






这是「进击的Coder」的第 705 篇技术分享
作者:TheWeiJun
来源:逆向与爬虫的故事
“
阅读本文大概需要 9 分钟。
”目录
一、websocket 简介
二、websocket 机制
三、实战案例分析
四、完整代码实现
五、实战心得分享
趣味模块
小明是一名爬虫工程师,有一天小明去参加面试。面试官问了小明很多专业性的爬虫知识点,小明都一一对答如流;作为一个工作多年的老司机来说,这点难度不算什么!正当小明洋洋得意的时候,面试官对小明说:你有接触过 websocket 爬虫吗?小明一下子傻眼了,什么是 websocket 爬虫?那么接下来,让我们一起去看看 TheWeiJun 的 websocket 实战案例分享吧,小明阅读后,立马找到了心仪的工作。
一、什么是 websocket?
前言:WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双通讯的协议。在 WebSocket API 中,浏览器和服务器只需要做一个握手的动作,然后,浏览器和服务器之间就形成了一条快速通道。两者之间就直接可以数据互相传送。被广泛应用于对数据实时性要求较高的场景,如体育赛事播报、股票走势分析、在线聊天等。HTML5 定义了 WebSocket 协议,能更好地节省服务器资源和带宽,并且能够更实时地进行通讯。
二、websocket 机制
websocket 通信过程:
客户端发起握手请求
服务器端收到请求后验证并返回握手结果
连接建立成功,服务器端开始推送消息
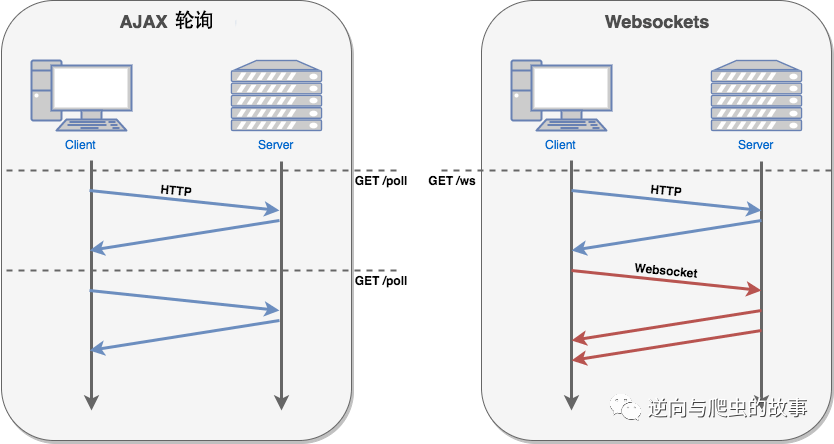
总结说明:浏览器通过 JavaScript 向服务器发出建立 WebSocket 连接的请求,连接建立以后,客户端和服务器端就可以通过 TCP 连接直接交换数据。当你获取 Web Socket 连接后,你可以通过 send() 方法来向服务器发送数据,并通过 onmessage 事件来接收服务器返回的数据。
三、实战案例分析
1、打开指定目标网站,访问指定 url 页面,截图如下所示:

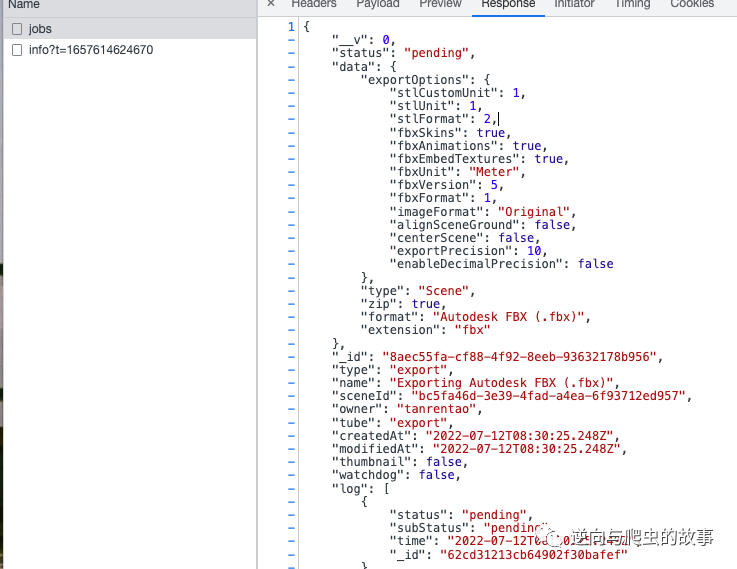
2、点击 Download 按钮,触发下载操作,在开发者模式中观察请求包,截图如下所示:
触发下载机制后,我们对浏览器页面截图如下:
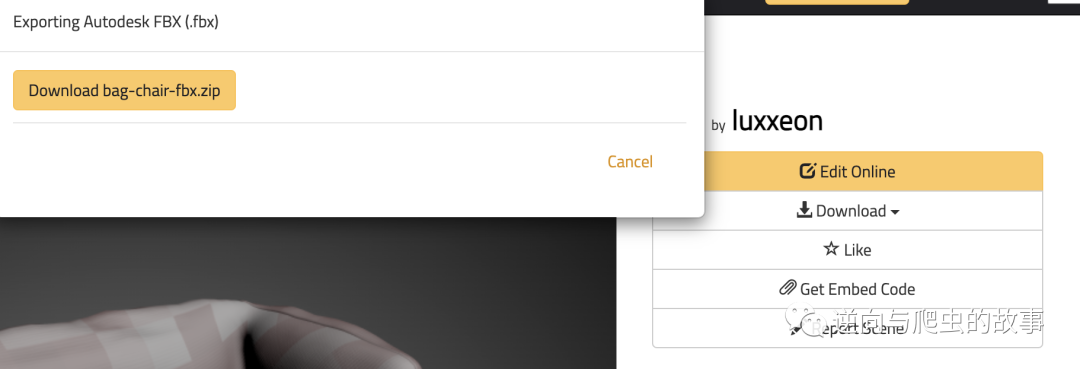
初判断:初步怀疑是使用的 AJAX 请求来下载数据,但是通过观察开发者模式数据包;并没有发现我们要的 zip 包内容。正当我疑惑时,在开发者模式【WS】栏目中看到了 websocket 请求包。
3、我们点开【WS】,会发现服务器一直在传输新的信息,这些信息应该就是我们要的数据。
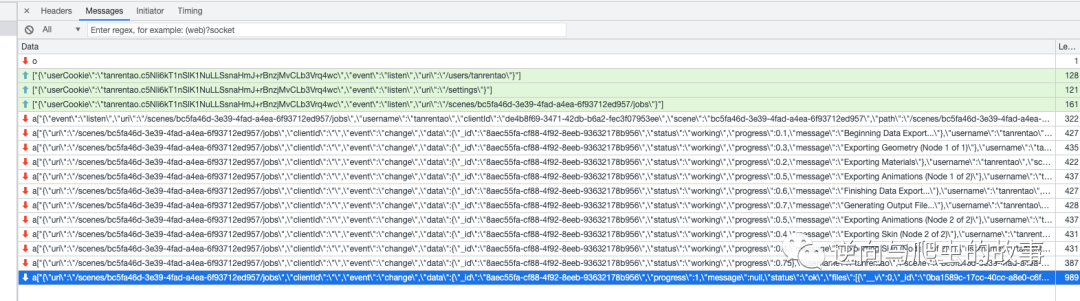
总结:观察该请求包,我们会看见三条客户端请求服务器端的绿色请求信息,也就是验证信息 message。并且经过多次刷新观察,我们发现随着下载资源的 url 路径变动,里面的 url 参数也在变动;而且我还发现,里面的 url 参数就是我刚刚下载的资源的 url 详情页的 id。可以更加确信下载的 zip 资源地址走的就是 websocket 协议。
4、查看该请求的 url、message 参数,然后我们用 python 去实现发包过程,截图如下所示:
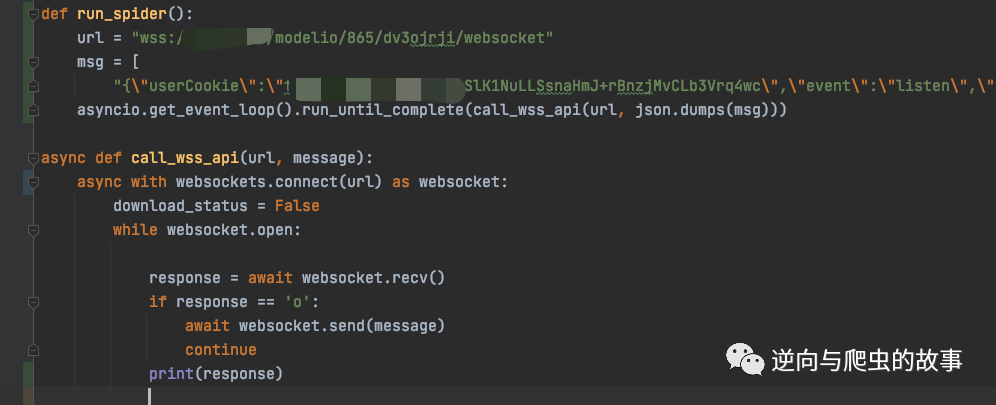
代码运行后,居然报错了,截图如下所示:
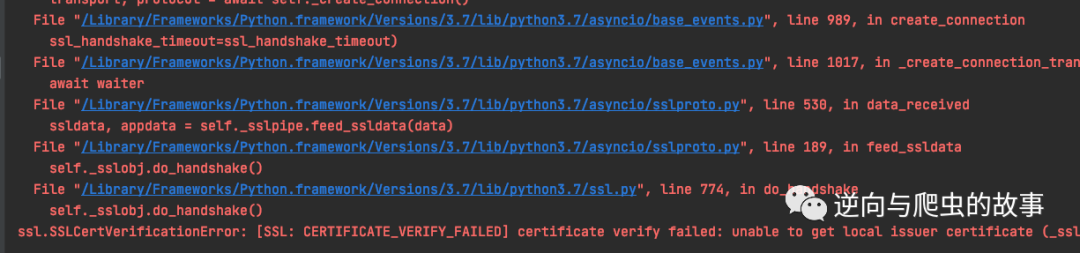
定位到问题后,在 websocket 添加 ssl 证书认证后,截图如下:
import ssl
import certifi
ssl_context = ssl.create_default_context()
ssl_context.load_verify_locations(certifi.where())
async def call_wss_api(url, message):
async with websockets.connect(url, ssl=ssl_context) as websocket:
download_status = False
while websocket.open:
response = await websocket.recv()
if response == 'o':
await websocket.send(message)
continue
print(response)
总结:再次运行代码后,观察上图,我们发现代码运行后,websocket 服务器端除了返回两条信息后不会再持续推送信息给我们,这和刚刚我们在浏览器开发者工具中看到的不一样啊。这个时候我怀疑是不是会有一些上报的操作呢,然后我再次对比,发现了规律。
5、清空 Network 路径下的所有请求包,再次触发下载机制,请求包截图如下:

总结:通过求证可以看到,的确有上报机制。当我们触发下载机制时,浏览器会发送一个 ajax 请求给 web 服务器去请求下载资源,服务器收到我们上报的信息后,会根据我们提交的参数及任务 id 找到对应的资源,通过 websocket 协议推送数据给我们,这种策略确实很少遇到。
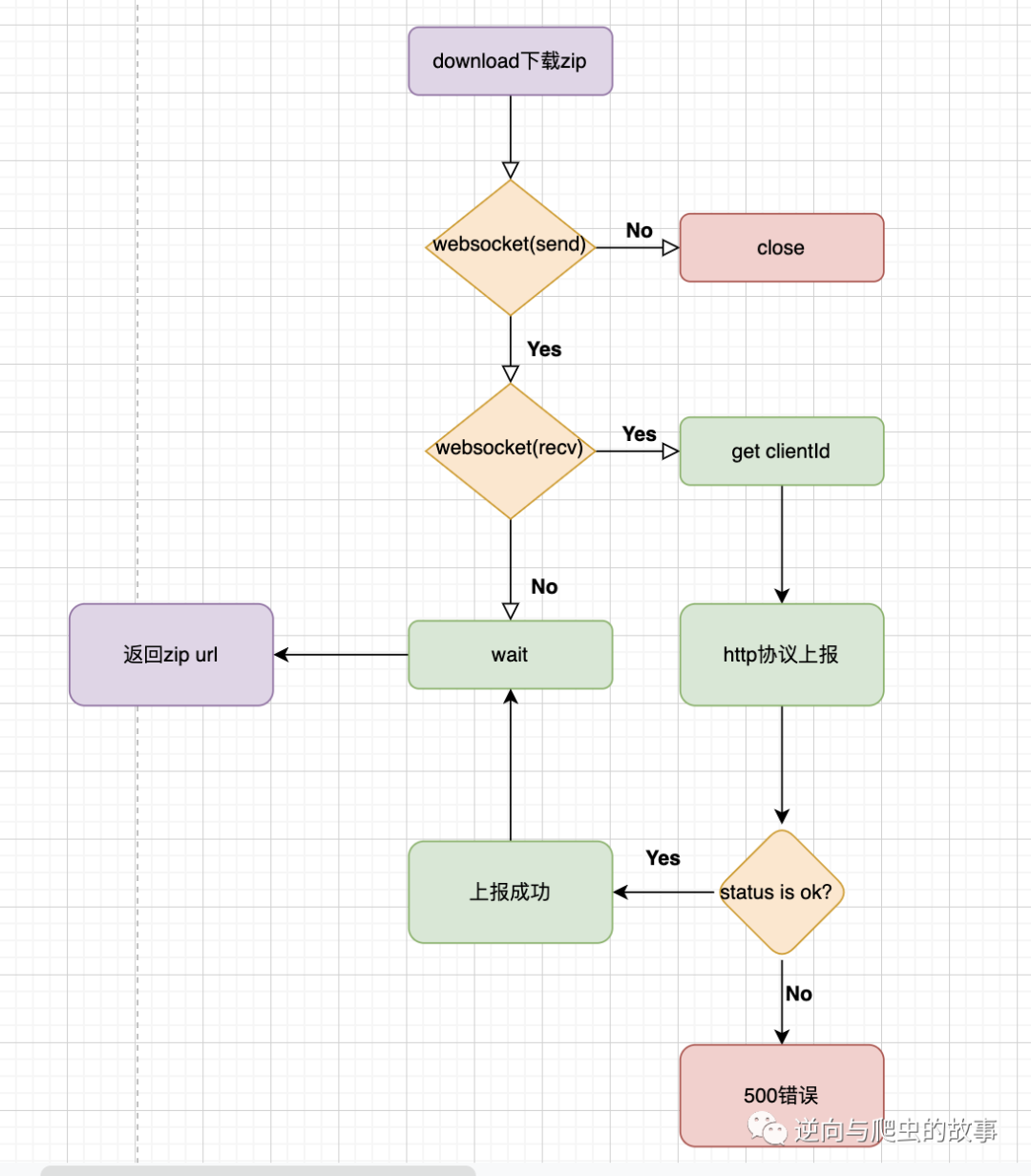
6、流程透明化后,我们梳理一下整个过程,我画了一个简单的数据流程图,如下所示:
7、代码开发完毕后,下载截图如下所示:
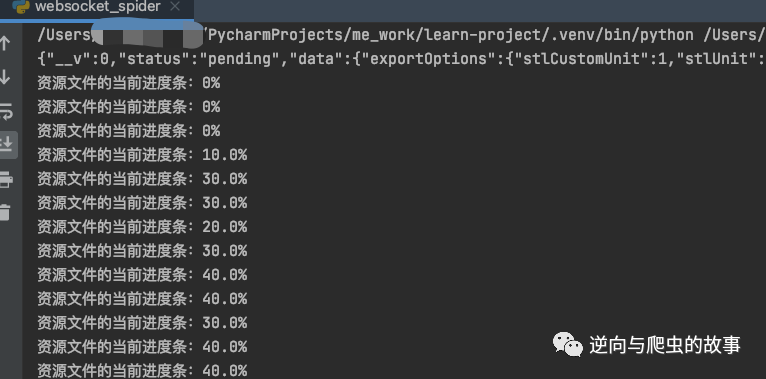
环节总结:观察上图,我们可以看到zip资源文件已经在下载了,为了方便大家观看,我特意加了一个进度条,可以实时查看进度。所有流程跑通后,接下来我们一起进入完整代码实现环节。
四、完整代码实现
核心代码实现如下:
import asyncio
import ssl
import certifi
import websockets
import json
import requests
ssl_context = ssl.create_default_context()
ssl_context.load_verify_locations(certifi.where())
def start_requests(_id):
cookies = {
# '_ga': 'GA1.2.640850929.1656902624',
# '_gid': 'GA1.2.129165265.1656902624',
'connect.sess': 's%3Aj%3A%7B%22notifications%22%3A%5B%5D%2C%22passport%22%3A%7B%22user%22%3A%22%22%7D%7D.m5wHu9pCIyrCxd%2BA3jPb%2BGXe%2B6Rqhw2jz9xGqcELyw4',
# '_gat': '1',
}
headers = {
'authority': 'clara.io',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'content-type': 'multipart/form-data; boundary=----WebKitFormBoundarylAfH6invLQtiGuL1',
'pragma': 'no-cache',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
data = '------WebKitFormBoundarylAfH6invLQtiGuL1\r\nContent-Disposition: form-data; name="attributes"\r\n\r\n{"data":{"extension":"fbx","format":"Autodesk FBX (.fbx)","zip":true,"type":"Scene","exportOptions":{"enableDecimalPrecision":false,"exportPrecision":10,"centerScene":false,"alignSceneGround":false,"imageFormat":"Original","fbxFormat":1,"fbxVersion":5,"fbxUnit":"Meter","fbxEmbedTextures":true,"fbxAnimations":true,"fbxSkins":true,"stlFormat":2,"stlUnit":1,"stlCustomUnit":1}},"name":"Exporting Autodesk FBX (.fbx)","type":"export","_id":"%s","progress":0,"status":"starting"}\r\n------WebKitFormBoundarylAfH6invLQtiGuL1--\r\n' % _id
response = requests.post('https://xxxxxx/api/scenes/xxxxxx/jobs', cookies=cookies,
headers=headers, data=data)
print(response.text)
def run_spider():
url = "wss://xxxx/modelio/865/dv3ojrji/websocket"
msg = [
"{\"userCookie\":\"c5Nli6kT1nSlK1NuLLSsnaHmJ+rBnzjMvCLb3Vrq4wc\",\"event\":\"listen\",\"uri\":\"/scenes/5a3b1964-df03-4695-8464-787472eb023a/jobs\"}"]
asyncio.get_event_loop().run_until_complete(call_wss_api(url, json.dumps(msg)))
def json_loads(response):
data = response[1:]
text = json.loads(data)[0]
return json.loads(text)
async def call_wss_api(url, message):
async with websockets.connect(url, ssl=ssl_context) as websocket:
download_status = False
while websocket.open:
response = await websocket.recv()
if response == 'o':
await websocket.send(message)
continue
item = json_loads(response)
if not download_status:
download_status = True
_id = item.get("clientId")
start_requests(_id)
progress = item.get('data', {}).get("progress") or 0
print(f"资源文件的当前进度条:{progress * 100}%")
_data = item.get("data", {}).get("files") or []
if _data:
filename = _data[0].get("name")
_hash = _data[0].get("hash")
resources = f"https://xxxx/resources/{_hash}?filename={filename}"
return resources
if __name__ == '__main__':
run_spider()五、实战心得分享
回顾整个分析流程,本次难点主要概括为以下几点:
了解并熟练掌握 websocket 协议
需要能找到资源下载规律
如何定位到上报机制 log
websocket 异步代码实现
今天分享到这里就结束了,欢迎大家关注下期文章,我们不见不散⛽️

End
崔庆才的新书《Python3网络爬虫开发实战(第二版)》已经正式上市了!书中详细介绍了零基础用 Python 开发爬虫的各方面知识,同时相比第一版新增了 JavaScript 逆向、Android 逆向、异步爬虫、深度学习、Kubernetes 相关内容,同时本书已经获得 Python 之父 Guido 的推荐,目前本书正在七折促销中!
内容介绍:《Python3网络爬虫开发实战(第二版)》内容介绍

扫码购买

好文和朋友一起看~















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









