







参考文献
[1]. 陶晶. 基于聚类和密度的离群点检测方法[D]. 华南理工大学, 2014.
[2].王雪英. 离群点预处理及检测算法研究[D]. 西南交通大学, 2009.
[3].胡婷婷. 数据挖掘中的离群点检测算法研究[D]. 厦门大学, 2014.
[4]. 谭(美). 数据挖掘导论[M]. 人民邮电出版社, 2007.
[5]. 百度文库PPT(点击此处可进入该PPT页面)
离群点检测
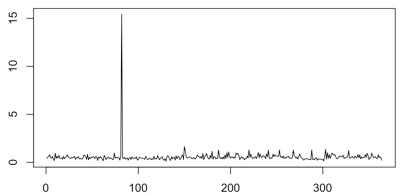
在大多数研究领域中,离群点也被称为异常值,在数据挖掘中,往往是要剔除掉这些数据,可是离群点的出现也是有一点的意义的。比如下图。该图是一个用户一年中的用水量情况,很明显的可以看出,有一天的数据是明显不正常的,该点是离群点。在我们研究他的用水规律时,该点是理当去除的。可是,它也提供给我们一个信息,在数据统计方式正确的情况下,那天的用水出现了不合理性(可能是用户忘记关水、水表异常等)。应当利用起这些异常。离群点的检测的意义也就存在了。
LOF算法
LOF算法(Local Outlier Factor,局部离群因子检测方法),是基于密度的离群点检测方法中一个比较有代表性的算法。该算法会给数据集中的每个点计算一个离群因子LOF,通过判断LOF是否接近于1来判定是否是离群因子。若LOF远大于1,则认为是离群因子,接近于1,则是正常点。为了叙述LOF算法,首先引入以下概念:
(1)对象p的k距离
对于正整数k,对象p的第k距离可记作k-distance(p)。在样本空间中,存在对象o,它与对象p之间的距离基座d(p,o)。如果满足以下两个条件,我们则认为k-
distance(p)=d(p,o)
:
1)在样本空间中,至少存在k个对象q,使得
d(p,q)<=d(d,o)
;
2)在样本空间中,至多存在k-1个对象q,使得
d(p,q)<d(p,o)
。
k−distance(p)=max|||p−o|||
显然易见,如果使用
k−distance(p)
来量化对象p的局部空间区域范围,那么对于对象密度较大的区域,
k−distance(p)
值较小,而对象密度较小的区域,
k−distance(p)
值较大。
(2)对象p的第
k
距离领域
已经对象p的第k距离,那么,与对象p之间距离小于等于
该领域其实是以p为中心,
k−distance(p)
为半径的区域内所有对象的集合(不包括p本身)。由于可能同时存在多个第k距离的数据,因此该集合至少包括k个对象。可以想象,离群度越大的对象的范围往往比较大,而离群度比较小的对象范围小。
(3)对象p相对于对象o的可达距离
公式:
reachdist(p,o)=max{k−distance(o),||p−o||}
也就是说,如果对象p远离对象o,则两者之间的可达距离就是它们之间的实际距离,但是如果它们足够近,则实际距离用o的k距离代替。
(4)局部可达密度
对象p的局部可达密度定义为p的k最近邻点的平均可达密度的倒数
lrdk(p)=|Nk(p)|∑o∈Nn(p)reachdistk(p,o)
(5)局部离群点因子
表征了称p是离群点的程度,定义如下:
LOFk(p)=∑o∈Nk(p)lrdk(o)lrdk(p)|Nk(p)|
如果对象p不是局部离群点,则LOF(p)接近于1。即p是局部离群点的程度较小,对象o的局部可达密度和对象p的局部可达密度相似,最后所得的LOF(p)值应该接近1。相反,p是局部离群点的程度越大,最后所得的LOF(p)值越高。通过这种方式就能在样本空间数据分布不均匀的情况下也可以准确发现离群点。
可以想象下,一个离群点p,它的 lrdk(o) 是远大于 lrdk(p) 的,通过特例很容易看出,这样该算法就可以很好的理解了
CLOF算法
华南理工大学陶晶在他的毕业论文中,提出基于K-means算法和LOF算法的CLOP算法。其实基于密度的聚类算法的引入在离群点检测算法中很常见。下面简单叙述下该算法。
基于聚类的离群点检测方法的基本思想是:在聚类过程中,将那些不属于任何簇的点作为离群点。然而,基于聚类的离群点检测方法主要目标是聚类,离群点只是聚类时产生的“副产物”。因此传统的基于聚类的离群点离群点检测方法检测精度比较低。
基于密度的LOF算法,能有效的检测数据集中的局部离群点和全局离群点,检测精度比较高。但是基于密度的LOF方法存在如下缺点,使其应用受到一定的限制。
LOF方法在检测离群点的过程中,遍历整个数据集以计算每个点的LOF值,使得算法运算速度慢。同时,由于数据正常点的数量一般远远多于离群点的数量,而LOF方法通过比较所有数据点的LOF值判断离群程度,这产生了大量没必要的计算,造成时间成本太高,同时由于中间结果的存储而浪费空间资源。因此,假如能在计算离群因子前,剪枝一部分正常数据点,则可以提高LOF方法的计算效率。
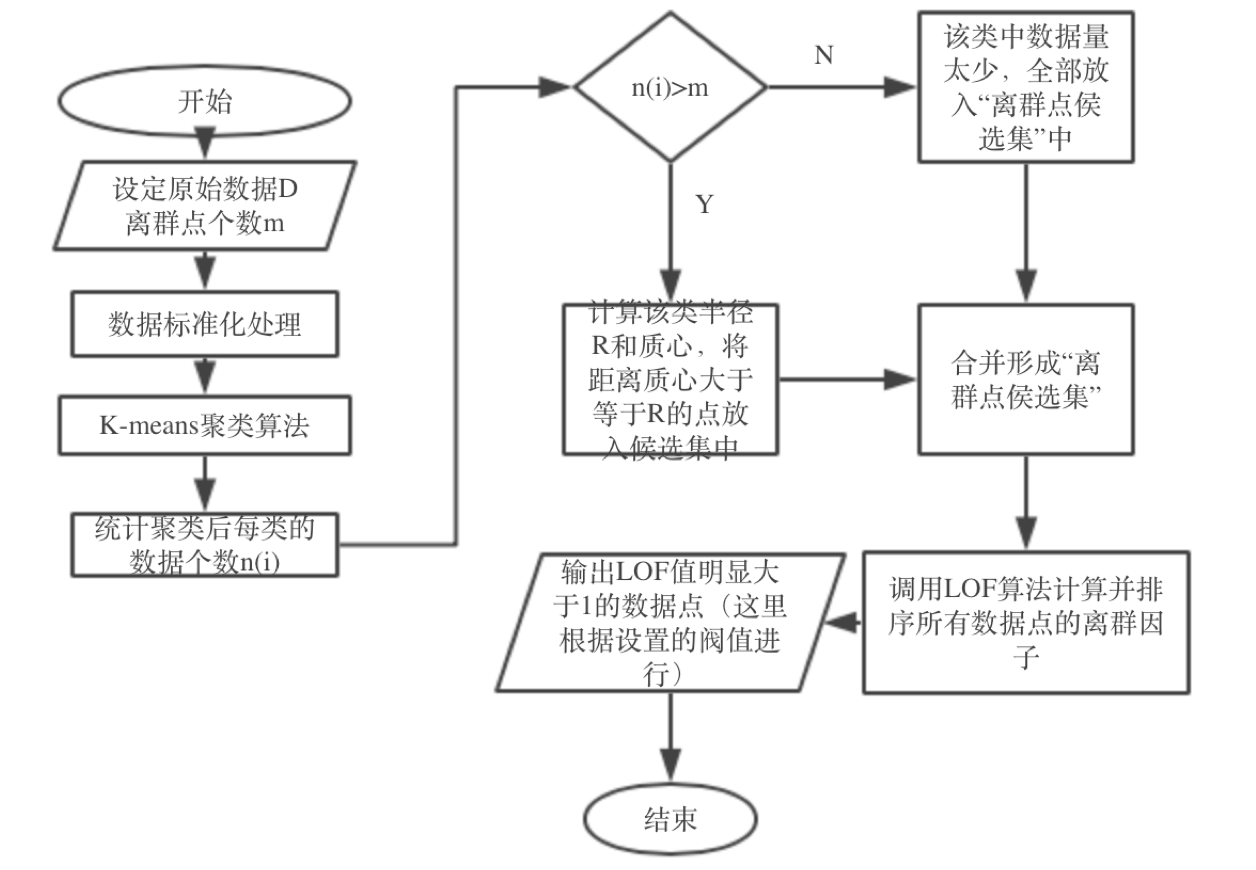
那么如何进行剪枝呢?考虑到K-means是一种效率很高的聚类的算法,CLOF算法利用了该聚类算法,对数据集进行剪枝,得到“离群点侯选集”,最后对该集合中的所有点执行LOF算法,从而判断是否是离群点。
综上所述,CLOF算法的第一阶段是调用k均值聚类算法,聚完类后,可以得到k个类的中心(质点),然后求出类中所有点到该质点距离的平均值,这个平均值记为半径R,针对类中所有点,若该点到质点的距离大于等于R,则将其放入离群点候选集中。该算法的流程图如下。
基于kNN算法的离群点检测
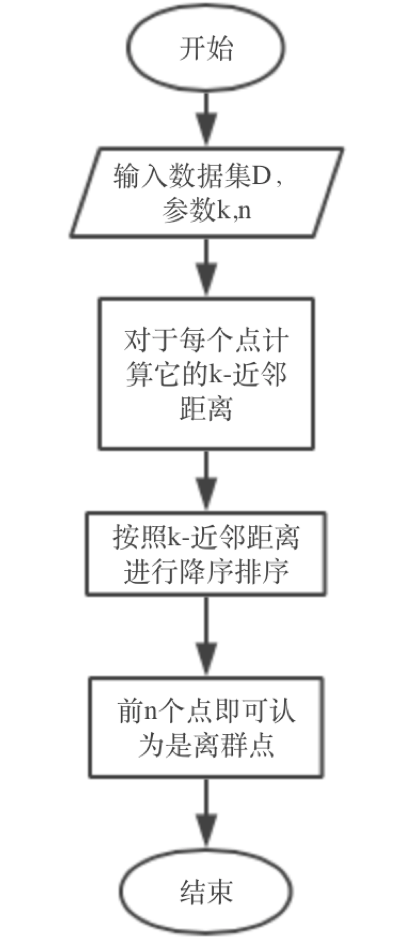
基于k-近邻平均距离(kNN)的离群点检测算法是一种比较简单的检测方法,k-近邻算法在机器学习的学习中已经学习过,这里不再对他的理论进行阐述。那么它是如何做离群点的检测呢?其算法流程如下。
针对数值数据来说,基于距离的离群点检测算法比较简单明了,是比较常用的算法。但是,它在大规模数据集中,存在计算量比较大,算法复杂度比较高的问题。为了解决这个问题,厦门大学硕士胡婷婷在她的硕士论文中提出了一种改进的基于距离的离群点检测算法(IDOD)。算法先进行预先的剪枝,去除部分非离群点,结合聚类技术,并且通过剪枝规则,降低在数据集中计算的时间复杂度。














 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









