






看了一个同学的博客之后,深有感触,因为自己最近也在研究linux高级服务器编程,在这里稍微做一下总结。
1.首先在网络中发送数据包通过如下的几个过程,刚开始由早期的七层模型到现在的四层模型,
OSI七层模型是理论模型,一般用于理论研究,他的分层有些冗余,实际应用,选择TCP/IP的四层模型

2.数据是如何通过层模型将数据发送成功,这点其实是我之前不能理解的一点,为什么数据可以通过这些虚拟的通道就可以将数据传送到另外一个主机上。下面我会简单的讲一下,数据在每一层的封装和解包的过程。
在数据传送的过程中,都是根据每一层的协议的包头,进行封装。

(1)什么是包头,既然要写在数据前面,当然是用来识别数据的。其实不止如此,包头在不同层的作用不同,总之它是一个判断标识,决定了这个包是否是我本机需要的,它可以经过几次转发等等。我们马上分别解释不同层的包头。
传输层:TCP包头
TCP包头正常占20字节(例外是因为任选字段,稍后说),里面内容可以用如下图来表示
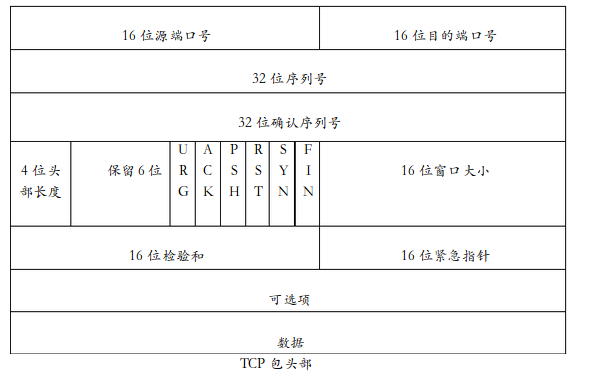
源端口和目的端口:
每个TCP段都包含源端和目的端的端口号(端口号用于识别不同的应用程序,如果目的主机只知道你的IP地址,它进行传送数据的过程中,正好目的主机同时有多个程序在运行,那么就不知道给谁传送了)因此,传输层的端口号用于寻找发起端和接收端应用进程。这两个值加上IP首部中的源IP地址和目的IP地址唯一确定一个TCP连接。有时,一个IP地址和一个端口号也称为一个套接字(socket)。看到这里明白了为什么套接字编程要指定IP地址和端口了。
序列号:
序列号用来标识从T C P发起端向T C P接收端发送的数据字节流,它表示在这个报文段中的第一个数据字节。如果将字节流看作在两个应用程序间的单向流动,则T C P用序列号对每个字节进行计数。序列号是32 bit的无符号数。
报文段:
因主机、路由器和链路层交换机,每个包含了不同的层,反映了不同的功能。位于应用层的信息分组称为报文,运输层分组称为报文段。
——百度百科
头部长度:
(因为确认序列号要提到很多头部长度里的名词,所以先说这个)
头部长度给出首部中32 bit字的数目。需要这个值是因为任选字段的长度是可变的。这个 字段占4 bit,因此TCP最多有60字节的首部。然而,没有任选字段,正常的长度是20字节。
URG: 紧急指针(urgent pointer)有效。(将紧急发送的数据中加入紧急指针,同如带外数据)
ACK: 确认序号有效。
PSH: 接收方应该尽快将这个报文段交给应用层。
RST: 重建连接。
SYN: 同步序号用来发起一个连接。
FIN: 发端完成发送任务。
窗口大小:
TCP的流量控制由连接的每一端通过声明的窗口大小来提供。窗口大小为字节数,起始于确认序号字段指明的值,这个值是接收端正期望接收的字节。窗口大小是一个16 bit字段,因而窗口大小最大为65535字节。 (窗口大小为之后的流量控制和流量阻塞起到一个基础的作用)
校验和:
检验和覆盖了整个的TCP报文段: TCP首部和TCP数据。这是一个强制性的字段,一定是由发端计算和存储,并由收端进行验证。TCP检验和的计算和UDP检验和的计算相似,使用一个伪头部。TCP也是通过这一个特征体现了它的可靠性。
紧急指针:
只有当URG标志置1时紧急指针才有效。紧急指针是一个正的偏移量,和序号字段中的值相加表示紧急数据最后一个字节的序号。TCP的紧急方式是发送端向另一端发送紧急数据的一种方式。
可选项:
最常见的可选字段是最长报文大小,又称为MSS (Maximum Segment Size)。每个连接方通常都在通信的第一个报文段(为建立连接而设置S Y N标志的那个段)中指明这个选项。它指明本端所能接收的最大长度的报文段。 T C P将用户数据打包构成报文段;它发送数据后启动一个定时器;另一端对收到的数据进行确认,对失序的数据重新排序,丢弃重复数据; TCP提供端到端的流量控制,并计算和 验证一个强制性的端到端检验和。
确认序列号:
当建立一个新的连接时, SYN标志变1。序列号字段包含由这个主机选择的该连接的初始序号ISN(Initial Sequence Number)。该主机要发送数据的第一个字节序号为这个ISN加1,因为SYN标志消耗了一个序号(FIN标志也要占用一个序号)。既然每个传输的字节都被计数,确认序号包含发送确认的一端所期望收到的下一个序号。因此,确认序号应当是上次已成功收到数据字节序号加1。只有A C K标志为1时确认序号字段才有效。
发送ACK无需任何代价,因为32 bit的确认序号字段和ACK标志一样,总是TCP首部的一部分。因此,我们看到一旦一个连接建立起来,这个字段总是被设置,ACK标志也总是被设置为1。
(2)网络层:IP包头

版本:哪种版本的IP协议,字段IPV4是4,IPV6是6
总长度:IP首部和数据总长度
生存期(TTL):网络上生存时间,每经过一个路由器就减1,为0时丢弃。
协议:0x06表示TCP,0x11表示UDP
报头校验和:用于检查IP首部完整性,不校验数据
IP选项:可选字段,用于网络调试
(注:《linuxC编程实战》P285...)
数据链路层:MAC包头
14个字节:存放源MAC地址和目的MAC地址
存放发送端的MAC地址,MAC地址是厂家烧在网卡上的标识,全球唯一,这与IP地址不同,一个很好的例子,说IP地址就如同一个职位,而MAC地址则是去应聘这个职位的人,职位既可以让甲坐,也可以让乙坐,同样的道理一个IP地址对于网卡是不做要求,基本上什么样的厂家都可以用,也就是说IP地址与MAC地址并不存在着绑定关系。
但是你有没有想过,我的计算机第一次发送数据包,我的计算机只知道用户给我的目的IP地址,可是我还没有连接到目的计算机,怎么知道它那全球唯一的MAC地址呢,如果不知道,怎么能在数据链路层加包头呢,其实这里我们忽略了一个重要的东西,它叫ARP。
ARP
ARP(Address Resolution Protocol,地址解析协议)就是用来解决这个问题的。
当我不知到目的MAC地址时,计算机会通过交换机、路由器向所在网络发送ARP请求(其中包含目的IP地址),当该网络中有计算机的IP地址与请求中的IP地址相同时就会回复自己的MAC地址给路由器,而其他计算机则会忽略请求。此时路由器把此IP地址和MAC地址对应关系存到自己的ARP缓存中,然后回发给我们的计算机。
但是,当此IP不是该网络中的IP地址怎么办,比如我在西安,但我想给北京一台计算机发数据,那么路由器会把请求的MAC地址换成自己的MAC地址,把请求中的IP地址换成自己的网关IP地址,发送给上级路由器,层层转发,直到找到目的计算机,通过RIP的算法,每个路由器都有到目的主机的最短路由,每个路由中都有一个路由缓冲表。
IP地址是TCP/IP网络层的寻址机制, MAC是802.3/Ethernet链路层的寻址机制, 他们是不同层次的东西,不是并排关系,想一想数据发出去走到网线上最终还是变成了电脉冲,TCP/IP是没有物理层定义的,IP包最终变成电信号之前需要以太网来处理,当IP的数据给予了以太网之后,以太网就用属于它自己的寻址机制来处理以太帧,也就是用MAC地址。

















 38万+
38万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









