内启动10个线程完成,线程命名(线程1-1,线程1-2…线程1-10),每一条线程会执行所有请求各一次,如果有循环次数,每一条线程会执行重复所有请求N次,最后A请求总样本数10=B请求总样本数10。各个线程的创建、启动、调度顺序是随机的(此时四种状态是创建–启动–调度–结束,没有阻塞哦)
线程数-10,Ramp-up-3,循环次数-永远,调度持续时间30S,线程组有A请求、B请求
在3秒内启动10个线程完成,线程命名(线程1-1,线程1-2…线程1-10),每一条线程会执行所有请求各一次,线程组会持续执行30S,记得线程并发是调度功能,每一刻只有一个线程在执行。所以A请求总样本数10不一定等于B请求总样本数10 -
线程属性
-
线程数:虚拟用户数
-
Ramp-Up Period(in seconds):通俗来讲,就是运行设置的线程数所花时间。Jmeter会根据线程数/Ramp-Up算出每秒启动的线程。
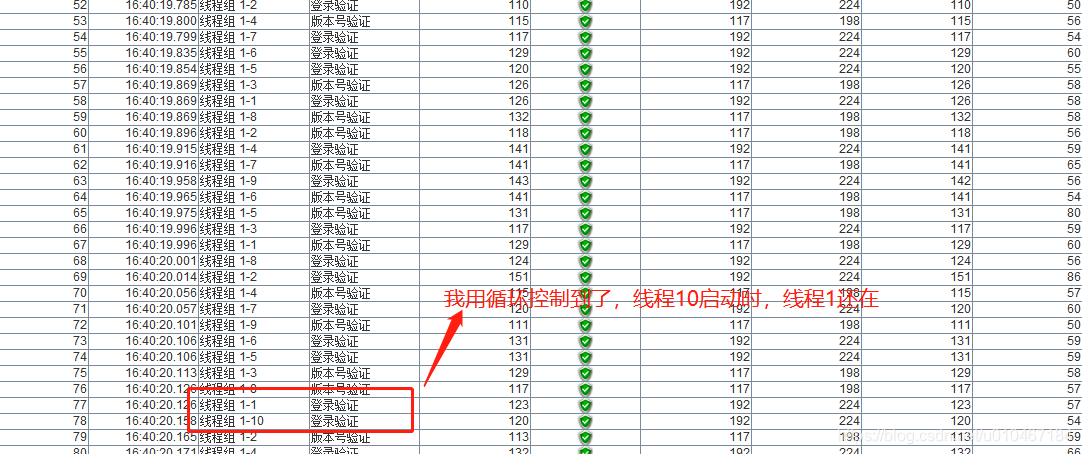
最后,我们还是不知道这个数到底怎么设置。最好的效果就是,最后一个线程开始时第一个线程真正结束了 -
循环次数:一个虚拟用户重复发送请求。为了更好的模拟并发情况,
-
场景模拟
1、线程数-10,Ramp-up=5,循环次数=1,线程组有A请求、B请求
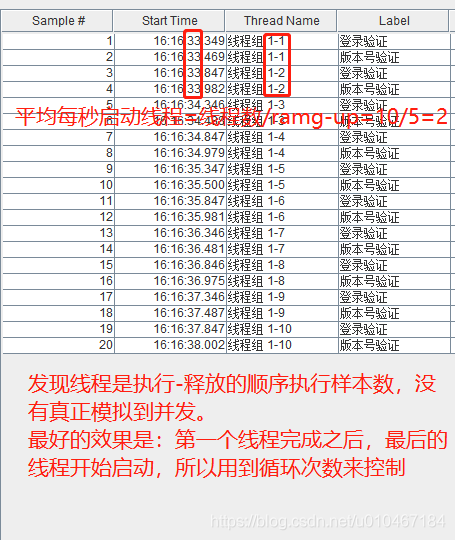
1、线程数=10,Ramp-up=2,循环次数=20,线程组有A请求、B请求。如果仔细一看,发现里面线程执行顺序是无序的。因为循环,由于线程调度执行完成后,又回到启动状态,因为还有请求执行,又等待下次的调度
-
-
调度器
模式是为了观察服务器在一个时间段内,维持某种并发的运行情况。循环次数为了模拟并发,而不是持续。
1.2 http请求
可以看做一组虚拟用户的操作行为(一般是指事务)
请求报文格式:
< request-line >
< headers >
< blank line >
[ < request-body >]
1.3 断言
1.4 察看结果树
显示所有请求响应的树,通过它可以查看任何请求的响应。
1.5 分析聚合报告
-
参数的意义
Samples:请求数
Average:平均数反映现象总体的一般水平,或分布的集中趋势。如下图的分布图一样,平均数就是大部分的数据集中的范围,反应总体的水平

Median:中位数是响应事件快慢排序后的一组数据的中间数,在性能测试中有参考意义,知道一半的数小于中位数,一半的数大于中位数
90% Line:第百分之90的耗时在这个时间以内,剩下10%的耗时至少比这个时间长。
95% Line:百分之95的耗时在这个时间以内,剩下5%的耗时至少比这个时间长。
99% Line:百分之999的耗时在这个时间以内,剩下1%的耗时至少比这个时间长。
Min:最慢的响应时间
Maximum:最大的响应时间
Error %:错误的请求
Throughput:吞吐量。吞吐量是指单位时间内系统处理的请求数量,如果直接测试请求数量,没有实际意义。一般用设置成事务(多个请求)测试吞吐量
Received KB/s:每秒接受服务器的数据量,KB单位
Sent KB/s:每秒发送到服务器的数据量,KB单位 -
聚合报告分析策略
1、平均数可以反应出总体的水平,容易受到个别极端数的影响
2、中位数可以结合最小数,判断一半数据分布情况;
3、中位数结合90%、95%、99%Line,可以判断程序哪个阶段极速上升
4、极速上升再结合Maximum -
用表格查看结果
startTime:线程执行时间
Sample Time(ms):响应时间
Latency:发送第一个请求到第一个响应时间。考虑TCP的重发机制
Connect Time:TCP三次握手时间
压测演示
压测的策略压测不要一上来就负载服务器,不符合现实情况,一般用平均点击率(程序中埋点获取这个数据)持续压测服务器,然后持续加压
压测的流程
新建线程组—>新建http请求—>添加断言—>察看结果树—>查看聚合报告—>分析聚合报告
需求:














 5589
5589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









