







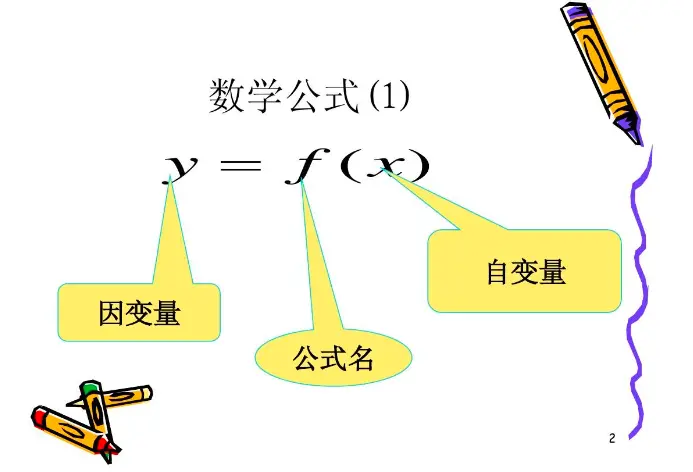
在统计学和机器学习中,因变量(Dependent Variable)和自变量(Independent Variable)是描述数据特征和建模关系的重要概念:
1. **自变量(Independent Variables)**:
- 自变量是模型中的解释变量,即我们用来预测或解释的数据点。
- 在实验设计中,自变量是研究者主动改变以观察其对结果影响的变量。
- 在机器学习中,自变量通常指输入特征(Features)或预测器(Predictors)。
2. **因变量(Dependent Variables)**:
- 因变量是模型中的响应变量,即我们试图预测或解释的结果。
- 在实验设计中,因变量是受自变量影响的结果或输出。
- 在机器学习中,因变量通常指目标变量(Target Variable)或输出(Output)。
3. **关系**:
- 自变量和因变量之间的关系是模型试图捕捉和建模的主要内容。例如,在回归分析中,我们尝试找到一个数学模型来描述自变量如何影响因变量。
4. **线性关系**:
- 在线性模型中,自变量和因变量之间的关系被假设为线性的,即它们的变化遵循直线或平面。
5. **非线性关系**:
- 在非线性模型中,自变量和因变量之间的关系是非线性的,可能遵循曲线或更复杂的几何形状。
6. **多变量情况**:
- 在多变量情况下,模型可能包含多个自变量和/或多个因变量,这使得关系更加复杂。
7. **交互作用**:
- 自变量之间可能存在交互作用,其中一个自变量的影响可能依赖于另一个自变量的值。
8. **独立性**:
- 在理想情况下,自变量之间应该是相互独立的,以避免多重共线性问题。
9. **控制变量**:
- 在实验设计中,可能还需要控制变量,这些变量不是主要的研究焦点,但可能影响结果。
10. **数据预处理**:
- 在数据分析之前,通常需要对自变量进行预处理,如特征缩放、编码分类变量等。
11. **模型选择**:
- 根据自变量和因变量的性质和关系,选择适当的统计模型或机器学习算法。
12. **因果关系**:
- 虽然自变量和因变量的名称暗示了一种因果关系,但在观察性研究中,确定真正的因果关系需要更严格的实验设计。
在构建模型时,理解自变量和因变量及其关系对于设计实验、选择合适的分析方法和解释结果至关重要。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











