







一:简介
所谓的BitMap就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了bit为单位来存储数据,因此在存储空间方面,可以大大节省。
位图法它的做法是按照集合中最大元素max创建一个长度为max+1的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上1,如遇到 5就给新数组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这说明这次的数据肯定和以前的数据存在着重复。这种给新数组初始化时置零其后置一的做法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最大值即能事先给新数组定长的话效率还能提高一倍。
java中实现通过BitSet java.util.BitSet bitSet = new java.util.BitSet(10000000);
二:基本思想
我们用一个具体的例子来讲解,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用BitMap的方法来达到排序的目的。要表示8个数,我们就只需要8个bit(1Bytes)。
(1)首先我们开辟1字节(8bit)的空间,将这些空间的所有bit位都置为0,如下图:
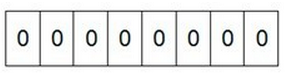
(2)然后遍历这5个元素,首先第1个元素是4,那么就把4对应的位置为1,因为是从零开始的,所以要把第5个位置为1(如下图):
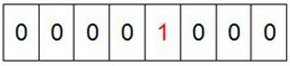
然后再处理第2个元素7,将第8个位置为1,,接着再处理第3个元素,一直到处理完所有元素,将相应的位置为1,这时候的内存的bit位的状态如下:
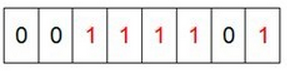
(3)然后我们现在遍历一遍bit区域,将该位是1的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。
算法思想比较简单,但关键是如何确定十进制的数映射到二进制bit位的map图。
三:Map映射
假设需要排序或者查找的总数N=10000000。
BitMap中1bit代表一个数字
1个int = 4Bytes = 4*8bit = 32 bit,那么N个数需要N/32 int空间。所以我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:
BitMap表为:
a[0] ---------> 0-31
a[1] ---------> 32-63
a[2] ---------> 64-95
a[3] ---------> 96-127
..........
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
申请一个int一维数组,那么可以当作为列为32位的二维数组。
a[0]
a[1]
a[2]
a[3]
a[i] ……………………………….
a[n]
例如:
十进制1 在a[0]中,位置如下图:
十进制31 在a[0]中,位置如下图:
十进制32 在a[1]中,位置如下图:
十进制33 在a[1]中,位置如下图:
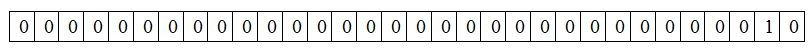



通过上图分析得出通过以下几步将十进制数如何转换为对应的bit位:
(1)求十进制数在对应数组a中的下标
十进制数0-31,对应在数组a[0]中,32-63对应在数组a[1]中,64-95对应在数组a[2]中………
分析得出:对于一个十进制数n,对应在数组a[n/32]中
例如n=11,那么 n/32=0,则11对应在数组a中的下标为0,n=32,那么n/32=1,则32对应在数组a中的下标为1,n = 106,那么n/32 = 3,则106对应数组a中的下标为3。
(2)求十进制数在对应数组a[i]中的下标
例如十进制数1在a[0]的下标为1,十进制数31在a[0]中下标为31,十进制数32在a[1]中下标为0。
在十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得在对应数组a[i]中的下标。
分析得出:对于一个十进制数n,对应在数组a[n/32][n%32]中
(3)移位
对于一个十进制数n,对应在数组a[n/32][n%32]中,但数组a毕竟不是一个二维数组,我们通过移位操作实现置1。
a[n/32] |= 1 << n % 32
移位操作:
a[n>>5] |= 1 << (n & 0x1F)
n & 0x1F 保留n的后五位 相当于 n % 32 求十进制数在数组a[i]中的下标
/*--------------------------------
* 日期:2015-02-07
* 作者:SJF0115
* 题目: BitMap
* 博客:
------------------------------------*/
#include <iostream>
#include <vector>
using namespace std;
#define N 1000000000
//申请内存的大小
int a[1 + N/32];
// 设置所在的bit位为1
void BitMap(int n){
// row = n / 32 求十进制数在数组a中的下标
int row = n >> 5;
// n & 0x1F 保留n的后五位
// 相当于 n % 32 求十进制数在数组a[i]中的下标
a[row] |= 1 << (n & 0x1F);
}
// 判断所在的bit为是否为1
bool Exits(int n){
int row = n >> 5;
return a[row] & ( 1 << (n & 0x1F));
}
void Show(int row){
cout<<"BitMap位图展示:"<<endl;
for(int i = 0;i < row;++i){
vector<int> vec;
int tmp = a[i];
for(int i = 0;i < 32;++i){
vec.push_back(tmp & 1);
tmp >>= 1;
}//for
cout<<"a["<<i<<"]"<<"->";
for(int i = vec.size()-1;i >= 0;--i){
cout<<vec[i]<<" ";
}//for
cout<<endl;
}//for
}
int main(){
int num[] = {1,5,30,32,64,56,159,120,21,17,35,45};
for(int i = 0;i < 12;++i){
BitMap(num[i]);
}//for
int row = 5;
Show(5);
/*if(Exits(n)){
cout<<"该数字已经存在"<<endl;
}//if
else{
cout<<"该数字不存在"<<endl;
}//else*/
return 0;
}

应用范围
可以运用在快速查找、去重、排序、压缩数据等。
扩展
Bloom filter可以看做是对BitMap的扩展
布隆过滤器具体参考:[算法系列之十]大数据量处理利器:布隆过滤器
具体应用
腾讯面试题:给20亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中并且所耗内存尽可能的少?
应用场景1:磁盘空闲块的管理
很多文件系统采用bitmap管理磁盘空闲块,如果该块是空闲的,标为0,已使用则标为1.
Ext3文件系统中使用位图来管理磁盘空闲块(空闲inode节点)。文件系统创建后,该文件系统拥有的块数以及inode节点数都是确定的,数据块区包含一系列连续的块(块号是连续的),于是可以用位图来标示数据块的分配状态(分配、未分配两种状态,1bit即可标示)。
如下图,假设ext3的数据块从128开始,一直到1024,则需要1024-128 = 996bit = 128字节的位图空间。如下图,第1bit标示128号块已经被分配,第2bit标示129号块未被分配,依次类推。使用位图的高效性在于:1bit标示状态,节省存储空间,通过关键字来定位位图(偏移是固定的),效率高。
| 1 | 0 | 1 | 1 | …. |
|
应用场景2:区域服务器路由
腾讯的QQ号用一个数字标示,范围从0到20亿,每个QQ号都有可能出现,所有的QQ号被分散的存储北京、上海、深圳、武汉四个城市的服务器中,现在需要一个路由服务器快速的将登陆的QQ路由到正确的服务器,路由服务器可以读取四个QQ服务器的数据,并构建路由表(需全部存在内存中,内存限制1G),路由表该如何存储?
关键:QQ号从0-20亿,每个号码都有可能出现;服务器通过0、1、2、3标示,这四种状态可以用2bit来标示,于是可以考虑使用位图来描述路由表。
解法:从0~20亿,为每个QQ号分配2bit,路由服务器从QQ服务器中获取信息,并设置QQ于服务器号的对应关系。当QQ登录时,路由服务器根据QQ号定位到其对应的状态,并返回对应的服务器号。总的内存大小20亿 * 2 /8 = 5亿字节(约为0.5G)。
应用场景3:高效排序
数据库里存了很多800电话号码,数量特别大,以至于内存放不下,如何排序,时间比空间更重要?电话号码类似于800-810-5555。
关键:去掉电话号码的800后面就是7位的十进制整数,每个整数都有可能出现而且不会重复出现,可以采用各种排序算法对这些数据进行排序,但时间复杂度都在O(NlogN)及以上。
解法:因每个七位以内的整数都有可能出现,可以用1bit来标示电话号是否出现,遍历整个电话号序列,设置相应的位,遍历位图收集位被设置的号码即可。
扩展:对于上述问题,每个电话号码最多出现一次,如果关键字可能多次重复出现,但关键字范围比较确定且很集中的情况下,也可使用位图(根据关键字最多可能出现的次数确定每个关键字需要的位数),但此时的位图通常会是一个整型数组,数组内容为对应位置关键字出现的次数,在执行收集过程时,对于每个关键字要收集多次(根据数组的值确定)。如有一大批职工的年龄信息,需要对这些职工按照年龄信息进行排序,则只需要建立一个长度为100的数组,每个数组为对应年龄人的个数,扫描一遍数组,收集年龄信息即可。
引用:
http://blog.csdn.net/hguisu/article/details/7880288
http://blog.csdn.net/v_july_v/article/details/6685962
http://www.tuicool.com/articles/mUb2Qnn
http://nemogu.iteye.com/blog/1522332
http://blog.csdn.net/v_july_v/article/details/7382693














 2471
2471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









