







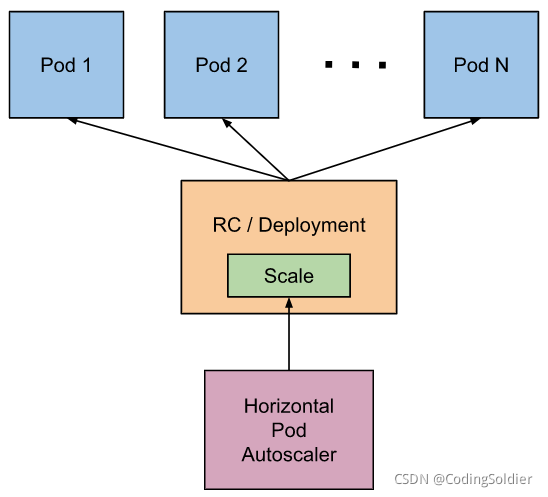
Pod 水平自动扩缩(Horizontal Pod Autoscaler,简称HPA) 可以基于 CPU 利用率自动扩缩 ReplicationController、Deployment、ReplicaSet 和 StatefulSet 中的 Pod 数量。 除了 CPU 利用率,也可以基于其他应程序提供的自定义度量指标来执行自动扩缩。 Pod 自动扩缩不适用于无法扩缩的对象,比如 DaemonSet。
Pod 水平自动扩缩特性由 Kubernetes API 资源和控制器实现。控制器会周期性地调整副本控制器或 Deployment 中的副本数量,以使得类似 Pod 平均 CPU 利用率、平均内存利用率这类观测到的度量值与用户所设定的目标值匹配。
Pod 水平自动扩缩机制图示
本文使用 Kubernetes V1.19、metrics-server v0.5.1 演示pod水平自动扩缩。
安装metrics-server v0.5.1
Metrics Server 是 Kubernetes 内置自动缩放容器资源指标的来源。Metrics Server 从 Kubelets 收集资源指标,并通过 Metrics API 将它们暴露在 Kubernetes apiserver 中,以供 Horizontal Pod Autoscaler 使用。
1、下载metrics-server v0.5.1部署文件。注意,metrics-server对Kubernetes的版本有要求,具体请看metrics-server的GitHub说明
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.5.1/components.yaml
2、metrics-server使用的镜像在Google的仓库,内地无法下载,可将仓库改为阿里云仓库。如果是在本地搭建的集群,没有证书,需要加上--kubelet-insecure-tls配置。
修改components.yaml
将k8s.gcr.io/metrics-server/metrics-server:v0.5.1改为registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.5.1
加上--kubelet-insecure-tls配置
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
# 加上--kubelet-insecure-tls配置
- --kubelet-insecure-tls
3、部署metrics-server
部署命令:kubectl apply -f components.yaml
查看是否部署成功:kubectl get pods -n kube-system
![]()
Horizontal Pod Autoscaler 水平自动扩缩演示
根据CPU使用率自动扩缩
使用官方的hpa-example镜像演练,该镜像定义了一个 index.php 页面来执行 CPU 密集型计算
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>1、编写hpa-example声明文件php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
# 使用mirrorgooglecontainers/hpa-example,避免被墙
image: mirrorgooglecontainers/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache部署php-apache:kubectl apply -f php-apache.yaml
查看php-apache是否部署成功:kubectl get pods

2、创建 Horizontal Pod Autoscaler。可使用 kubectl autoscale deployment XXX 创建HPA。
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
以上命令将创建一个 Horizontal Pod Autoscaler 用于控制php-apache,使 Pod 的副本数量维持在 1 到 10 之间。 大致来说,HPA 通过增加或者减少 Pod 副本的数量以保持所有 Pod 的平均 CPU 利用率在 50% 左右。
查看HPA状态
kubectl get hpa

3、给php-apache发送大量请求,提高php-apache的负载。
新开一个Linux客户端窗口,启动一个容器,并通过一个循环向 php-apache 服务器发送请求。
kubectl run -i --tty load-generator --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
用另一Linux客户端窗口查看HPA的状态,等待十几秒后,php-apache pod的CPU使用率逐渐升高,pod的数量逐渐增加,直到pod的CPU使用率稳定在50%左右,扩容停止。
kubectl get hpa

查看php-apache的pod数量
kubectl get deployment php-apache

4、停止发送请求,php-apache的负载降低。HPA将减少php-apache的pod数量。
使用Ctrl+C,停止另一个客户端的busybox。
一段时间后,php-apace pod数量缩减为1

根据内存使用率自动扩缩
执行清理工作,先删除load-generator、php-apache hpa、php-apache
kubectl delete pod load-generator
kubectl delete hpa php-apache
kubectl delete -f php-apache.yaml
博主的 docker hub 提供了测试内存的镜像 codingsoldier/image-test:v3
@RestController
@RequestMapping("/hpa")
public class HpaController {
public Map map = new HashMap();
@RequestMapping("/mem")
public String mem(@RequestParam("value") Integer value) {
for (int i = 0; i < value; i++) {
MemObj memObj = new MemObj(UUID.randomUUID().toString(), new Random().nextInt(Integer.MAX_VALUE));
map.put(UUID.randomUUID().toString(), memObj);
}
return "ok";
}
}1、新建hpa-mem-test.yaml,镜像使用 codingsoldier/image-test:v3
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-mem-test
spec:
selector:
matchLabels:
run: hpa-mem-test
replicas: 1
template:
metadata:
labels:
run: hpa-mem-test
spec:
containers:
- name: hpa-mem-test
# 这是博主提交到 docker hub 的镜像,用于测试内存
image: codingsoldier/image-test:v3
ports:
- containerPort: 80
resources:
limits:
memory: 400Mi
requests:
memory: 200Mi
---
apiVersion: v1
kind: Service
metadata:
name: hpa-mem-test
labels:
run: hpa-mem-test
spec:
ports:
- port: 80
selector:
run: hpa-mem-test
2、autoscaling/v2beta2 API 版本才支持内存指标监控,如果Kubernetes的版本太老,则无法使用autoscaling/v2beta2 API。
使用声明文件创建HPA,新建hpa-mem.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-mem-test
spec:
# 指定缩放的对象是hpa-mem-test Deployment
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-mem-test
minReplicas: 1
maxReplicas: 10
metrics:
# 每个 Pod 的内存利用率在 60% 以内
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 60
3、部署hpa-mem-test.yaml、hpa-mem.yaml
kubectl apply -f hpa-mem-test.yaml
kubectl apply -f hpa-mem.yaml
4、新开一个Linux客户端窗口,以交互式 Shell 运行 busybox
kubectl run -i --tty busybox --image=busybox -- sh
在busybox中向hpa-mem-test发送请求,增加内存使用量
wget -q -O- http://hpa-mem-test/hpa/mem?value=99999
5、查看HPA状态
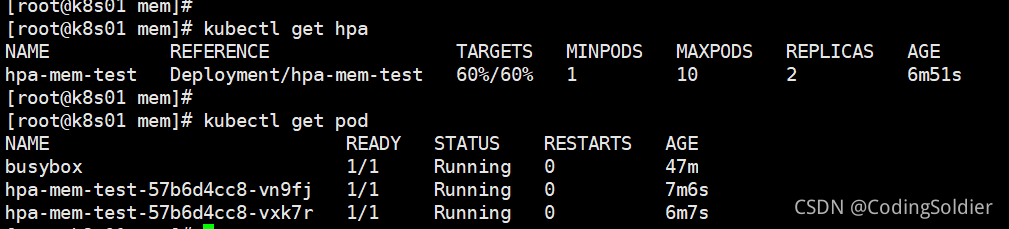
kubectl get hpa
等待十几秒,看看HPA是否发生变化

pod内存使用率已经上升到80%(如果内存使用量没有超过60%),可以再次执行wget -q -O- http://hpa-mem-test/hpa/mem?value=99999,增加POD内存使用量。
hpa-mem-test增加到2个pod,POD中的应用内存使用量稳定在60%,扩容停止。
根据其他指标扩缩
利用 autoscaling/v2 API 版本,可以在自动扩缩 php-apache 这个 Deployment 时使用其他度量指标。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
# 指定缩放的对象是php-apache Deployment
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
# 每个 Pod 的 CPU 利用率在 50% 以内
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
# 每个 Pod 的内存利用率在 60% 以内
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 60
# 每个 Pod 每秒能够服务 1000 个数据包请求
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
# Ingress 后的 Pod 每秒能够服务的请求总数达到 10000 个
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 10k














 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









