







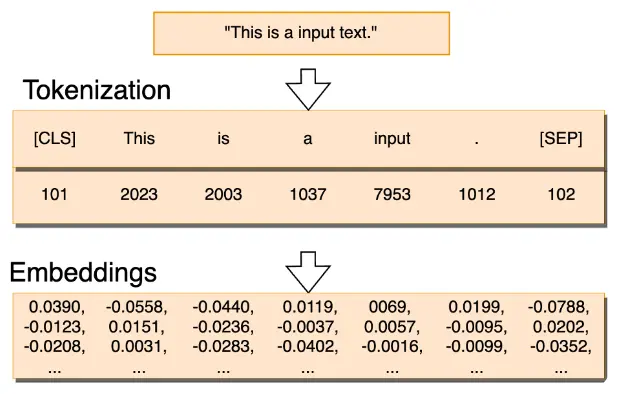
在大模型,尤其是自然语言处理(NLP)中的上下文中,"token"通常指的是文本中的一个基本单位。这个单位可以是单词、字符、或者经过分词后的一个词或短语。Token量,即token的数量,是指在文本数据集中token的总数。
以下是关于token量的几点详细说明:
1. **文本分词**:在处理文本数据时,通常首先需要进行分词,即将连续的文本字符串分割成一个个的token。
2. **词汇表**:模型会有一个词汇表(Vocabulary),包含了所有可能出现的token。每个token在词汇表中会有一个唯一的索引或ID。
3. **表示方法**:在模型中,文本通常会被表示为token的序列,每个token通过其在词汇表中的索引来表示。
4. **编码**:文本数据在输入模型之前,会通过某种编码方式(如one-hot编码或词嵌入)转换为模型可以理解的数值形式。
5. **序列长度**:在处理序列数据时,每个序列会有最大长度限制(如BERT模型的512个token)。超过这个长度的文本会被截断,短于这个长度的会被填充到这个长度。
6. **重要性**:token量是衡量文本数据集大小的一个重要指标,它直接影响模型训练的数据量和可能的复杂性。
7. **计算资源**:token量的多少也会影响模型训练和推理时所需的计算资源,包括内存和处理时间。
8. **模型输入**:在实际应用中,模型的输入往往是一个经过分词和编码的token序列,模型通过处理这个序列来生成输出。
9. **上下文理解**:模型需要足够的token量来理解文本的上下文信息,这对于生成准确和连贯的响应至关重要。
10. **数据预处理**:在模型训练之前,token量的数据预处理是必不可少的步骤,包括清洗、标准化、去除停用词等。
在大模型的训练和应用中,token量是一个核心概念,它直接关系到模型的性能和效率。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











