







 本文介绍了在检索中如何使用VSM(Vector Space Model)进行相似度计算,重点讲述了从文档预处理到向量化表示的过程,并提供了Python实现的代码示例。通过VSM,文档被转化为向量形式,以便进行相似度比较。
本文介绍了在检索中如何使用VSM(Vector Space Model)进行相似度计算,重点讲述了从文档预处理到向量化表示的过程,并提供了Python实现的代码示例。通过VSM,文档被转化为向量形式,以便进行相似度比较。
- 简介
- 代码实现
- 总结
一.简介
在检索当中,主要涉及了两个核心问题:
I.相似度计算
II.索引的建立
索引建立参考链接:
这里我们重点讲解第一个问题
1.1整体流程如图:
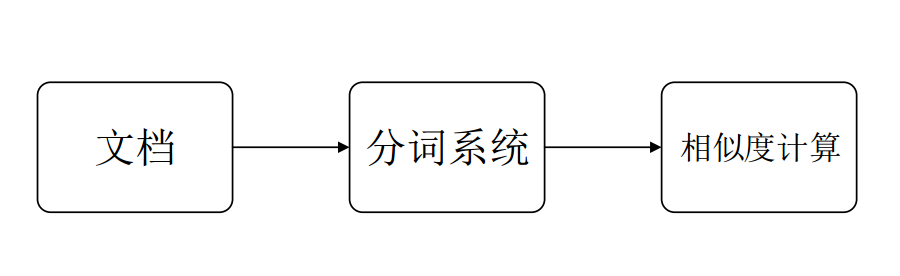
1.2在整个流程当中,第二步骤和第三步骤对于效果影响很多,故此很关键
相似度的vsm经典模型流程如图:

经过第三步骤处理后,文档在词典当中均有唯一的表示-表示为一个长向量的形式
第四步骤参考链接:
二.代码实现
# !usr/bin/python
# copyright(c) youfuwen
# Date:2016.03.26
# E-Mail:yfwen@bjtu.edu.cn
# first: cipintongji
import math
import ast
from collections import Counter
wordsCount=0#variable for wordsfrequency
def CountKeyByWen(fileName1):
global wordsCount
f1=open(fileName1,'r')
f2=open(fileName2,'r')
table={}
for lines in f1:
for line in lines.split(' '):
if line!=' ' and table.has_key(line):
table[line]+=1
wordsCount+=1
elif line!=' ':
wordsCount+=1
table[line]=1
dic = sorted(table.iteritems(),key= lambda asd:asd[1], reverse=True 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









