






循环神经网络(RNN, Recurrent Neural Networks)介绍
这篇文章转载自:http://blog.csdn.net/heyongluoyao8/article/details/48636251
循环神经网络(Recurrent Neural Networks,RNNs)已经在众多自然语言处理(Natural Language Processing, NLP)中取得了巨大成功以及广泛应用。但是,目前网上与RNNs有关的学习资料很少,因此该系列便是介绍RNNs的原理以及如何实现。主要分成以下几个部分对RNNs进行介绍:
1. RNNs的基本介绍以及一些常见的RNNs(本文内容);
2. 详细介绍RNNs中一些经常使用的训练算法,如Back Propagation Through Time(BPTT)、Real-time Recurrent Learning(RTRL)、Extended Kalman Filter(EKF)等学习算法,以及梯度消失问题(vanishing gradient problem)
3. 详细介绍Long Short-Term Memory(LSTM,长短时记忆网络);
4. 详细介绍Clockwork RNNs(CW-RNNs,时钟频率驱动循环神经网络);
5. 基于Python和Theano对RNNs进行实现,包括一些常见的RNNs模型。
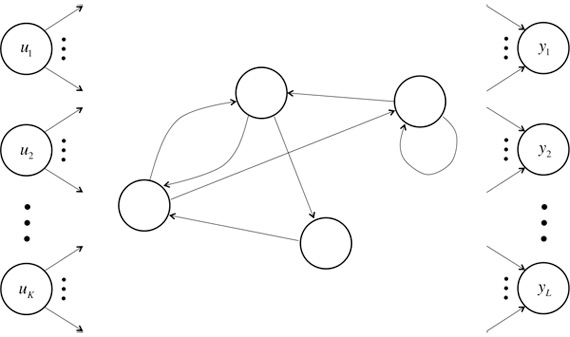
不同于传统的FNNs(Feed-forward Neural Networks,前向反馈神经网络),RNNs引入了定向循环,能够处理那些输入之间前后关联的问题。定向循环结构如下图所示:
该tutorial默认读者已经熟悉了基本的神经网络模型。如果不熟悉,可以点击:Implementing A Neural Network From Scratch进行学习。
什么是RNNs
RNNs的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNNs:

From Nature
RNNs包含输入单元(Input units),输入集标记为
{x0,x1,...,xt,xt+1,...}
,而输出单元(Output units)的输出集则被标记为
{y0,y1,...,yt,yt+1.,..}
。RNNs还包含隐藏单元(Hidden units),我们将其输出集标记为
{s0,s1,...,st,st+1,...}
,这些隐藏单元完成了最为主要的工作。你会发现,在图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
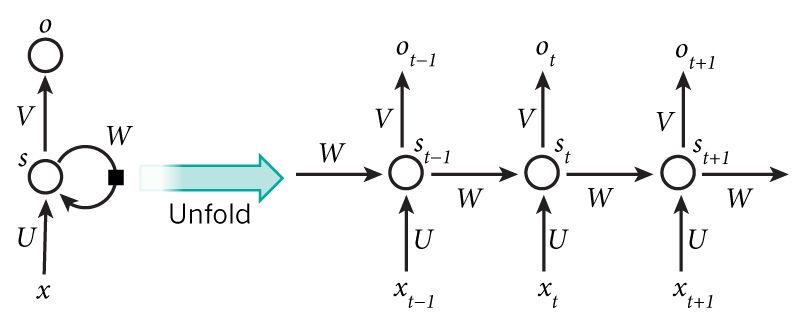
上图将循环神经网络进行展开成一个全神经网络。例如,对一个包含5个单词的语句,那么展开的网络便是一个五层的神经网络,每一层代表一个单词。对于该网络的计算过程如下:
-
xt
表示第
t,t=1,2,3...
步(step)的输入。比如,
x1
为第二个词的one-hot向量(根据上图,
x0
为第一个词);
PS:使用计算机对自然语言进行处理,便需要将自然语言处理成为机器能够识别的符号,加上在机器学习过程中,需要将其进行数值化。而词是自然语言理解与处理的基础,因此需要对词进行数值化,词向量(Word Representation,Word embeding)[1]便是一种可行又有效的方法。何为词向量,即使用一个指定长度的实数向量v来表示一个词。有一种种最简单的表示方法,就是使用One-hot vector表示单词,即根据单词的数量|V|生成一个|V| * 1的向量,当某一位为一的时候其他位都为零,然后这个向量就代表一个单词。缺点也很明显:
- 由于向量长度是根据单词个数来的,如果有新词出现,这个向量还得增加,麻烦!(Impossible to keep up to date);
- 主观性太强(subjective)
- 这么多单词,还得人工打labor并且adapt,想想就恐
- 最不能忍受的一点便是很难计算单词之间的相似性。
现在有一种更加有效的词向量模式,该模式是通过神经网或者深度学习对词进行训练,输出一个指定维度的向量,该向量便是输入词的表达。如word2vec。
- st 为隐藏层的第 t 步的状态,它是网络的记忆单元。 st 根据当前输入层的输出与上一步隐藏层的状态进行计算。 st=f(Uxt+Wst−1) ,其中 f 一般是非线性的激活函数,如tanh或ReLU,在计算 s0 时,即第一个单词的隐藏层状态,需要用到 s−1 ,但是其并不存在,在实现中一般置为0向量;
-
ot
是第
t
步的输出,如下个单词的向量表示,
ot=softmax(Vst)
.
需要注意的是: - 你可以认为隐藏层状态 st 是网络的记忆单元. st 包含了前面所有步的隐藏层状态。而输出层的输出 ot 只与当前步的 st 有关,在实践中,为了降低网络的复杂度,往往 st 只包含前面若干步而不是所有步的隐藏层状态;
- 在传统神经网络中,每一个网络层的参数是不共享的。而在RNNs中,每输入一步,每一层各自都共享参数 U,V,W 。其反应者RNNs中的每一步都在做相同的事,只是输入不同,因此大大地降低了网络中需要学习的参数;这里并没有说清楚,解释一下,传统神经网络的参数是不共享的,并不是表示对于每个输入有不同的参数,而是将RNN是进行展开,这样变成了多层的网络,如果这是一个多层的传统神经网络,那么 xt 到 st 之间的U矩阵与 xt+1 到 st+1 之间的 U 是不同的,而RNNs中的却是一样的,同理对于 s 与 s 层之间的 W 、 s 层与 o 层之间的 V 也是一样的。
- 上图中每一步都会有输出,但是每一步都要有输出并不是必须的。比如,我们需要预测一条语句所表达的情绪,我们仅仅需要关系最后一个单词输入后的输出,而不需要知道每个单词输入后的输出。同理,每步都需要输入也不是必须的。RNNs的关键之处在于隐藏层,隐藏层能够捕捉序列的信息。
RNNs能干什么?
RNNs已经被在实践中证明对NLP是非常成功的。如词向量表达、语句合法性检查、词性标注等。在RNNs中,目前使用最广泛最成功的模型便是LSTMs(Long Short-Term Memory,长短时记忆模型)模型,该模型通常比vanilla RNNs能够更好地对长短时依赖进行表达,该模型相对于一般的RNNs,只是在隐藏层做了手脚。对于LSTMs,后面会进行详细地介绍。下面对RNNs在NLP中的应用进行简单的介绍。
语言模型与文本生成(Language Modeling and Generating Text)
给你一个单词序列,我们需要根据前面的单词预测每一个单词的可能性。语言模型能够一个语句正确的可能性,这是机器翻译的一部分,往往可能性越大,语句越正确。另一种应用便是使用生成模型预测下一个单词的概率,从而生成新的文本根据输出概率的采样。语言模型中,典型的输入是单词序列中每个单词的词向量(如 One-hot vector),输出时预测的单词序列。当在对网络进行训练时,如果
ot=xt+1
,那么第
t
步的输出便是下一步的输入。
下面是RNNs中的语言模型和文本生成研究的三篇文章:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
机器翻译(Machine Translation)
机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。与语言模型关键的区别在于,需要将源语言语句序列输入后,才进行输出,即输出第一个单词时,便需要从完整的输入序列中进行获取。机器翻译如下图所示:
RNN for Machine Translation. Image Source
下面是关于RNNs中机器翻译研究的三篇文章:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
语音识别(Speech Recognition)
语音识别是指给一段声波的声音信号,预测该声波对应的某种指定源语言的语句以及该语句的概率值。
RNNs中的语音识别研究论文:
图像描述生成 (Generating Image Descriptions)
和卷积神经网络(convolutional Neural Networks, CNNs)一样,RNNs已经在对无标图像描述自动生成中得到应用。将CNNs与RNNs结合进行图像描述自动生成。这是一个非常神奇的研究与应用。该组合模型能够根据图像的特征生成描述。如下图所示:
图像描述生成中的深度视觉语义对比. Image Source
如何训练RNNs
对于RNN是的训练和对传统的ANN训练一样。同样使用BP误差反向传播算法,不过有一点区别。如果将RNNs进行网络展开,那么参数 W,U,V 是共享的,而传统神经网络却不是的。并且在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,并且还以来前面若干步网络的状态。比如,在 t=4 时,我们还需要向后传递三步,已经后面的三步都需要加上各种的梯度。该学习算法称为Backpropagation Through Time (BPTT)。后面会对BPTT进行详细的介绍。需要意识到的是,在vanilla RNNs训练中,BPTT无法解决长时依赖问题(即当前的输出与前面很长的一段序列有关,一般超过十步就无能为力了),因为BPTT会带来所谓的梯度消失或梯度爆炸问题(the vanishing/exploding gradient problem)。当然,有很多方法去解决这个问题,如LSTMs便是专门应对这种问题的。
RNNs扩展和改进模型
这些年,研究者们已经提出了多钟复杂的RNNs去改进vanilla RNN模型的缺点。下面是目前常见的一些RNNs模型,后面会对其中使用比较广泛的进行详细讲解,在这里进行简单的概述。
Simple RNNs(SRNs)[2]
SRNs是RNNs的一种特例,它是一个三层网络,并且在隐藏层增加了上下文单元,下图中的
y
便是隐藏层,
u
便是上下文单元。上下文单元节点与隐藏层中的节点的连接是固定(谁与谁连接)的,并且权值也是固定的(值是多少),其实是一个上下文节点与隐藏层节点一一对应,并且值是确定的。在每一步中,使用标准的前向反馈进行传播,然后使用学习算法进行学习。上下文每一个节点保存其连接的隐藏层节点的上一步的输出,即保存上文,并作用于当前步对应的隐藏层节点的状态,即隐藏层的输入由输入层的输出与上一步的自己的状态所决定的。因此SRNs能够解决标准的多层感知机(MLP)无法解决的对序列数据进行预测的任务。
SRNs网络结构如下图所示:
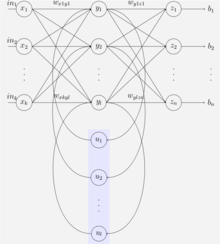
Bidirectional RNNs[3]
Bidirectional RNNs(双向网络)的改进之处便是,假设当前的输出(第
t
步的输出)不仅仅与前面的序列有关,并且还与后面的序列有关。例如:预测一个语句中缺失的词语那么就需要根据上下文来进行预测。Bidirectional RNNs是一个相对较简单的RNNs,是由两个RNNs上下叠加在一起组成的。输出由这两个RNNs的隐藏层的状态决定的。如下图所示:
Deep(Bidirectional)RNNs[4]
Deep(Bidirectional)RNNs与Bidirectional RNNs相似,只是对于每一步的输入有多层网络。这样,该网络便有更强大的表达与学习能力,但是复杂性也提高了,同时需要更多的训练数据。Deep(Bidirectional)RNNs的结构如下图所示:

Echo State Networks[5]
ESNs(回声状态网络)虽然也是一种RNNs,但是它与传统的RNNs相差很大。ESNs具有三个特点:
- 它的核心结构时一个随机生成、且保持不变的储备池(Reservoir),储备池是大规模的、随机生成的、稀疏连接(SD通常保持1%~5%,SD表示储备池中互相连接的神经元占总的神经元个数N的比例)的循环结构;
- 其储备池到输出层的权值矩阵是唯一需要调整的部分;
- 简单的线性回归就可完成网络的训练。
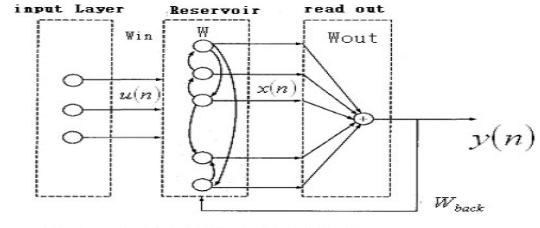
从结构上讲,ESNs是一种特殊类型的循环神经网络,其基本思想是:使用大规模随机连接的循环网络取代经典神经网络中的中间层,从而简化网络的训练过程。因此ESNs的关键是中间的储备池。网络中的参数包括:
W
为储备池中节点的连接权值矩阵,
Win
为输入层到储备池之间的连接权值矩阵,表明储备池中的神经元之间是连接的,
Wback
为输出层到储备池之间的反馈连接权值矩阵,表明储备池会有输出层来的反馈,
Wout
为输入层、储备池、输出层到输出层的连接权值矩阵,表明输出层不仅与储备池连接,还与输入层和自己连接。
Woutbias
表示输出层的偏置项。
对于ESNs,关键是储备池的四个参数,如储备池内部连接权谱半径SR(
SR=λmax=max{|W的特征指|}
,只有SR <1时,ESNs才能具有回声状态属性)、储备池规模N(即储备池中神经元的个数)、储备池输入单元尺度IS(IS为储备池的输入信号连接到储备池内部神经元之前需要相乘的一个尺度因子)、储备池稀疏程度SD(即为储备池中互相连接的神经元个数占储备池神经元总个数的比例)。对于IS,如果需要处理的任务的非线性越强,那么输入单元尺度越大。该原则的本质就是通过输入单元尺度IS,将输入变换到神经元激活函数相应的范围(神经元激活函数的不同输入范围,其非线性程度不同)。
ESNs的结构如下图所示:
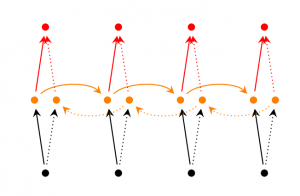
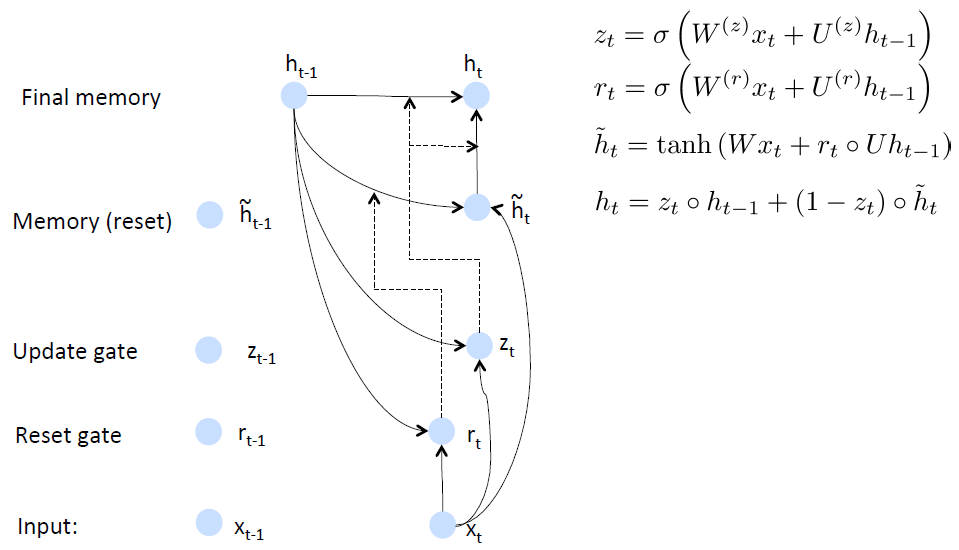
Gated Recurrent Unit Recurrent Neural Networks[6]
GRUs也是一般的RNNs的改良版本,主要是从以下两个方面进行改进。一是,序列中不同的位置处的单词(已单词举例)对当前的隐藏层的状态的影响不同,越前面的影响越小,即每个前面状态对当前的影响进行了距离加权,距离越远,权值越小。二是,在产生误差error时,误差可能是由某一个或者几个单词而引发的,所以应当仅仅对对应的单词weight进行更新。GRUs的结构如下图所示。GRUs首先根据当前输入单词向量word vector已经前一个隐藏层的状态hidden state计算出update gate和reset gate。再根据reset gate、当前word vector以及前一个hidden state计算新的记忆单元内容(new memory content)。当reset gate为1的时候,new memory content忽略之前的所有memory content,最终的memory是之前的hidden state与new memory content的结合。
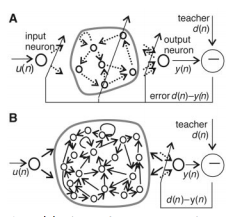
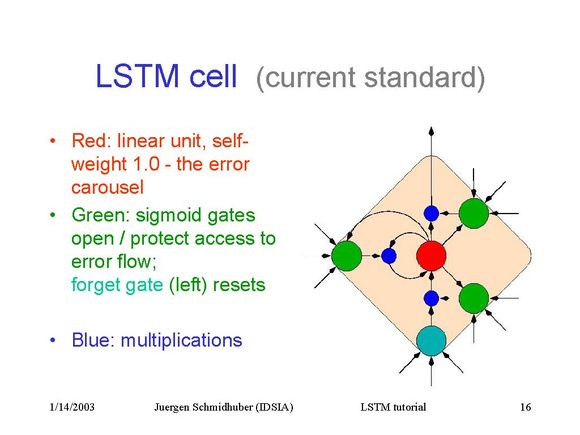
LSTM Netwoorks[7]
LSTMs与GRUs类似,目前非常流行。它与一般的RNNs结构本质上并没有什么不同,只是使用了不同的函数去去计算隐藏层的状态。在LSTMs中,i结构被称为cells,可以把cells看作是黑盒用以保存当前输入
xt
之前的保存的状态
ht−1
,这些cells更加一定的条件决定哪些cell抑制哪些cell兴奋。它们结合前面的状态、当前的记忆与当前的输入。已经证明,该网络结构在对长序列依赖问题中非常有效。LSTMs的网络结构如下图所示。对于LSTMs的学习,参见 this post has an excellent explanation
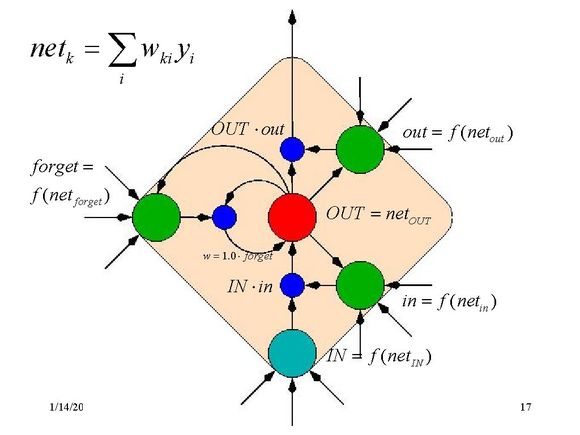
LSTMs解决的问题也是GRU中所提到的问题,如下图所示:
LSTMs与GRUs的区别如图所示[8]:
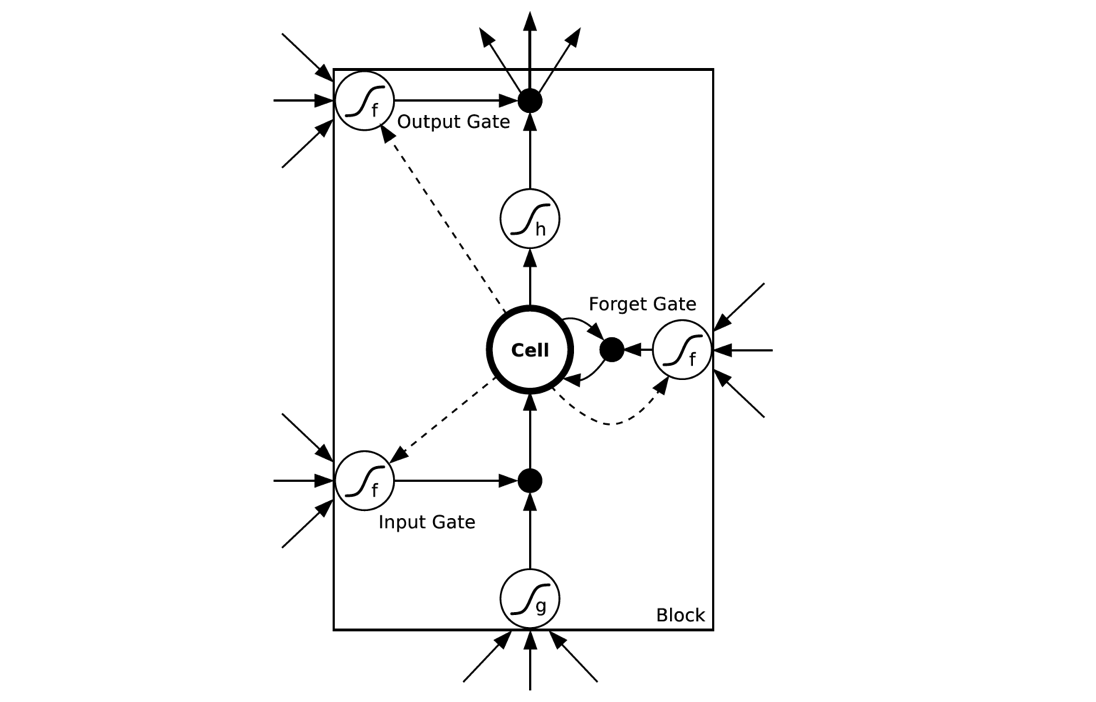

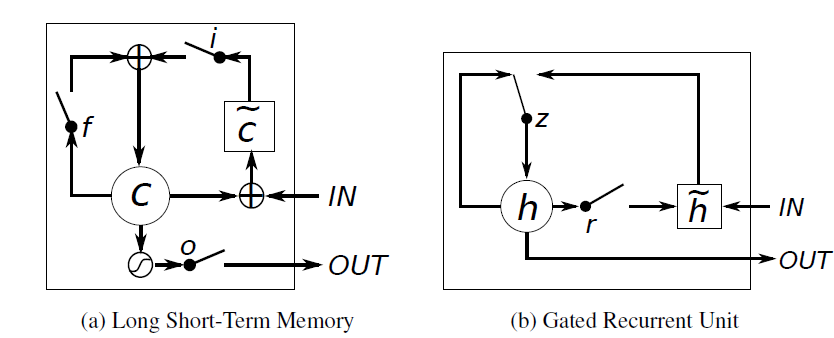
从上图可以看出,它们之间非常相像,不同在于:
- new memory的计算方法都是根据之前的state及input进行计算,但是GRUs中有一个reset gate控制之前state的进入量,而在LSTMs里没有这个gate;
- 产生新的state的方式不同,LSTMs有两个不同的gate,分别是forget gate (f gate)和input gate(i gate),而GRUs只有一个update gate(z gate);
- LSTMs对新产生的state又一个output gate(o gate)可以调节大小,而GRUs直接输出无任何调节。
在这里插入一些从别的博客里面找到的关于LSTM原理的介绍内容,可以很好的与上图进行结合理解:
LSTM 网络
Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由 Hochreiter & Schmidhuber (1997) 提出,并在近期被 Alex Graves 进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/cccad95962c48df4684d1c14b2e71b2d.png)
标准 RNN 中的重复模块包含单一的层
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/89ca83f190abf9a9920d34df895c09c2.png)
LSTM 中的重复模块包含四个交互的层
注意上图中间的方框内容,可以参考上面那几个公式进行理解。
不必担心这里的细节。我们会一步一步地剖析 LSTM 解析图。现在,我们先来熟悉一下图中使用的各种元素的图标。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/d1a917af219fafadf870aeb95b733113.png)
在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
LSTM 的核心思想
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/da7f3a3100ead66eee883fecc341abe8.png)
Paste_Image.png
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/003f87524872d18b1fd9f0aa68bd2b8e.png)
Paste_Image.png
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
LSTM 拥有三个门,来保护和控制细胞状态。
逐步理解 LSTM
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为 忘记门层 完成。该门会读取h_{t-1}和x_t,输出一个在 0 到 1 之间的数值给每个在细胞状态C_{t-1}中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前 主语 的类别,因此正确的 代词 可以被选择出来。当我们看到新的 代词 ,我们希望忘记旧的代词 。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/64dc15e1c2e7618e0f671ca7af638695.png)
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,\tilde{C}_t,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
在我们语言模型的例子中,我们希望增加新的代词的类别到细胞状态中,来替代旧的需要忘记的代词。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/5bf5847ad329308e20e06eb36e8b8b1c.png)
现在是更新旧细胞状态的时间了,C_{t-1}更新为C_t。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与f_t相乘,丢弃掉我们确定需要丢弃的信息。接着加上i_t * \tilde{C}_t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的类别信息并添加新的信息的地方。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/680b7f0b8ce6730916d49b3a755b924b.png)
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词 ,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/3d71acf7dde967b1cce447889c4f92d6.png)
LSTM 的变体
我们到目前为止都还在介绍正常的 LSTM。但是不是所有的 LSTM 都长成一个样子的。实际上,几乎所有包含 LSTM 的论文都采用了微小的变体。差异非常小,但是也值得拿出来讲一下。
其中一个流形的 LSTM 变体,就是由 Gers & Schmidhuber (2000) 提出的,增加了 “peephole connection”。是说,我们让 门层 也会接受细胞状态的输入。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/a4e2aeda30d18a267bf79eb532cce6e8.png)
上面的图例中,我们增加了 peephole 到每个门上,但是许多论文会加入部分的 peephole 而非所有都加。
另一个变体是通过使用 coupled 忘记和输入门。不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定。我们仅仅会当我们将要输入在当前位置时忘记。我们仅仅输入新的值到那些我们已经忘记旧的信息的那些状态 。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/c9e8ac728300b1ace4efa1c3ca46d791.png)
coupled 忘记门和输入门
另一个改动较大的变体是 Gated Recurrent Unit (GRU),这是由 Cho, et al. (2014) 提出。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
![[译] 理解 LSTM 网络](https://i-blog.csdnimg.cn/blog_migrate/29c4456a315763ba8999355ccd04bf3f.png)
这里只是部分流行的 LSTM 变体。当然还有很多其他的,如 Yao, et al. (2015) 提出的 Depth Gated RNN。还有用一些完全不同的观点来解决长期依赖的问题,如 Koutnik, et al. (2014) 提出的 Clockwork RNN。
要问哪个变体是最好的?其中的差异性真的重要吗? Greff, et al. (2015) 给出了流行变体的比较,结论是他们基本上是一样的。 Jozefowicz, et al. (2015) 则在超过 1 万中 RNN 架构上进行了测试,发现一些架构在某些任务上也取得了比 LSTM 更好的结果。
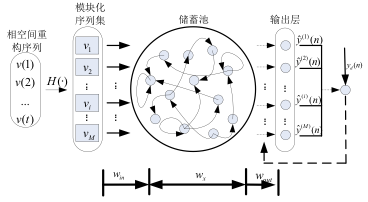
Clockwork RNNs(CW-RNNs)[9]
CW-RNNs是较新的一种RNNs模型,其论文发表于2014年Beijing ICML。在原文[8]中作者表示其效果较SRN与LSTMs都好。
CW-RNNs也是一个RNNs的改良版本,是一种使用时钟频率来驱动的RNNs。它将隐藏层分为几个块(组,Group/Module),每一组按照自己规定的时钟频率对输入进行处理。并且为了降低标准的RNNs的复杂性,CW-RNNs减少了参数的数目,提高了网络性能,加速了网络的训练。CW-RNNs通过不同的隐藏层模块工作在不同的时钟频率下来解决长时间依赖问题。将时钟时间进行离散化,然后在不同的时间点,不同的隐藏层组在工作。因此,所有的隐藏层组在每一步不会都同时工作,这样便会加快网络的训练。并且,时钟周期小的组的神经元的不会连接到时钟周期大的组的神经元,只会周期大的连接到周期小的(认为组与组之间的连接是有向的就好了,代表信息的传递是有向的),周期大的速度慢,周期小的速度快,那么便是速度慢的连速度快的,反之则不成立。现在还不明白不要紧,下面会进行讲解。
CW-RNNs与SRNs网络结构类似,也包括输入层(Input)、隐藏层(Hidden)、输出层(Output),它们之间也有向前连接,输入层到隐藏层的连接,隐藏层到输出层的连接。但是与SRN不同的是,隐藏层中的神经元会被划分为若干个组,设为
g
,每一组中的神经元个数相同,设为
k
,并为每一个组分配一个时钟周期
Ti∈{T1,T2,...,Tg}
,每一个组中的所有神经元都是全连接,但是组
j
到组
i
的循环连接则需要满足
Tj
大于
Ti
。如下图所示,将这些组按照时钟周期递增从左到右进行排序,即
T1<T2<...<Tg
,那么连接便是从右到左。例如:隐藏层共有256个节点,分为四组,周期分别是[1,2,4,8],那么每个隐藏层组256/4=64个节点,第一组隐藏层与隐藏层的连接矩阵为64*64的矩阵,第二层的矩阵则为64*128矩阵,第三组为64*(3*64)=64*192矩阵,第四组为64*(4*64)=64*256矩阵。这就解释了上一段的后面部分,速度慢的组连到速度快的组,反之则不成立。
CW-RNNs的网络结构如下图所示:
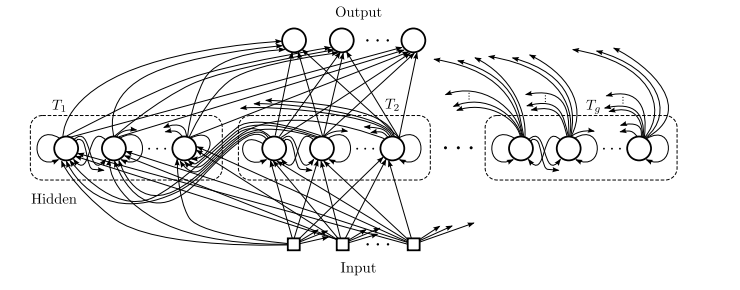
在传统的RNN中,按照下面的公式进行计算:
其中, W 为隐藏层神经元的自连接矩阵, Win 为输入层到隐藏层的连接权值矩阵, Wout 是隐藏层到输出层的连接权值矩阵 , xt 是第 t 步的输入, st−1 为第 t−1 步隐藏层的输出, st 为第 t 步隐藏层的输出, ot 为第 t 步的输出, fs 为隐藏层的激活函数, fo 为输出层的激活函数。
与传统的RNNs不同的是,在第 t 步时,只有那些满足 (tmodTi)=0 的隐藏层组才会执行。并且每一隐藏层组的周期 {T1,T2,...,Tg} 都可以是任意的。原文中是选择指数序列作为它们的周期,即 Ti=2i−1i∈[1,...,g] 。
因此 W 与 Win 将被划分为 g 个块。如下:
其中 W 是一个上三角矩阵,每一个组行 Wi 被划分为列向量 {W1i,...,Wii,0(i+1)i,...,0gi}T , Wji,j∈[1,...,g] 表示第i个组到第j个组的连接权值矩阵。在每一步中, W 与 Win 只有部分组行处于执行状态,其它的为0:
为了使表达不混淆,将 Win 写成 Win 。并且执行的组所对应的 o 才会有输出。处于非执行状态下的隐藏层组仍保留着上一步的状态。下图是含五个隐藏层组在 t=6 时的计算图:
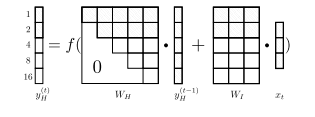
在CW-RNNs中,慢速组(周期大的组)处理、保留、输出长依赖信息,而快速组则会进行更新。CW-RNNs的误差后向传播也和传统的RNNs类似,只是误差只在处于执行状态的隐藏层组进行传播,而非执行状态的隐藏层组也复制其连接的前面的隐藏层组的后向传播。即执行态的隐藏层组的误差后向传播的信息不仅来自与输出层,并且来自与其连接到的左边的隐藏层组的后向传播信息,而非执行态的后向传播信息只来自于其连接到的左边的隐藏层组的后向传播数据。
下图是原文对三个不同RNNs模型的实验结果图:
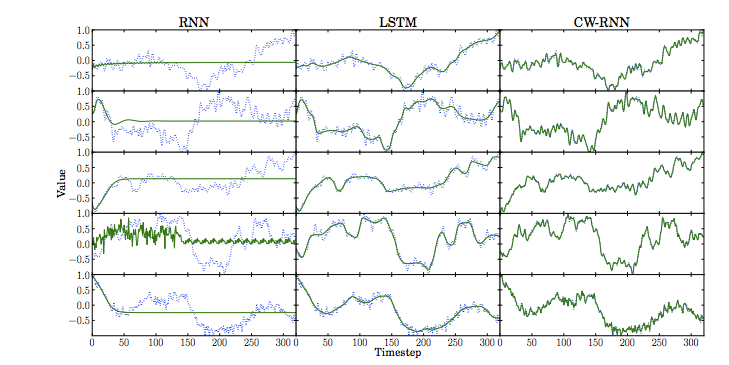
上图中,绿色实线是预测结果,蓝色散点是真实结果。每个模型都是对前半部分进行学习,然后预测后半部分。LSTMs模型类似滑动平均,但是CW-RNNs效果更好。其中三个模型的输入层、隐藏层、输出层的节点数都相同,并且只有一个隐藏层,权值都使用均值为0,标准差为0.1的高斯分布进行初始化,隐藏层的初始状态都为0,每一个模型都使用 Nesterov-style
momentum SGD(Stochastic Gradient Descent,随机梯度下降算法)[10] 进行学习与优化。
总结
到目前为止,本文对RNNs进行了基本的介绍,并对常见的几种RNNs模型进行了初步讲解。下一步将基于Theano与Python实现一个RNNs语言模型并对上面的一些RNNs模型进行详解。这里有更多的RNNs模型。















 53万+
53万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









