







ChainMapper/ChainReducer实现原理及案例分析
ChainMapper/ChainReducer的实现原理
ChainMapper/ChainReducer主要为了解决线性链式Mapper而提出的。也就是说,在Map或者Reduce阶段存在多个Mapper,这些Mapper像linux管道一样,前一个Mapper的输出结果直接重定向到下一个Mapper的输入,形成一个流水线,形式类似于[MAP + REDUCE MAP*]。下图展示了一个典型的ChainMapper/ChainReducer的应用场景。
在Map阶段,数据依次经过Mapper1和Mapper2处理;在Reducer阶段,数据经过shuffle和sort排序后,交给对应的Reduce处理,但Reducer处理之后还可以交给其它的Mapper进行处理,最终产生的结果写入到hdfs输出目录上。
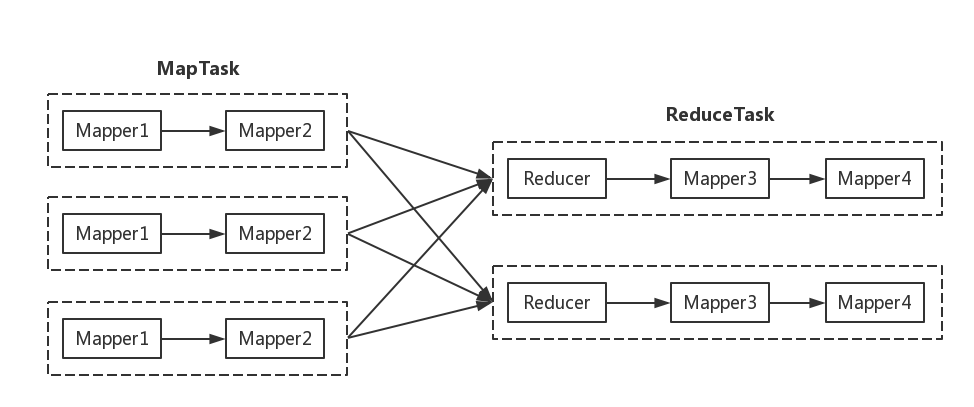
| 注意:对于任意一个MapReduce作业,Map和Reduce阶段可以有无限多个Mapper,但是Reducer只能有一个。 |
|---|
通过链式MapReducer模式可以有效的减少网络间传输数据的带宽,因为大量的计算基本都是在本地进行的。如果通过迭代作业的方式实现多个MapReduce作业组合的话就会在网络间传输大量的数据,这样会非常的耗时。
ChainMapper官方说明
ChainMapper类允许使用多个Map子类作为一个Map任务。
这些map子类的执行与liunx的管道命令十分相似,第一个map的输出会成为第二个map的输入,第二个map的输出也会变成第三个map的输入,以此类推,直到最后一个map的输出会变成整个mapTask的输出。
该特性的关键功能是链中的Mappers不需要知道它们是在链中执行的。这使具有可重用的专门的映射器可以组合起来,在单个任务中执行组合操作。
注意:在创建链式是每个Mapper的键/值的输出是链中下一个Mapper或Reducer的输入。它假定所有的映射器和链中的Reduce都使用匹配输出和输入键和值类,因为没有对链接代码进行转换。
使用方法
...
Job = Job.getInstance(conf);
Configuration mapAConf = new Configuration(false);
...
ChainMapper.addMapper(job, AMap.class, LongWritable.class, Text.class,
Text.class, Text.class, true, mapAConf);
Configuration mapBConf = new Configuration(false);
...
ChainMapper.addMapper(job, BMap.class, Text.class, Text.class,
LongWritable.class, Text.class, false, mapBConf);
...
job.waitForComplettion(true);
...addMapper函数的参数说明
static void addMapper(Job job, Class<? extends Mapper> klass,
Class<?> inputKeyClass, Class<?> inputValueClass,
Class<?> outputKeyClass, Class<?> outputValueClass,
Configuration mapperConf)
## 参数的含义如下
# 1. job
# 2. 此map的class
# 3. 此map的输入的key类型
# 4. 此map的输入的value类型
# 5. 此map的输出的key类型
# 6. 此map的输出的value类型
# 7. 此map的配置文件类confChainReducer官方说明
ChainReducer类允许多个map在reduce执行完之后执行在一个reducerTask中,
reducer的每一条输出,都被作为输入给ChainReducer类设置的第一个map,然后第一个map的输出作为第二个map的输入,以此类推,最后一个map的输出会作为整个reducerTask的输出,写到磁盘上。
使用方法
...
Job = new Job(conf);
....
Configuration reduceConf = new Configuration(false);
...
ChainReducer.setReducer(job, XReduce.class, LongWritable.class, Text.class,
Text.class, Text.class, true, reduceConf);
ChainReducer.addMapper(job, CMap.class, Text.class, Text.class,
LongWritable.class, Text.class, false, null);
ChainReducer.addMapper(job, DMap.class, LongWritable.class, Text.class,
LongWritable.class, LongWritable.class, true, null);
...
job.waitForCompletion(true);
...setReducer函数的参数说明
static void setReducer(Job job, Class<? extends Reducer> klass,
Class<?> inputKeyClass, Class<?> inputValueClass,
Class<?> outputKeyClass, Class<?> outputValueClass,
Configuration reducerConf)
## 参数的含义如下
# 1. job
# 2. 此reducer的class
# 3. 此reducer的输入的key类型
# 4. 此reducer的输入的value类型
# 5. 此reducer的输出的key类型
# 6. 此reducer的输出的value类型
# 7. 此reducer的配置文件类conf案例
案例描述
统计出一篇文章的高频词汇(只收集出现次数大于3的单词),去除谓词,并且过滤掉敏感词汇。
实现方法
在MapTask中有三个子Mapper,分别命名为M1,M2,M3,在ReduceTask阶段有一个Reduce命名为R1和一个Mpaaer命名为RM1。
MapTask阶段
M1负责将文本内容按行切分每个单词,M2负责将M1输出的单词进行谓词过滤,M3将M2输出的内容进行敏感词过滤。
ReduceTask阶段
Reduce过程中R1负责将shuffle阶段中的单词进行统计,统计好之后将结果交给RM1处理,RM1主要是将单词数量大于5的单词进行输出。
上述方法只是为了展示ChainMapper/ReducerMapper的使用过程,所以观者勿喷。
代码
Mapper1
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class Mapper1 extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
System.out.println("Mapper1 setup===========");
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
System.out.println("map1===========" + value.toString());
String line = value.toString() ;
String[] strArr = line.split(" ") ;
for (String w: strArr) {
context.write(new Text(w), new IntWritable(1));
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
System.out.println("Mapper1 cleanup===========");
}
}Mapper2
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 该Mapper是用于过滤谓词,但是过滤单词不是本文的关键,所以为了演示方便
* 这里只过滤一个单词‘of’
*/
public class Mapper2 extends Mapper<Text, IntWritable, Text, IntWritable> {
protected void setup(Context context) throws IOException, InterruptedException {
System.out.println("Mapper2 setup===========");
}
@Override
protected void map(Text key, IntWritable value, Context context)
throws IOException, InterruptedException {
System.out.println("map2==================" + key.toString() + ":" + value.toString());
//过滤单词'of'
if (! key.toString().equals("of")){
context.write(key, value);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
System.out.println("Mapper2 cleanup===========");
}
}Mapper3
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 该Mapper是用于过滤敏感词汇,但是过滤单词不是本文的关键,所以为了演示方便
* 这里只过滤一个单词‘xxx’
*/
public class Mapper3 extends Mapper<Text, IntWritable, Text, IntWritable> {
protected void setup(Context context) throws IOException, InterruptedException {
System.out.println("Mapper3 setup===========");
}
@Override
protected void map(Text key, IntWritable value, Context context)
throws IOException, InterruptedException {
System.out.println("map3==================" + key.toString() + ":" + value.toString());
//过滤单词'google'
if (! key.toString().equals("xxx")){
context.write(key, value);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
System.out.println("Mapper3 cleanup===========");
}
}Reducer1
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by yanzhe on 2017/8/18.
*/
public class Reducer1 extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
System.out.println("Reducer1 setup===========");
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0 ;
for (IntWritable iw: values) {
count += iw.get();
}
context.write(key, new IntWritable(count));
System.out.println("reduce=========" + key.toString() + ":" + count);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
System.out.println("Reducer1 cleanup===========");
}
}ReduceMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Created by yanzhe on 2017/8/18.
*/
public class ReducerMapper1 extends Mapper<Text, IntWritable, Text, IntWritable> {
@Override
protected void setup(Context context) throws IOException, InterruptedException {
System.out.println("ReducerMapper1 setup===========");
}
@Override
protected void map(Text key, IntWritable value, Context context)
throws IOException, InterruptedException {
if (value.get() > 5)
context.write(key, value);
System.out.println("reduceMap======" + key.toString() + ":" + value.toString());
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
System.out.println("ReducerMapper1 cleanup===========");
}
}App
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.chain.ChainMapper;
import org.apache.hadoop.mapreduce.lib.chain.ChainReducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Created by yanzhe on 2017/8/18.
*/
public class App {
public static void main(String[] args) throws Exception {
args = new String[]{"d:/java/mr/data/data.txt", "d:/java/mr/out"} ;
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf) ;
Path outPath = new Path(args[1]) ;
if (fs.exists(outPath)){
fs.delete(outPath,true) ;
}
Job job = Job.getInstance(conf) ;
ChainMapper.addMapper(job,Mapper1.class, LongWritable.class, Text.class, Text.class, IntWritable.class,job.getConfiguration());
ChainMapper.addMapper(job,Mapper2.class, Text.class,IntWritable.class, Text.class, IntWritable.class,job.getConfiguration());
ChainMapper.addMapper(job,Mapper3.class, Text.class,IntWritable.class, Text.class, IntWritable.class,job.getConfiguration());
ChainReducer.setReducer(job, Reducer1.class, Text.class, IntWritable.class, Text.class, IntWritable.class,job.getConfiguration());
ChainReducer.addMapper(job, ReducerMapper1.class, Text.class,
IntWritable.class, Text.class, IntWritable.class, job.getConfiguration());
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,outPath);
job.setNumReduceTasks(2);
job.setCombinerClass(Combiner1.class);
job.setPartitionerClass(MyPartitioner.class);
job.waitForCompletion(true) ;
}
}














 1932
1932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









