







 本文介绍了HDFS(Hadoop Distributed File System)的设计目标、架构及工作原理。HDFS旨在解决传统文件系统容量和吞吐量限制的问题,适用于PB、EB级别的大数据集存储。文章详细解析了NameNode与DataNode的角色分工、块的冗余备份机制以及元数据的管理和更新流程。
本文介绍了HDFS(Hadoop Distributed File System)的设计目标、架构及工作原理。HDFS旨在解决传统文件系统容量和吞吐量限制的问题,适用于PB、EB级别的大数据集存储。文章详细解析了NameNode与DataNode的角色分工、块的冗余备份机制以及元数据的管理和更新流程。
HDFS(Hadoop Distributed File System)原理
1、分布式文件系统
( 1)为什么需要分布式文件系统?传统的文件系统最大的问题是容量和吞吐量的限制。多用户应用的并行读写是分布式文件系统产生的根源。
2、HDFS设计目标
- 基于廉价的普通硬件,可以容忍硬件出错;
- 可以处理大数据集
- HDFS的存储量可以达到PB,EB级别,适合存储单个大文件
- 简单的一致性模型
- 一次写入,多次读取(不支持多用户同时写);支持追加操作,无法更改已写入数据。
- 顺序的数据流访问
- HDFS适合于处理批量数据,而不适合用于随机定位访问。
- 侧重高吞吐,可以容忍高延迟
- 计算靠近数据
- 分布式文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点连接。因此,尽量在数据所在节点进行计算,减少数据移动的网络开销。
3、架构图和工作原理
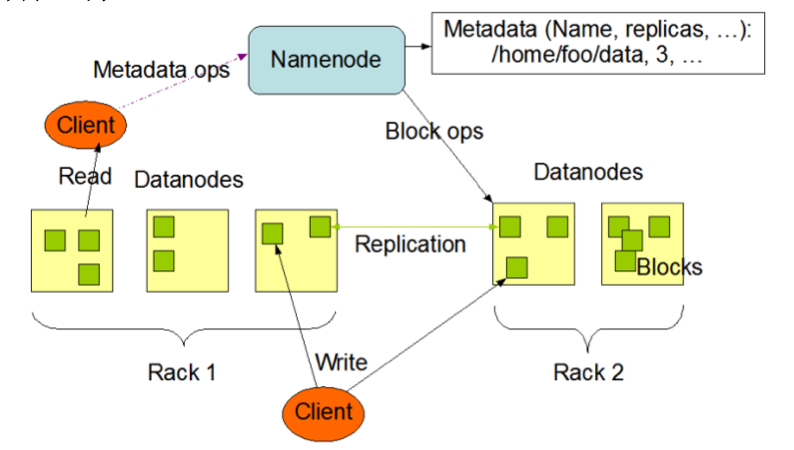
图 1 HDFS架构图
(1)Hadoop 组件
NameNode(NN):用于管理文件系统命名空间的组件。Hadoop 2.x之前存在单点故障问题,Hadoop 3.x开始支持多个NameNode元数据(Metadata)保存在NameNode的内存中,1G内存大概可以管理64T实际数据。
DataNode(DN): 用于管理实际数据文件的组件。HDFS将一个大的文件分为多个块(block)来存储,以块为单位进行管理。默认块大小为64M。与传统文件系统不同的是,即使实际数据没有达到块大小,则并不实际占用磁盘空间。DN通过心跳(Heartbeat)与NN进行通信,定期向NN报告其存储的数据块列表。客户端读取/写入数据时直接与DN进行通信。
(2)块的冗余备份
每一块在集群中会存储多份,一个块的所有备份都是同一个ID。如果一个数据块丢失或损坏,可以从其他备份中恢复。
(3)元数据
NameNode中有两个非常重要的本地文件来保存元数据信息:
- fsimage:保存了文件系统目录树信息;保存文件与块的对应关系;
- edits:保存文件系统的更改记录。当客户端进行写操作时,首先记入edits,成功后才会更改内存中数据,而不是直接更改硬盘上的fsimage文件。
元数据载入:NameNode启动时,通过fsimage读取元数据,载入内存;执行edits中的记录;清空edits,保存最新数据;收集DN汇报的块位置信息。
元数据更新:NN运行时,记录文件的创建和写操作到edits;更新内存中的元数据;收集DN汇报的块的创建和复制信息。
(4)HDFS追加写的操作流程
- 客户端与NN通信,获得文件的写保护锁及文件最后一个块的位置;
- 客户端挑选一个DataNode作为主写入点,并对其余节点上该数据块加锁
- 依次更新各个DN上的数据,更新时间戳和校验值
- 最后一个数据块写满,并且所有备份块都完成写入后,向NN申请下一个数据块。















 3774
3774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









