










文章目录
一. 数据集介绍
数据包含球员和裁判的信息,2012-2013年的比赛数据,总共设计球员2053名,裁判3147名。

数据集特征:
playerShort 球员ID
player 球员姓名
club 俱乐部
leagueCountry 俱乐部国籍
birthday 出生日期
height 身高
weight 体重
position 所踢位置
games 球员-裁判二分体的比赛次数
victories 胜
ties 平
defeats 输
goals 进球数
yellowCards 黄牌数
yellowReds 黄转红数
redCards 红牌数
photoID 照片ID
rater1 值越大肤色越黑
rater2 值越大肤色越黑
refNum 裁判的ID
refCountry 裁判的国籍
Alpha_3
meanIAT 主裁判国家的平均内隐偏差分数(使用IAT)
nIAT 在那个特定国家的种族IAT的样本大小
seIAT 种族IAT平均估计的标准误差
meanExp 主裁判国家的显式偏差分数(使用种族温度计测试)的平均值
nExp nexp的样本大小对特定国家的显性偏差
seExp 显式偏差测度平均估计的标准误差
二. EDA之提出假设
2.1 假设
对于裁判给深肤色球员更多红牌的问题,我们该如何操作?
-
反事实:
如果球员肤色较轻,在相同的条件下,同样的进攻,裁判更有可能给黄牌或不给牌。 -
回归:
考虑到混淆,深色玩家对红牌/总牌的比例的回归系数为正 -
潜在问题
如何结合rater1和rater2?平均?如果他们不同意怎么办?把它扔出去吗?
数据是否不平衡,即红牌非常罕见?
数据是否存在偏差,即玩家的游戏时间长短不同?这是他们整个职业生涯的总结吗?
我怎么知道我已经解释了所有形式的混淆?
首先,所有裁判都存在系统性的歧视吗?
探索/假设:
-
游戏的分布
-
红牌vs比赛
2.1) 每次游戏的红色vs每次游戏的纸牌总数
2.2) 所有玩家按平均肤色进行的游戏中,#红色、#黄色、总卡牌数和红色分数的分布情况 -
球员们遇到了多少裁判?
是否有些俱乐部打得更有侵略性,得到的牌也更多?还是更矜持,得到的却更少? -
分类是否因联赛和国家而异?
在相同的位置上,得分高的人是否会有更多的空闲时间(更少的卡牌)? -
有没有一些裁判给的红牌/黄牌比其他裁判多?
-
评级者的一致性如何?跟科恩的卡帕核对一下。
-
红牌是如何因位置而异的?例如,后卫得到更多?
-
拥有更多游戏的玩家是否能够获得更多纸牌?不同肤色的玩家是否拥有不同纸牌?
-
根据refCountry?
2.2 数据的分布及整理
2.2.1 初步数据查看
代码:
import pandas as pd
# 读取数据源
df = pd.read_csv("E:/file/redcard.csv.gz", compression='gzip')
# 查看数据源的 行数和列数
print(df.shape)
# 查看数据源的前几行
print(df.head())
# 查看数据源的中各列的 总数 均值 等
print(df.describe().T)
# 查看数据源中的数据类别
print(df.dtypes)
# 打印所有的列
all_columns = df.columns.tolist()
print(all_columns)
测试记录:
(146028, 28)
playerShort player club ... meanExp nExp seExp
0 lucas-wilchez Lucas Wilchez Real Zaragoza ... 0.396000 750.0 0.002696
1 john-utaka John Utaka Montpellier HSC ... -0.204082 49.0 0.061504
2 abdon-prats Abdón Prats RCD Mallorca ... 0.588297 1897.0 0.001002
3 pablo-mari Pablo Marí RCD Mallorca ... 0.588297 1897.0 0.001002
4 ruben-pena Rubén Peña Real Valladolid ... 0.588297 1897.0 0.001002
[5 rows x 28 columns]
count mean ... 75% max
height 145765.0 181.935938 ... 187.000000 2.030000e+02
weight 143785.0 76.075662 ... 81.000000 1.000000e+02
games 146028.0 2.921166 ... 3.000000 4.700000e+01
victories 146028.0 1.278344 ... 2.000000 2.900000e+01
ties 146028.0 0.708241 ... 1.000000 1.400000e+01
defeats 146028.0 0.934581 ... 1.000000 1.800000e+01
goals 146028.0 0.338058 ... 0.000000 2.300000e+01
yellowCards 146028.0 0.385364 ... 1.000000 1.400000e+01
yellowReds 146028.0 0.011381 ... 0.000000 3.000000e+00
redCards 146028.0 0.012559 ... 0.000000 2.000000e+00
rater1 124621.0 0.264255 ... 0.250000 1.000000e+00
rater2 124621.0 0.302862 ... 0.500000 1.000000e+00
refNum 146028.0 1534.827444 ... 2345.000000 3.147000e+03
refCountry 146028.0 29.642842 ... 44.000000 1.610000e+02
meanIAT 145865.0 0.346276 ... 0.369894 5.737933e-01
nIAT 145865.0 19697.411216 ... 7749.000000 1.975803e+06
seIAT 145865.0 0.000631 ... 0.000229 2.862871e-01
meanExp 145865.0 0.452026 ... 0.588297 1.800000e+00
nExp 145865.0 20440.233860 ... 7974.000000 2.029548e+06
seExp 145865.0 0.002994 ... 0.001002 1.060660e+00
[20 rows x 8 columns]
playerShort object
player object
club object
leagueCountry object
birthday object
height float64
weight float64
position object
games int64
victories int64
ties int64
defeats int64
goals int64
yellowCards int64
yellowReds int64
redCards int64
photoID object
rater1 float64
rater2 float64
refNum int64
refCountry int64
Alpha_3 object
meanIAT float64
nIAT float64
seIAT float64
meanExp float64
nExp float64
seExp float64
dtype: object
['playerShort', 'player', 'club', 'leagueCountry', 'birthday', 'height', 'weight', 'position', 'games', 'victories', 'ties', 'defeats', 'goals', 'yellowCards', 'yellowReds', 'redCards', 'photoID', 'rater1', 'rater2', 'refNum', 'refCountry', 'Alpha_3', 'meanIAT', 'nIAT', 'seIAT', 'meanExp', 'nExp', 'seExp']
2.2.2 数据分布
了解数据是如何分布的:
该数据集是一个单独的csv,它将裁判和球员之间的每个交互聚合到单个行中。换句话说:裁判A在10场比赛中裁判B,并在这10场比赛中给了2张红牌。那么数据集中就会有一个唯一的行表示:
裁判A,球员B, 2张红牌,…
这意味着理解和处理这些数据的第一步有点棘手。首先,关于球员B的信息每次都是重复的——这意味着如果我们对某些指标进行简单的平均,我们很可能会得到一个误导的结果。
例如,问“运动员的平均体重是多少?”
代码:
import numpy as np
import pandas as pd
# 读取数据源
df = pd.read_csv("E:/file/redcard.csv.gz", compression='gzip')
print(df['height'].mean())
print(np.mean(df.groupby('playerShort').height.mean()))
测试记录:
不要小看了这个差异,第二个才是真正的球员的平均身高。
所以为了方便后面的数据分析,我们需要将数据进行拆分。
181.93593798236887
181.74372848007872
2.3 整理数据
关于整洁数据集的概念总结如下:
- 每个变量组成一个列
- 每次观测形成一排
- 每一种观测单元组成一张表
使用这种形式的数据集可以进行更简单的分析。因此,第一步是尝试将数据集清理为整洁的数据集。
我要做的第一步是把数据集分成不同的观测单位。因此,我将有单独的表(或数据框架):
- 球员
- 俱乐部
- 裁判
- 国家
- 二分体
2.3 切分数据集
代码:
import numpy as np
import pandas as pd
# 读取数据源
df = pd.read_csv("E:/file/redcard.csv.gz", compression='gzip')
# 球员数据集
player_index = 'playerShort'
player_cols = [#'player', # drop player name, we have unique identifier
'birthday',
'height',
'weight',
'position',
'photoID',
'rater1',
'rater2',
]
# 俱乐部数据集
club_index = 'club'
club_cols = ['leagueCountry']
# 裁判数据集
referee_index = 'refNum'
referee_cols = ['refCountry']
# 国家数据集
country_index = 'refCountry'
country_cols = ['Alpha_3', # rename this name of country
'meanIAT',
'nIAT',
'seIAT',
'meanExp',
'nExp',
'seExp',
]
# 比赛数据集
dyad_index = ['refNum', 'playerShort']
dyad_cols = ['games',
'victories',
'ties',
'defeats',
'goals',
'yellowCards',
'yellowReds',
'redCards',
]
# 找到球员相关的col,然后group by汇总基数
# 如果都是1 代表这些col与球员都是一对一关系的
#all_cols_unique_players = df.groupby('playerShort').agg({col:'nunique' for col in player_cols})
# print(all_cols_unique_players.head())
# print(all_cols_unique_players[all_cols_unique_players > 1].dropna().head())
# print(all_cols_unique_players[all_cols_unique_players > 1].dropna().shape[0] == 0)
def get_subgroup(dataframe, g_index, g_columns):
"""从数据集创建子表并运行快速唯一性测试的辅助函数"""
g = dataframe.groupby(g_index).agg({col: 'nunique' for col in g_columns})
if g[g > 1].dropna().shape[0] != 0:
print("Warning: you probably assumed this had all unique values but it doesn't.")
return dataframe.groupby(g_index).agg({col: 'max' for col in g_columns})
def save_subgroup(dataframe, g_index, subgroup_name, prefix='raw_'):
"""把拆分的数据写入csv文件保存"""
save_subgroup_filename = "".join([prefix, subgroup_name, ".csv.gz"])
dataframe.to_csv(save_subgroup_filename, compression='gzip', encoding='UTF-8')
test_df = pd.read_csv(save_subgroup_filename, compression='gzip', index_col=g_index, encoding='UTF-8')
if dataframe.equals(test_df):
print("Test-passed: we recover the equivalent subgroup dataframe.")
else:
print("Warning -- equivalence test!!! Double-check.")
players = get_subgroup(df, player_index, player_cols)
save_subgroup(players, player_index, "players")
clubs = get_subgroup(df, club_index, club_cols)
save_subgroup(clubs, club_index, "clubs", )
referees = get_subgroup(df, referee_index, referee_cols)
save_subgroup(referees, referee_index, "referees")
countries = get_subgroup(df, country_index, country_cols)
rename_columns = {'Alpha_3':'countryName', }
countries = countries.rename(columns=rename_columns)
save_subgroup(countries, country_index, "countries")
dyads = get_subgroup(df, g_index=dyad_index, g_columns=dyad_cols)
save_subgroup(dyads, dyad_index, "dyads")
测试记录:
因为第4个我们有对dataframe进行改名,所以会有一个warning
Test-passed: we recover the equivalent subgroup dataframe.
Test-passed: we recover the equivalent subgroup dataframe.
Test-passed: we recover the equivalent subgroup dataframe.
Warning -- equivalence test!!! Double-check.
Test-passed: we recover the equivalent subgroup dataframe.
三. EDA之空值处理
空值是非常影响我们模型最终的效果,我们一般会提前将空值进行处理,可以是删除,可以是给平均值,可以是给出现最多的值等。
3.1 使用missingno库查看空值
代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
players = load_subgroup("raw_players.csv.gz")
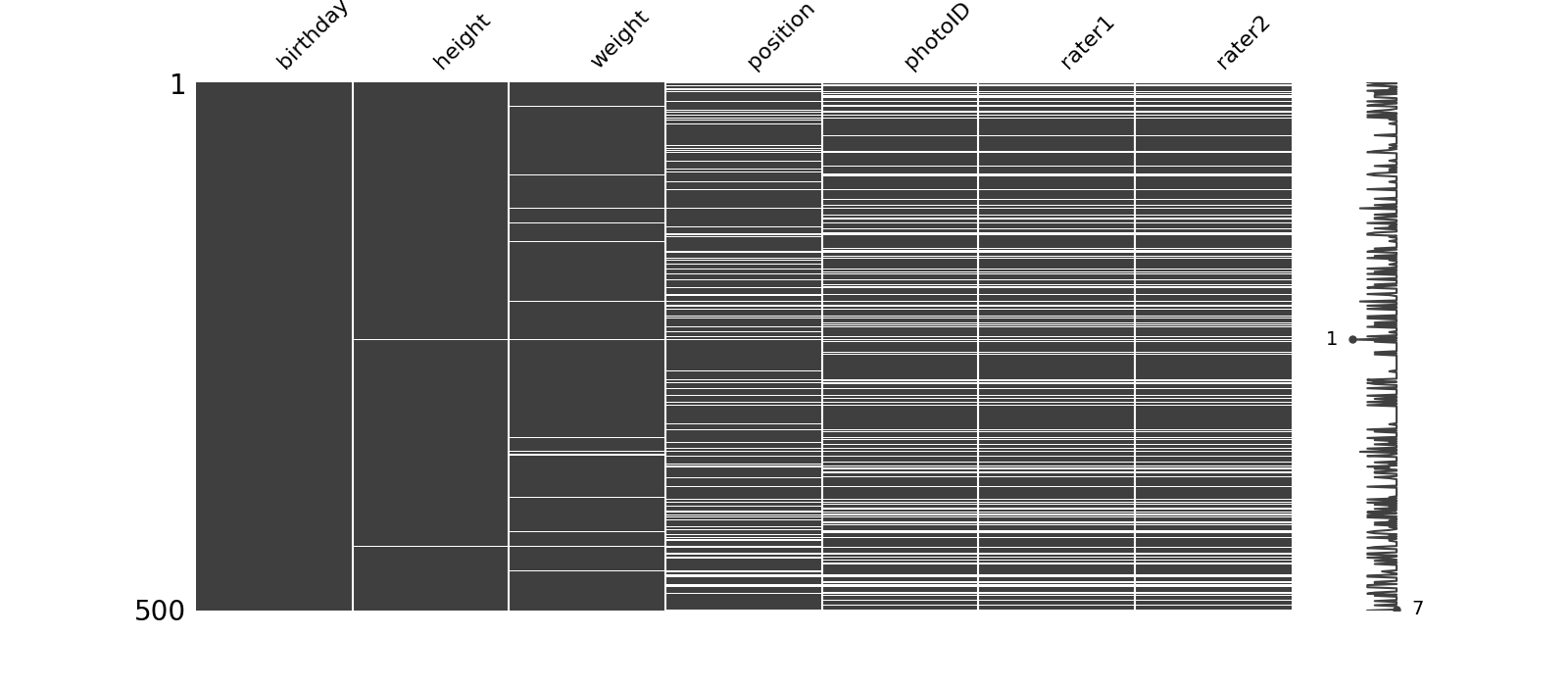
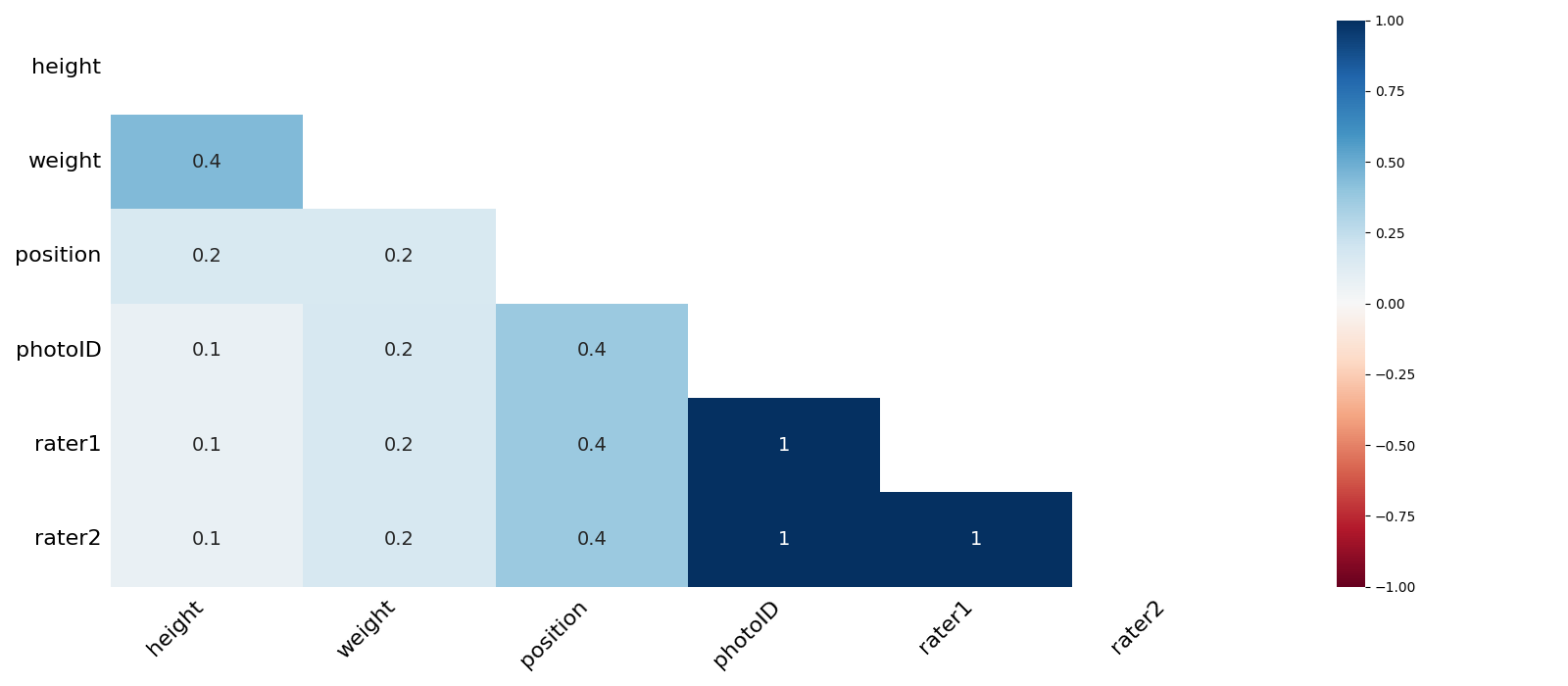
# 使用missingno库查看缺失值
msno.matrix(players.sample(500),
figsize=(16, 7),
width_ratios=(15, 1))
msno.heatmap(players.sample(500),
figsize=(16, 7),)
plt.show()
# 输出col的缺失值
print("All players:", len(players))
print("rater1 nulls:", len(players[(players.rater1.isnull())]))
print("rater2 nulls:", len(players[players.rater2.isnull()]))
print("Both nulls:", len(players[(players.rater1.isnull()) & (players.rater2.isnull())]))
测试记录:
All players: 2053
rater1 nulls: 468
rater2 nulls: 468
Both nulls: 468
3.2 删除缺失值后再才查看
代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
players = load_subgroup("raw_players.csv.gz")
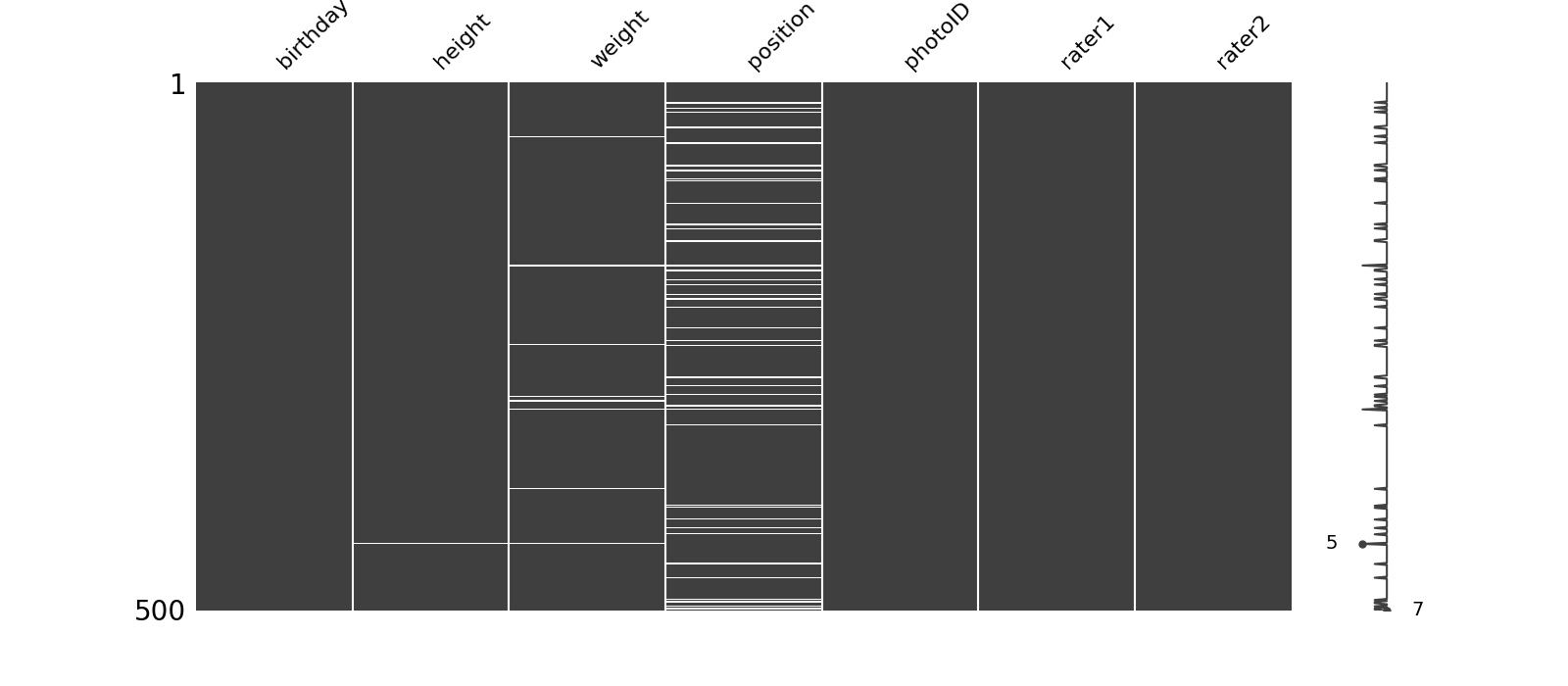
# 修改dataframe,选择rater1不为空的行
players = players[players.rater1.notnull()]
players.shape[0]
# 再次画图看效果
msno.matrix(players.sample(500),
figsize=(16, 7),
width_ratios=(15, 1))
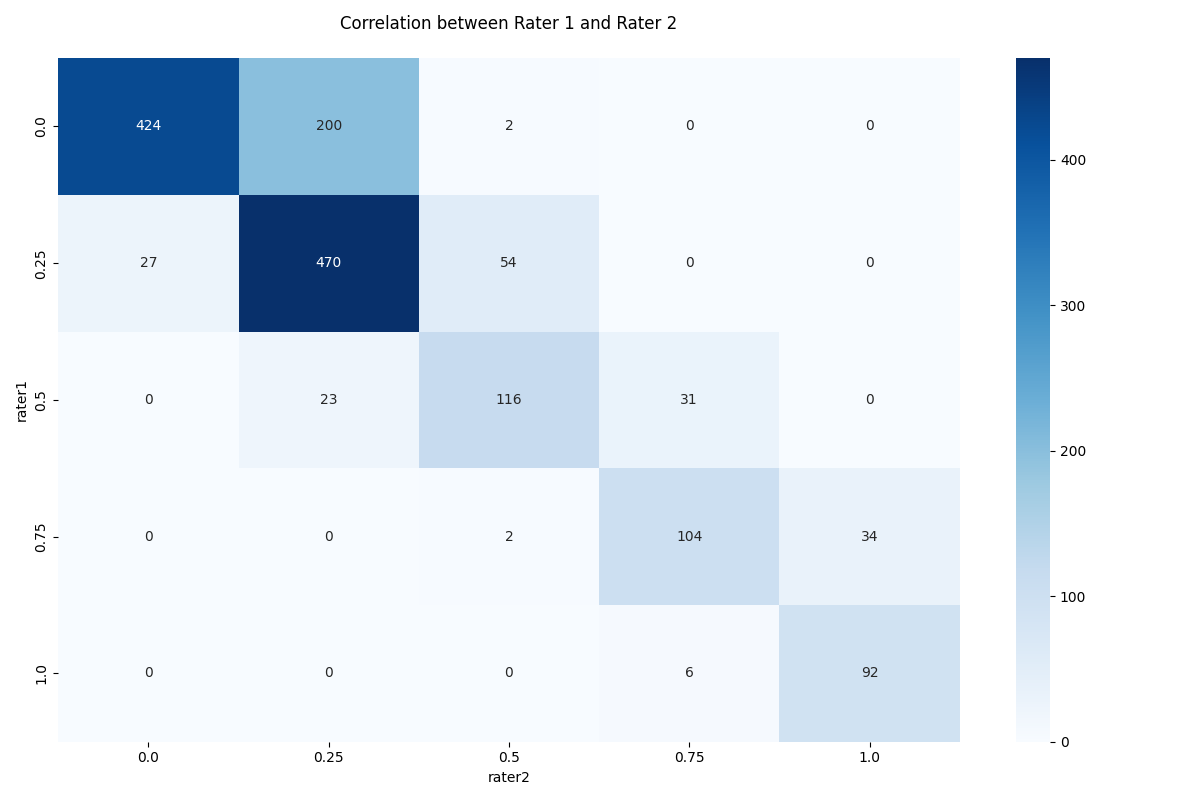
# 表格中剩下的每个玩家都有2种肤色评级——它们是否足够接近,可以合并在一起?
pd.crosstab(players.rater1, players.rater2)
fig, ax = plt.subplots(figsize=(12, 8))
sns.heatmap(pd.crosstab(players.rater1, players.rater2), cmap='Blues', annot=True, fmt='d', ax=ax)
ax.set_title("Correlation between Rater 1 and Rater 2\n")
fig.tight_layout()
plt.show()
测试记录:
四. EDA之特征值处理
很多原始的列是没办法直接当做特征值的,我们需要进行一系列的转换才可以。
4.1 新增特征值
rater1和rater2的含义类似,我们不清楚具体的差别,所以最好是两个列都作为我们的特征值,因为都是数值类型,我们可以新增一个特征值表示rater1和rater2的平均值。
代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
players = load_subgroup("raw_players.csv.gz")
# 修改dataframe,选择rater1不为空的行
players = players[players.rater1.notnull()]
# 给dataframe新增一个列
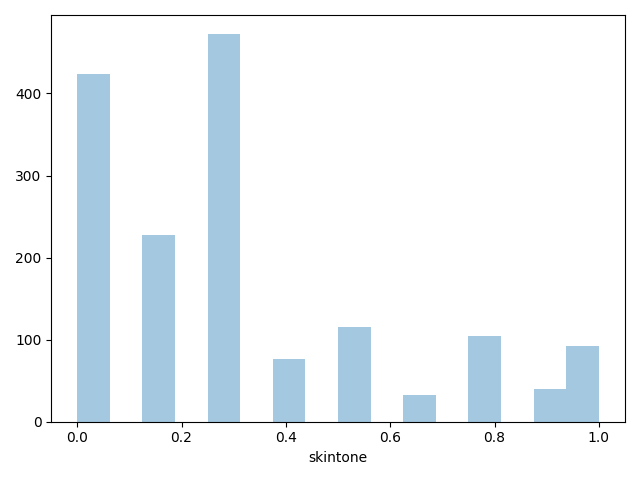
players['skintone'] = players[['rater1', 'rater2']].mean(axis=1)
sns.distplot(players.skintone, kde=False);
plt.show()
测试记录:
4.2 将特征值position进行分类
position这个特征值的分类较多,不利于我们进行模型训练,但是这个特征值比较重要,我们可以将分类进行缩减。
代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
players = load_subgroup("raw_players.csv.gz")
# 修改dataframe,选择rater1不为空的行
players = players[players.rater1.notnull()]
# 给dataframe新增一个列
players['skintone'] = players[['rater1', 'rater2']].mean(axis=1)
# 处理特征值 position
position_types = players.position.unique()
print(position_types)
defense = ['Center Back','Defensive Midfielder', 'Left Fullback', 'Right Fullback', ]
midfield = ['Right Midfielder', 'Center Midfielder', 'Left Midfielder',]
forward = ['Attacking Midfielder', 'Left Winger', 'Right Winger', 'Center Forward']
keeper = 'Goalkeeper'
# modifying dataframe -- adding the aggregated position categorical position_agg
players.loc[players['position'].isin(defense), 'position_agg'] = "Defense"
players.loc[players['position'].isin(midfield), 'position_agg'] = "Midfield"
players.loc[players['position'].isin(forward), 'position_agg'] = "Forward"
players.loc[players['position'].eq(keeper), 'position_agg'] = "Keeper"
# 处理特征值 position
MIDSIZE = (12, 8)
fig, ax = plt.subplots(figsize=MIDSIZE)
players.position.value_counts(dropna=False, ascending=True).plot(kind='barh', ax=ax)
ax.set_ylabel("Position")
ax.set_xlabel("Counts")
fig.tight_layout()
fig, ax = plt.subplots(figsize=MIDSIZE)
players['position_agg'].value_counts(dropna=False, ascending=True).plot(kind='barh', ax=ax)
ax.set_ylabel("position_agg")
ax.set_xlabel("Counts")
fig.tight_layout()
plt.show()
测试记录:
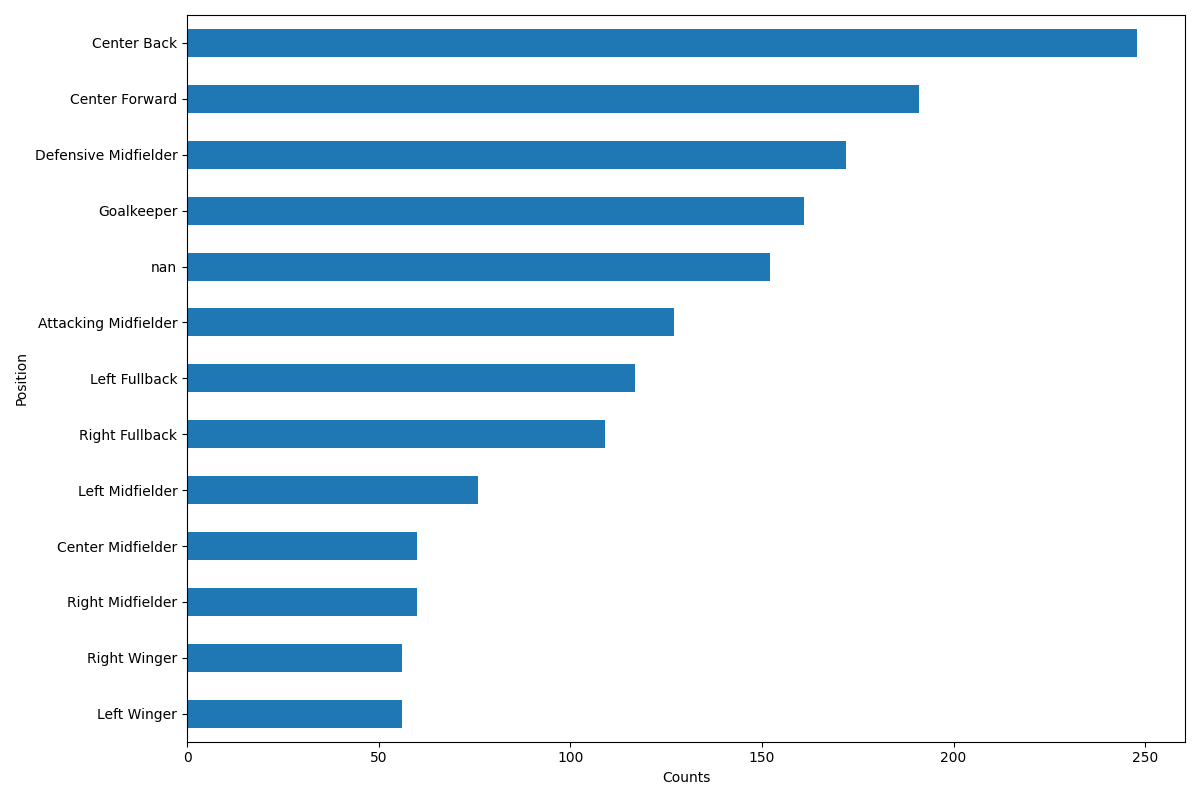
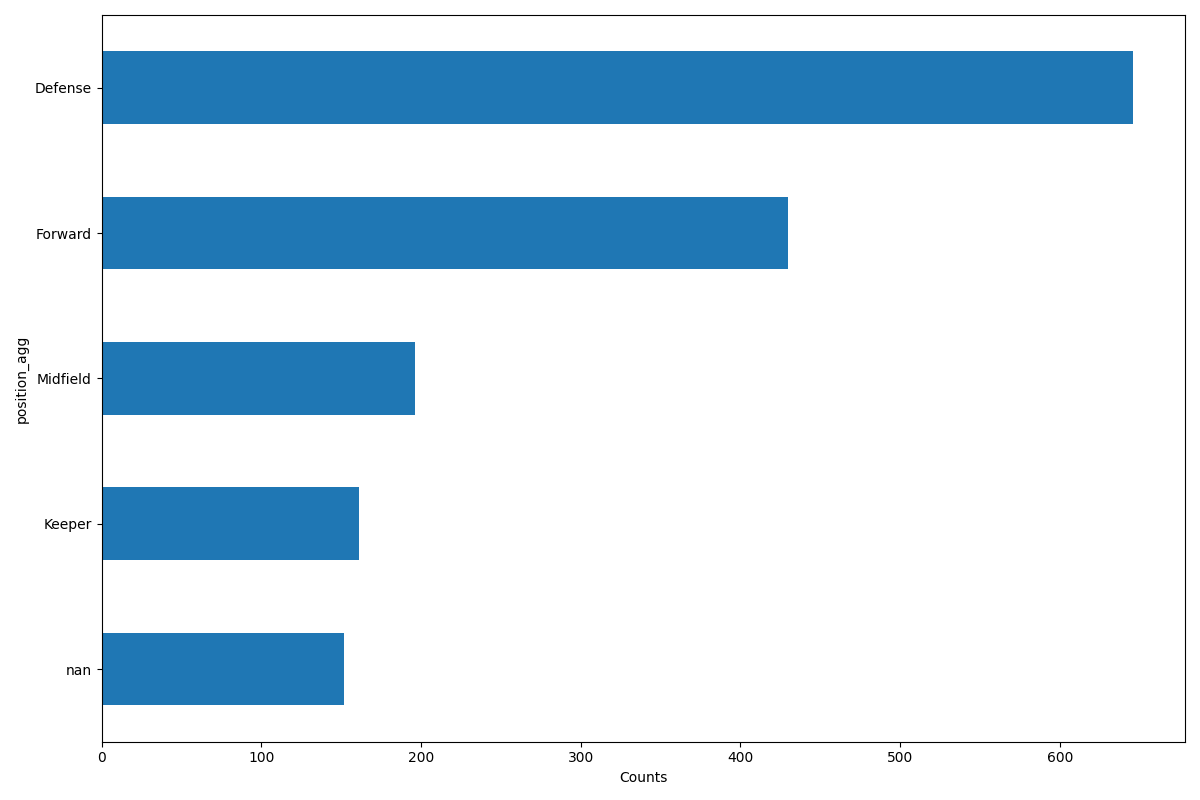
4.3 将特征值height和weight也进行分类
代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
from pandas.plotting import scatter_matrix
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
players = load_subgroup("raw_players.csv.gz")
# 修改dataframe,选择rater1不为空的行
players = players[players.rater1.notnull()]
# 给dataframe新增一个列
players['skintone'] = players[['rater1', 'rater2']].mean(axis=1)
# 处理特征值 position
position_types = players.position.unique()
print(position_types)
defense = ['Center Back','Defensive Midfielder', 'Left Fullback', 'Right Fullback', ]
midfield = ['Right Midfielder', 'Center Midfielder', 'Left Midfielder',]
forward = ['Attacking Midfielder', 'Left Winger', 'Right Winger', 'Center Forward']
keeper = 'Goalkeeper'
# modifying dataframe -- adding the aggregated position categorical position_agg
players.loc[players['position'].isin(defense), 'position_agg'] = "Defense"
players.loc[players['position'].isin(midfield), 'position_agg'] = "Midfield"
players.loc[players['position'].isin(forward), 'position_agg'] = "Forward"
players.loc[players['position'].eq(keeper), 'position_agg'] = "Keeper"
fig, ax = plt.subplots(figsize=(10, 10))
scatter_matrix(players[['height', 'weight', 'skintone']], alpha=0.2, diagonal='hist', ax=ax);
MIDSIZE = (12, 8)
fig, ax = plt.subplots(figsize=MIDSIZE)
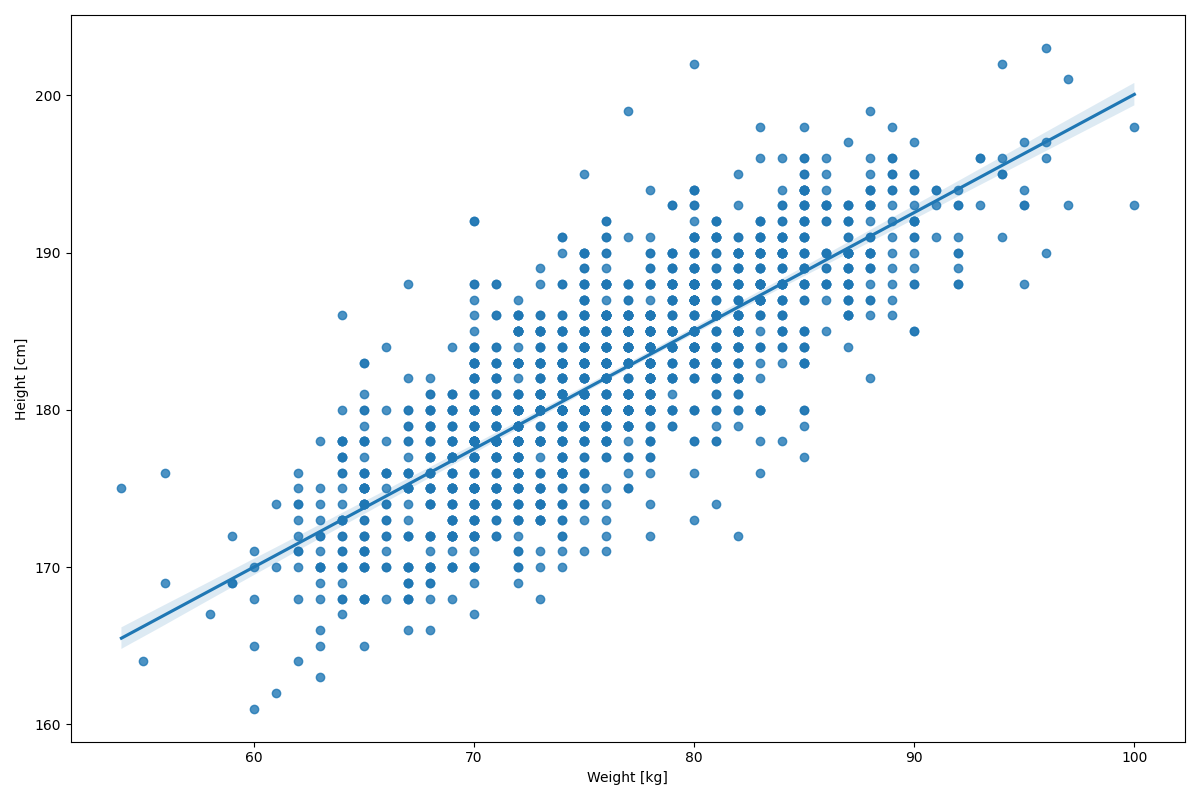
sns.regplot('weight', 'height', data=players, ax=ax)
ax.set_ylabel("Height [cm]")
ax.set_xlabel("Weight [kg]")
fig.tight_layout()
plt.show()
# 身高和体重列也进行划分
weight_categories = ["vlow_weight",
"low_weight",
"mid_weight",
"high_weight",
"vhigh_weight",
]
players['weightclass'] = pd.qcut(players['weight'],
len(weight_categories),
weight_categories)
height_categories = ["vlow_height",
"low_height",
"mid_height",
"high_height",
"vhigh_height",
]
players['heightclass'] = pd.qcut(players['height'],
len(height_categories),
height_categories)
players['skintoneclass'] = pd.qcut(players['skintone'], 3)
测试记录:
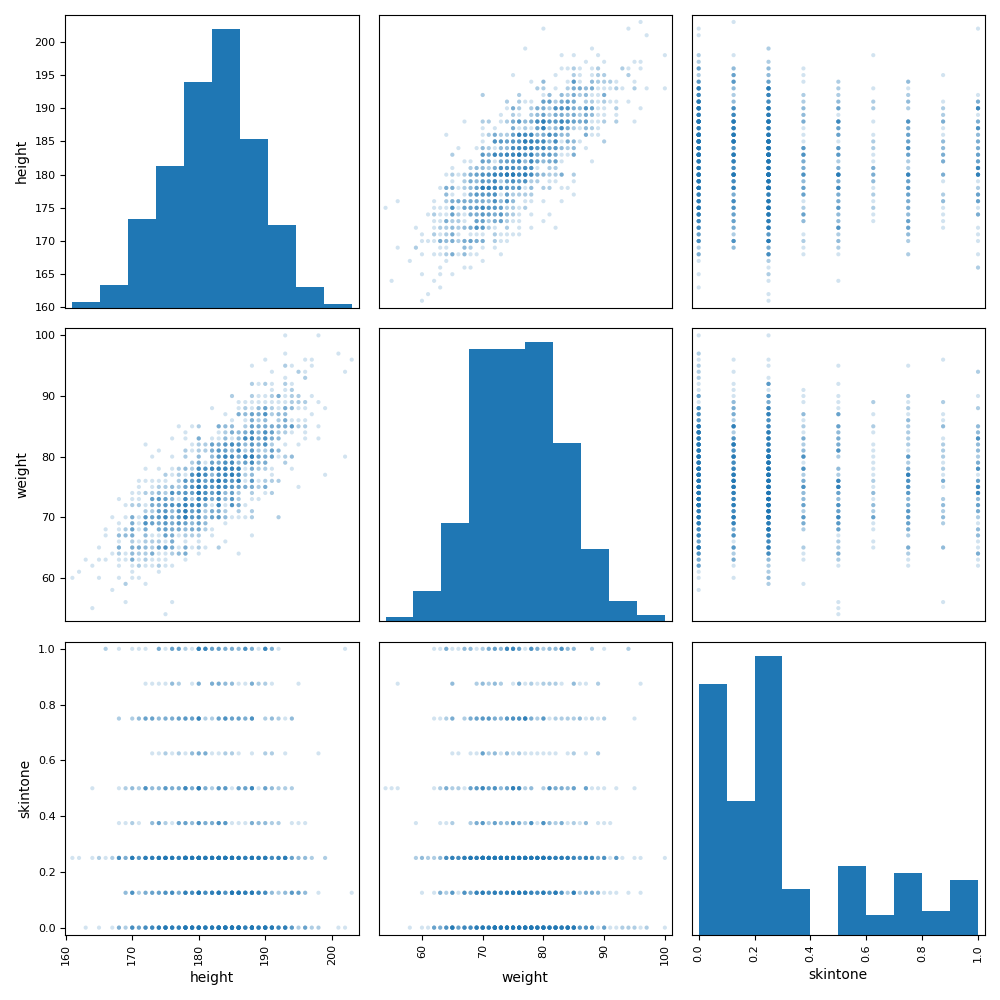
五. Pandas profiling库
5.1 Pandas profiling库初尝试
Pandas profiling库是一个大神写的,可以生成一个初步的报告,省去了数据清洗的诸多时间。
代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
from pandas.plotting import scatter_matrix
from pandas_profiling import ProfileReport
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
players = load_subgroup("raw_players.csv.gz")
profile = ProfileReport(players, title="Pandas Profiling Report")
profile.to_file("your_report.html")
测试记录:
Summarize dataset: 100%|██████████| 27/27 [00:03<00:00, 8.61it/s, Completed]
Generate report structure: 100%|██████████| 1/1 [00:01<00:00, 1.59s/it]
Render HTML: 100%|██████████| 1/1 [00:00<00:00, 1.84it/s]
Export report to file: 100%|██████████| 1/1 [00:00<00:00, 249.99it/s]
5.2 数据清洗过后的报告
清洗数据代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
from pandas.plotting import scatter_matrix
from pandas_profiling import ProfileReport
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
players = load_subgroup("raw_players.csv.gz")
# 修改dataframe,选择rater1不为空的行
players = players[players.rater1.notnull()]
players['birth_date'] = pd.to_datetime(players.birthday, format='%d.%m.%Y')
players['age_years'] = ((pd.to_datetime("2013-01-01") - players['birth_date']).dt.days)/365.25
# 新增特征值 rater1和rater2平均值
players['skintone'] = players[['rater1', 'rater2']].mean(axis=1)
# 处理特征值 position
position_types = players.position.unique()
print(position_types)
defense = ['Center Back','Defensive Midfielder', 'Left Fullback', 'Right Fullback', ]
midfield = ['Right Midfielder', 'Center Midfielder', 'Left Midfielder',]
forward = ['Attacking Midfielder', 'Left Winger', 'Right Winger', 'Center Forward']
keeper = 'Goalkeeper'
players.loc[players['position'].isin(defense), 'position_agg'] = "Defense"
players.loc[players['position'].isin(midfield), 'position_agg'] = "Midfield"
players.loc[players['position'].isin(forward), 'position_agg'] = "Forward"
players.loc[players['position'].eq(keeper), 'position_agg'] = "Keeper"
# 身高和体重列也进行划分
weight_categories = ["vlow_weight",
"low_weight",
"mid_weight",
"high_weight",
"vhigh_weight",
]
players['weightclass'] = pd.qcut(players['weight'],
len(weight_categories),
weight_categories)
height_categories = ["vlow_height",
"low_height",
"mid_height",
"high_height",
"vhigh_height",
]
players['heightclass'] = pd.qcut(players['height'],
len(height_categories),
height_categories)
players['skintoneclass'] = pd.qcut(players['skintone'], 3)
# 将处理过后的文件写入到csv
players.to_csv("cleaned_players.csv.gz", compression='gzip')
生成报告代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
from pandas.plotting import scatter_matrix
from pandas_profiling import ProfileReport
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
players = load_subgroup("cleaned_players.csv.gz")
profile = ProfileReport(players, title="Pandas Profiling Report")
profile.to_file("your_report.html")
测试记录:
六. 聚合数据
最开始我们把一个聚合的表拆分成了不同的子表,现在不同的子表的数据我们需要部分聚合生成新的表格,便可更好的分析出数据中的规律。
6.1 初步聚合数据
代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
from pandas.plotting import scatter_matrix
from pandas_profiling import ProfileReport
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
clean_players = load_subgroup("cleaned_players.csv.gz")
players = load_subgroup("raw_players.csv.gz", )
countries = load_subgroup("raw_countries.csv.gz")
referees = load_subgroup("raw_referees.csv.gz")
agg_dyads = pd.read_csv("raw_dyads.csv.gz", compression='gzip', index_col=[0, 1])
# 判断比赛数目是否相等
all(agg_dyads['games'] == agg_dyads.victories + agg_dyads.ties + agg_dyads.defeats)
# 严格意思上的红牌数
agg_dyads['totalRedCards'] = agg_dyads['yellowReds'] + agg_dyads['redCards']
agg_dyads.rename(columns={'redCards': 'strictRedCards'}, inplace=True)
# 进行连接操作
player_dyad = (clean_players.merge(agg_dyads.reset_index().set_index('playerShort'),
left_index=True,
right_index=True))
clean_dyads = (agg_dyads.reset_index()[agg_dyads.reset_index()
.playerShort
.isin(set(clean_players.index))
]).set_index(['refNum', 'playerShort'])
print(agg_dyads.head())
print(player_dyad.head())
print(clean_dyads.head())
测试记录:
games victories ... strictRedCards totalRedCards
refNum playerShort ...
1 lucas-wilchez 1 0 ... 0 0
2 john-utaka 1 0 ... 0 0
3 abdon-prats 1 0 ... 0 0
pablo-mari 1 1 ... 0 0
ruben-pena 1 1 ... 0 0
[5 rows x 9 columns]
birthday height ... strictRedCards totalRedCards
playerShort ...
aaron-hughes 08.11.1979 182.0 ... 0 0
aaron-hughes 08.11.1979 182.0 ... 0 0
aaron-hughes 08.11.1979 182.0 ... 0 0
aaron-hughes 08.11.1979 182.0 ... 0 0
aaron-hughes 08.11.1979 182.0 ... 0 0
[5 rows x 24 columns]
games victories ... strictRedCards totalRedCards
refNum playerShort ...
1 lucas-wilchez 1 0 ... 0 0
2 john-utaka 1 0 ... 0 0
4 aaron-hughes 1 0 ... 0 0
aleksandar-kolarov 1 1 ... 0 0
alexander-tettey 1 0 ... 0 0
[5 rows x 9 columns]
5.2 聚合后将数据关联起来
代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
from pandas.plotting import scatter_matrix
from pandas_profiling import ProfileReport
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
clean_players = load_subgroup("cleaned_players.csv.gz")
players = load_subgroup("raw_players.csv.gz", )
countries = load_subgroup("raw_countries.csv.gz")
referees = load_subgroup("raw_referees.csv.gz")
agg_dyads = pd.read_csv("raw_dyads.csv.gz", compression='gzip', index_col=[0, 1])
# 判断比赛数目是否相等
all(agg_dyads['games'] == agg_dyads.victories + agg_dyads.ties + agg_dyads.defeats)
# 严格意思上的红牌数
agg_dyads['totalRedCards'] = agg_dyads['yellowReds'] + agg_dyads['redCards']
agg_dyads.rename(columns={'redCards': 'strictRedCards'}, inplace=True)
# 进行连接操作
player_dyad = (clean_players.merge(agg_dyads.reset_index().set_index('playerShort'),
left_index=True,
right_index=True))
clean_dyads = (agg_dyads.reset_index()[agg_dyads.reset_index()
.playerShort
.isin(set(clean_players.index))
]).set_index(['refNum', 'playerShort'])
# 目前,这两对是一个聚合指标,总结了特定裁判和球员配对比赛的所有时间。
# 为了正确地处理数据,我们必须将数据分解成整齐的/长的格式。这意味着每一次比赛都是连续的。
colnames = ['games', 'totalRedCards']
j = 0
out = [0 for _ in range(sum(clean_dyads['games']))]
for index, row in clean_dyads.reset_index().iterrows():
n = row['games']
d = row['totalRedCards']
ref = row['refNum']
player = row['playerShort']
for _ in range(n):
row['totalRedCards'] = 1 if (d-_) > 0 else 0
rowlist=list([ref, player, row['totalRedCards']])
out[j] = rowlist
j += 1
tidy_dyads = pd.DataFrame(out, columns=['refNum', 'playerShort', 'redcard'],).set_index(['refNum', 'playerShort'])
print(tidy_dyads.redcard.sum())
print(clean_dyads.games.sum())
clean_referees = (referees.reset_index()[referees.reset_index()
.refNum.isin(tidy_dyads.reset_index().refNum
.unique())
]).set_index('refNum')
clean_countries = (countries.reset_index()[countries.reset_index()
.refCountry
.isin(clean_referees.refCountry
.unique())
].set_index('refCountry'))
# 将数据写入到文件
tidy_dyads.to_csv("cleaned_dyads.csv.gz", compression='gzip')
七. 可视化分析
代码:
import numpy as np
import pandas as pd
import missingno as msno
from matplotlib import pyplot as plt
import seaborn as sns
from pandas.plotting import scatter_matrix
from pandas_profiling import ProfileReport
# 读取数据源函数
def load_subgroup(filename, index_col=[0]):
return pd.read_csv(filename, compression='gzip', index_col=index_col)
clean_players = load_subgroup("cleaned_players.csv.gz")
players = load_subgroup("raw_players.csv.gz", )
countries = load_subgroup("raw_countries.csv.gz")
referees = load_subgroup("raw_referees.csv.gz")
agg_dyads = pd.read_csv("raw_dyads.csv.gz", compression='gzip', index_col=[0, 1])
# tidy_dyads = load_subgroup("cleaned_dyads.csv.gz")
tidy_dyads = pd.read_csv("cleaned_dyads.csv.gz", compression='gzip', index_col=[0, 1])
temp = tidy_dyads.reset_index().set_index('playerShort').merge(clean_players, left_index=True, right_index=True)
total_ref_games = tidy_dyads.groupby(level=0).size().sort_values(ascending=False)
total_player_games = tidy_dyads.groupby(level=1).size().sort_values(ascending=False)
total_ref_given = tidy_dyads.groupby(level=0).sum().sort_values(ascending=False,by='redcard')
total_player_received = tidy_dyads.groupby(level=1).sum().sort_values(ascending=False, by='redcard')
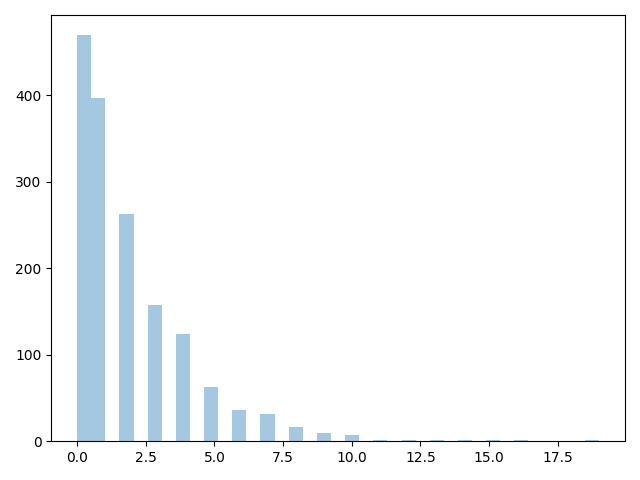
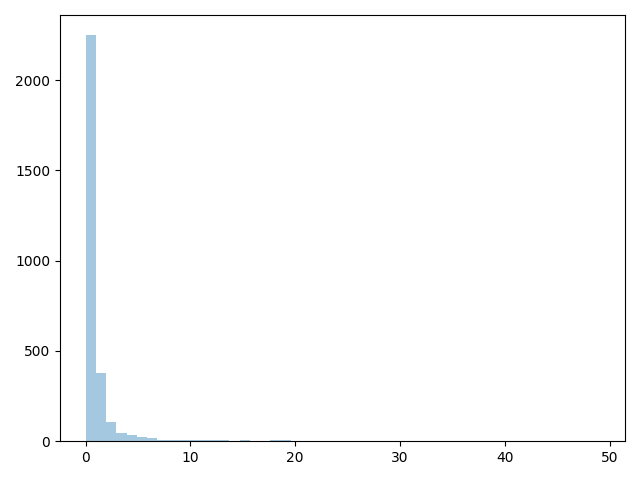
sns.distplot(total_player_received, kde=False);
plt.show()
sns.distplot(total_ref_given, kde=False);
plt.show()
# 运动员与比赛进行关联
player_ref_game = (tidy_dyads.reset_index()
.set_index('playerShort')
.merge(clean_players,
left_index=True,
right_index=True)
)
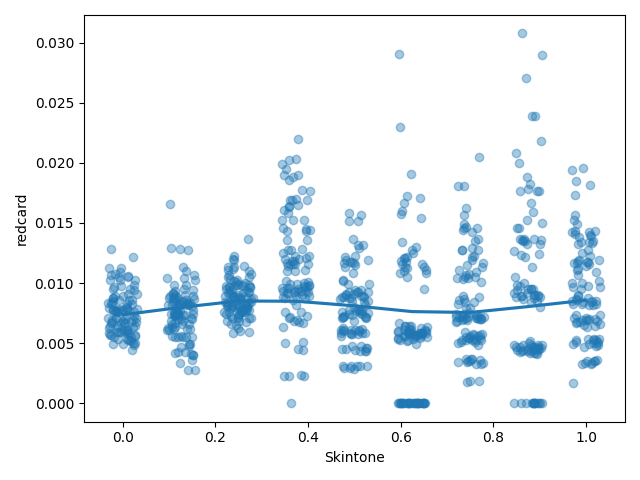
bootstrap = pd.concat([player_ref_game.sample(replace=True,
n=10000).groupby('skintone').mean()
for _ in range(100)])
ax = sns.regplot(bootstrap.index.values,
y='redcard',
data=bootstrap,
lowess=True,
scatter_kws={'alpha':0.4,},
x_jitter=(0.125 / 4.0))
ax.set_xlabel("Skintone");
plt.show()
测试记录:
从图中可以看到,肤色与红牌关系不大,我们的假设不成立。
参考:
- https://study.163.com/course/introduction.htm?courseId=1003590004#/courseDetail?tab=1

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









