







本文章来解析RxJava的线程切换原理。想想都激动了。
在不指定线程的情况下,它遵循的是线程不变原则,即:在哪个线程调用subscribe()方法,就在哪个线程生产事件,在哪个线程生产事件,就在哪个线程消费事件,如果需要切换线程,就需要用到调度器Scheduler.
在RxJava中,Scheduler相当于线程控制器,RxJava通过它来指定每一段代码应该运行在什么样的线程,RxJava已经内置了几个Scheduler,它们已经适合大多数的使用场景:
Scheduler.immediate():直接在当前线程运行,相当于不指定线程,这是默认的Scheduler
Scheduler.newThead():总是启用新线程,并在新线程执行操作。
Scheduler.io():I/O操作(读写文件,读写数据库,网络信息交互等)所使用的Scheduler。行为模式和newThead()差不多,区别在于io()的内部实现是用一个无数量上限的线程池,可以重用空闲的线程,因此多数情况下io()比newThead()更有效率,不要把计算工作放在io()中,可以避免创建不必要的线程。
Scheduler.computation():计算所使用的Scheduler。这个计算指的是CUP密集型计算,即不会被I/O等操作限制性能的操作,例如图形的计算,这个Scheduler使用固定的线程池,大小为CUP核数,不要把I/O操作放在computation()中,否则操作的等待时间会浪费CPU。
Android还有一个专用的AndroidSchedulers.mainThread().他指定的操作将在Android主线程运行。
有了这几个Scheduler,就可以使用subscribeOn()和observerOn()两个方法来对线程进行控制了。subscribeOn指定subscribe()所在的线程,即observable.OnSunscribe()被激活时所处的线程,或者叫做事件产生线程,observeOn()指定Subscribe所运行的线程,或者叫做事件消费线程。
那这个线程切换是怎么做到的呢?稍等一下,
先来看看变换这个东西吧,这也是一个令人鸡冻的东西,很吊的。
RxJava提供了对事件序列进行变换的支持,这是他的核心功能之一,也就是我们认为它比较好用的最大原因吧,所谓变换,就是将事件序列中的对象或者整个序列进行加工处理,转换成不同事件或者序列,先看看api吧
1,map()
Observable.just("images/logo.png") // 输入类型 String
.map(new Func1<String, Bitmap>() {
@Override
public Bitmap call(String filePath) { // 参数类型 String
return getBitmapFromPath(filePath); // 返回类型 Bitmap
}
})
.subscribe(new Action1<Bitmap>() {
@Override
public void call(Bitmap bitmap) { // 参数类型 Bitmap
showBitmap(bitmap);
}
});public interface Func1<T, R> extends Function {
R call(T t);
}我们现在追踪一下map()的源码:
public final <R> Observable<R> map(Func1<? super T, ? extends R> func) {
return lift(new OperatorMap<T, R>(func));
OperatorMap是Oprator的实现子类,而Oprator是Func1的子类,也是一个接口,要注意两个泛型 T 和 R 在OperatorMap和Operator里面的顺序是对换
public interface Operator<R, T> extends Func1<Subscriber<? super R>, Subscriber<? super T>> {
// cover for generics insanity
}public final class OperatorMap<T, R> implements Operator<R, T> {
private final Func1<? super T, ? extends R> transformer;
public OperatorMap(Func1<? super T, ? extends R> transformer) {
this.transformer = transformer;
}
@Override
public Subscriber<? super T> call(final Subscriber<? super R> o) {
return new Subscriber<T>(o) {
@Override
public void onCompleted() {
o.onCompleted();
}
@Override
public void onError(Throwable e) {
o.onError(e);
}
@Override
public void onNext(T t) {
try {
o.onNext(transformer.call(t));
} catch (Throwable e) {
Exceptions.throwIfFatal(e);
onError(OnErrorThrowable.addValueAsLastCause(e, t));
}
}
};
}
}
在这里大家不要去记住泛型T,泛型R啊什么的, 我们按顺序来区分它们,就记住第一个泛型对象,第二个泛型对象。上面我们说道Func1是个转换器, 那Operator也是个转换器咯,不过它不是把第一个泛型的对象转换成第二个泛型的对象, 而是将Susbcriber<第一个泛型>对象转换成Sbscriber<第二个泛型>对象。再根据OperatorMap<T, R> implements Operator<R, T> OperatorMap<R, T> 和Operator< T, R>的泛型顺序是相反的可知,OperatorMap<T, R >转换器的功能是将Subscriber<第二个泛型>对象转换成Subscriber<第一个泛型>对象。 再来看下lift方法
这才是精华所在, 先看一下源码:
public final <R> Observable<R> lift(final Operator<? extends R, ? super T> operator) {
return new Observable<R>(new OnSubscribe<R>() {
@Override
public void call(Subscriber<? super R> o) {
try {
Subscriber<? super T> st = hook.onLift(operator).call(o);
try {
// new Subscriber created and being subscribed with so 'onStart' it
st.onStart();
onSubscribe.call(st);
} catch (Throwable e) {
// localized capture of errors rather than it skipping all operators
// and ending up in the try/catch of the subscribe method which then
// prevents onErrorResumeNext and other similar approaches to error handling
if (e instanceof OnErrorNotImplementedException) {
throw (OnErrorNotImplementedException) e;
}
st.onError(e);
}
} catch (Throwable e) {
if (e instanceof OnErrorNotImplementedException) {
throw (OnErrorNotImplementedException) e;
}
// if the lift function failed all we can do is pass the error to the final Subscriber
// as we don't have the operator available to us
o.onError(e);
}
}
});
}这样看有点乱,来提炼一下核心代码:(这里把与性能,兼容性,扩展性等相关的代码先去掉了哈)
public <R> Observable<R> lift(Operator<? extends R, ? super T> operator) {
return Observable.create(new OnSubscribe<R>() {
@Override
public void call(Subscriber subscriber) {
Subscriber newSubscriber = operator.call(subscriber);
newSubscriber.onStart();
onSubscribe.call(newSubscriber);
}
});
}分析一下:在这个方法里,它生成了一个新的Observable并返回,而且,创建新Observable所用的参数OnSubscribe 的回调方法 call() 的实现竟然和前边看过的Observable.subscribe()一样,乍一看好像一样,其实并不一样,不一样的地方就在于这个call()方法中的onSubscribe所指代的对象不同:(一下可以有点绕,不过不会吐)
1)subscribe()这个方法中的onSubscribe指的是Observable中的onSubscribe对象,但是lift()以后,就呵呵呵了
2)当含有lift()时:
2.1 lift()创建了一个Observable后,加上原来之前的Observable就是有两个了
2.2 新Observable里新OnSubscribe加上之前原始的Observable中原始的OnSubscribe,也就有了两个OnSubscribe。
2.3 当调用经过lift()后的Observable的subscribe()的时候,使用的是lift()所返回的新的Observable,于是他所触发的onSubscribe.call(subscriber),也是用的新Observable中的新onSubscribe,即lift()中生成的那个onSubscribe。
2.4 而这个新onSubscribe的call()中的onSubscribe就是指原始的Observable中原始的onSubscribe,在这个call方法里,新onSubscribe利用operator.call(subscriber)生成了一个新的subscriber(operator就是在这里通过自己的call()方法将新subscriber和原始的subscriber进行关联,并插入自己的变换代码以实现变换),然后利用这个newSubscriber向原始的Observable进行订阅。
这样就实现了lift()原理,有一点像代理机制,通过事件拦截和处理 实现事件序列的变换。
概括一下:在Observable执行了lift(operator)方法以后,会返回一个新的Observable,这个新的Observable会像一个代理一样,负责接收原始的Observable发出的事件,并在处理后发送给Subscriber.
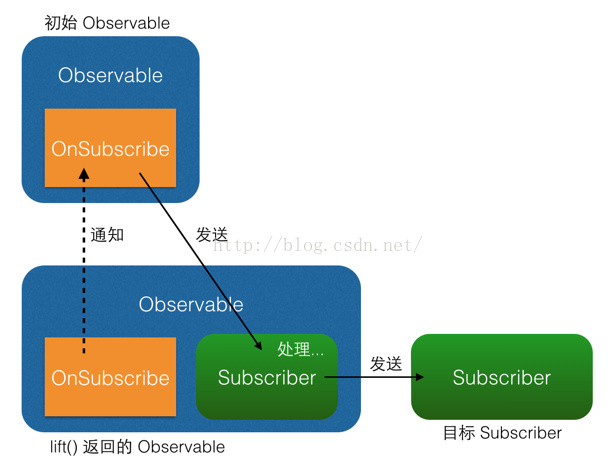
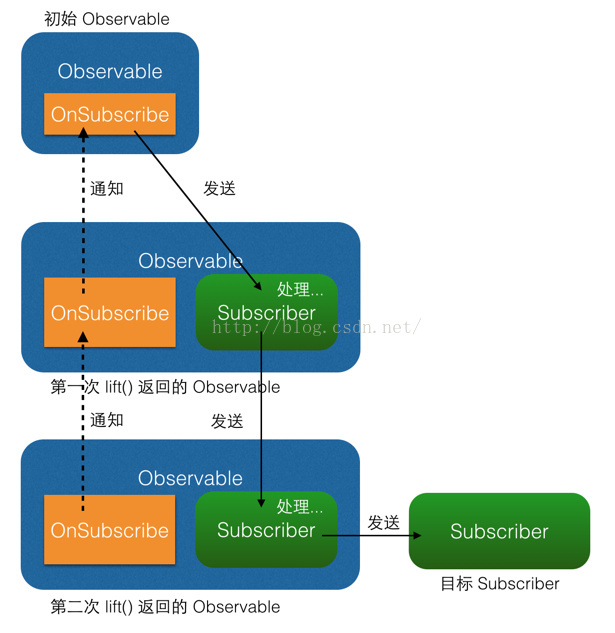
多次lift()之后同样的道理:
举个栗子吧,看看Operator 的实现:将事件中的Integer对象转换成String对象
observable.lift(new Observable.Operator<String, Integer>() {
@Override
public Subscriber<? super Integer> call(final Subscriber<? super String> subscriber) {
// 将事件序列中的 Integer 对象转换为 String 对象
return new Subscriber<Integer>() {
@Override
public void onNext(Integer integer) {
subscriber.onNext("" + integer);
}
@Override
public void onCompleted() {
subscriber.onCompleted();
}
@Override
public void onError(Throwable e) {
subscriber.onError(e);
}
};
}
});RxJava不建议开发者自定义Operator 来直接使用lift(),而是建议尽量使用已经有的lift()包装的方法(如map () flatMap()等)进行组合来实现需求,因为直接使用lift()非常容易发生一些难以发现的错误。
这里大家可能理解不彻底,我们再用另一张图的方式来来看看
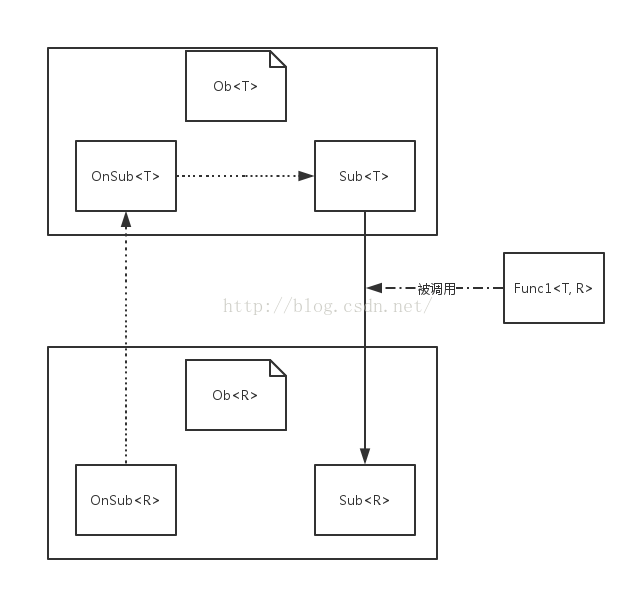
上面的Ob<T>图我们已经见过了,下面的Ob<R>就是lift创建并返回的,从lift代码中我们知道Observable<R>中的OnSubscribe<R>对象的call(Subscriber<R> subscriber)方法会调用原始OnSubscribe<T>对象的call(Subscriber<T> subscriber)方法。在简单domo中,Subscriber<T>对象是我们创建并调用Observable<T>的subscribe方法传递进去的,那这里的Subscriber<T>是哪来的呢。答案就是OperatorMap的call方法,该call方法会将一个Subscriber<R>对象转换成Subscriber<T>对象。 新创建的Subscriber<T>对象的onNext, onError或者onComplete方法都会调用Subscriber<R>的相应方法。这也是上图中右边的由Sub<T>指向Sub<R>的表示意思。我们调用map方法时需要传入的Func1对象的call方法也是在Subscriber<T>的onNext方法中被调用。 那这个Subscriber<R>对象自然就是我们在代码实例化并通过subscribe方法传递给新的Observable<R>对象的参数咯。这里说下图中的虚线和实线的意思,虚线表示OnSubscribe对象的call方法调用, 实线表示Subscriber对象的onNext, onError或者onComplete方法的调用。
2, flatMap():这是一个非常有用但是也难以理解的变换,先来看这么一种需求:假设一个数据结构 学生,现在需要打印出一组学生的名字,实现方式比较简单:
Student[] students = ...;
Subscriber<String> subscriber = new Subscriber<String>() {
@Override
public void onNext(String name) {
Log.d(tag, name);
}
...
};
Observable.from(students)
.map(new Func1<Student, String>() {
@Override
public String call(Student student) {
return student.getName();
}
})
.subscribe(subscriber);Student[] students = ...;
Subscriber<Student> subscriber = new Subscriber<Student>() {
@Override
public void onNext(Student student) {
List<Course> courses = student.getCourses();
for (int i = 0; i < courses.size(); i++) {
Course course = courses.get(i);
Log.d(tag, course.getName());
}
}
...
};
Observable.from(students)
.subscribe(subscriber);Student[] students = ...;
Subscriber<Course> subscriber = new Subscriber<Course>() {
@Override
public void onNext(Course course) {
Log.d(tag, course.getName());
}
...
};
Observable.from(students)
.flatMap(new Func1<Student, Observable<Course>>() {
@Override
public Observable<Course> call(Student student) {
return Observable.from(student.getCourses());
}
})
.subscribe(subscriber);看一下这个flatMap()的实现
public final <R> Observable<R> flatMap(Func1<? super T, ? extends Observable<? extends R>> func) {
if (getClass() == ScalarSynchronousObservable.class) {
return ((ScalarSynchronousObservable<T>)this).scalarFlatMap(func);
}
return merge(map(func));
}分为了两种情况,我发现只有通过just方法才会创建ScalarSynchornousObservable对象,其他的都是直接new 一个Observable对象
先看第一种情况吧,ScalarSynchronousObservable.scalarFlatMap(func)的执行情况
public <R> Observable<R> scalarFlatMap(final Func1<? super T, ? extends Observable<? extends R>> func) {
return create(new OnSubscribe<R>() {
@Override
public void call(final Subscriber<? super R> child) {
Observable<? extends R> o = func.call(t);
if (o.getClass() == ScalarSynchronousObservable.class) {
child.onNext(((ScalarSynchronousObservable<? extends R>)o).t);
child.onCompleted();
} else {
o.unsafeSubscribe(new Subscriber<R>(child) {
@Override
public void onNext(R v) {
child.onNext(v);
}
@Override
public void onError(Throwable e) {
child.onError(e);
}
@Override
public void onCompleted() {
child.onCompleted();
}
});
}
}
});
}如果我们提供的Func1对象的call函数中创建Observable<R>对象的时候是调用Observable.just方法创建的,则if里面的条件成立,那么会执行
Observable<? extends R> o = func.call(t);
if (o.getClass() == ScalarSynchronousObservable.class) {
child.onNext(((ScalarSynchronousObservable<? extends R>)o).t);
child.onCompleted();
} 原始的Observable<T>已经没什么用了,它就当做一个提供数据T的容器,被Func1.call方法用来取数据Observable<T>.t。Func1.call方法将T对象转换成Observable<R>对象,该Obersvable<R>也没什么用,只是当做数据R的容器,被最后的Observable<R>里面的OnSubscrib<R>.call方法调用到,用来获取R数据对象并传递给Sub<R>.onNext(R r)方法。
ok, 如果Func1.call方法里面提供的Observable<R>不是通过just创建的,那if条件就不成立,那代码就会走else里面的
Observable<? extends R> o = func.call(t);
o.unsafeSubscribe(new Subscriber<R>(child) {
@Override
public void onNext(R v) {
child.onNext(v);
}
@Override
public void onError(Throwable e) {
child.onError(e);
}
@Override
public void onCompleted() {
child.onCompleted();
}
}
因为我们上边代码是from创建的Observable,是一个普通的Observable,所以肯定是走第二个情况merge();很神奇,看到了map()方法。我们已经知道map方法里就是调用了一次lift()方法,
next
public final static <T> Observable<T> merge(Observable<? extends Observable<? extends T>> source) {
if (source.getClass() == ScalarSynchronousObservable.class) {
return ((ScalarSynchronousObservable<T>)source).scalarFlatMap((Func1)UtilityFunctions.identity());
}
return source.lift(OperatorMerge.<T>instance(false));
}代码将会执行source.lift方法。为什么不会执行上面if里面的代码?因为经过map函数调用生成的Ob<Ob<R>>不是ScalarSynchronousObservable类型的对象。
两次lift()也上个图吧:

问题的关键点是Sub<Ob<R>>是如何触发Sub<R>的事件的,即右下角的那条实线箭头是怎么来的。在map方法的分析中,我们知道决定Sub<Ob<R>>触发Sub<R>事件的代码在Operator中。在这里就是OperatorMerge的call方法。
@Override
public Subscriber<Observable<? extends T>> call(final Subscriber<? super T> child) {
MergeSubscriber<T> subscriber = new MergeSubscriber<T>(child, delayErrors, maxConcurrent);
MergeProducer<T> producer = new MergeProducer<T>(subscriber);
subscriber.producer = producer;
child.add(subscriber);
child.setProducer(producer);
return subscriber;
}
void emitLoop() {
// 删除掉大量的无关的代码
try {
final Subscriber<? super T> child = this.child;
for (;;) {
Queue<Object> svq = queue;
long r = producer.get();
boolean unbounded = r == Long.MAX_VALUE;
if (svq != null) {
for (;;) {
while (r > 0) {
o = svq.poll();
T v = nl.getValue(o);
try {
child.onNext(v);
} catch (Throwable t) {
}
r--;
}
}
}
}
}catch (Exception e){
}
}通过这一系列的源码追踪,可以看到,flatMap()和map()有一个相同点:都是把传入的参数通过转化以后返回另一个对象,但是和map()不同的是,flatMap()中返回的是个Observable对象,并且这个Observable对象并不是直接被发送到Subscriber的回调方法中,flatMap()的原理是酱婶儿的:
1,使用传入的事件对象创建一个Observable对象
2,并不发送这个Observable,而是将它激活,于是他开始发送事件
3,每一个创建出来的Observable发送的事件,都被汇入同一个Obsercable,而这个Observable负责将将这些事件统一交给Subscribe的回调方法
这三个步骤把事件拆成了两级,通过一组新创建的Observable将初始的对象铺平,之后通过统一路劲分发下去。这个动作就是flat的意思
2,compose:对Observable整体的变换
除了lift()之外,Observable还有一个变换方法叫compose(Transformer),它和lift()的区别在于:lift()是针对事件项和事件序列的,而compose()是针对observable自身进行变换的,比如,假设程序中多个observable。他们都需要应用一组相同的lift()变换,
observable1
.lift1()
.lift2()
.lift3()
.lift4()
.subscribe(subscriber1);
observable2
.lift1()
.lift2()
.lift3()
.lift4()
.subscribe(subscriber2);
observable3
.lift1()
.lift2()
.lift3()
.lift4()
.subscribe(subscriber3);这样写感觉太low了,就算写一个专门的函数liftAll(Observable)来做这件事也不是很好,Observable都被一个函数包裹起来,感觉不太灵活了,这个时候compose可以登场了:
public class LiftAllTransformer implements Observable.Transformer<Integer, String> {
@Override
public Observable<String> call(Observable<Integer> observable) {
return observable
.lift1()
.lift2()
.lift3()
.lift4();
}
}
...
Transformer liftAll = new LiftAllTransformer();
observable1.compose(liftAll).subscribe(subscriber1);
observable2.compose(liftAll).subscribe(subscriber2);
observable3.compose(liftAll).subscribe(subscriber3);public <R> Observable<R> compose(Transformer<? super T, ? extends R> transformer) {
return ((Transformer<T, R>) transformer).call(this);
}而Trasformer也是一个接口,Func1的子接口
public interface Transformer<T, R> extends Func1<Observable<T>, Observable<R>> {
// cover for generics insanity
}














 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









