






hadoop是阿帕奇基金会的一个顶级项目,主要用于大量的廉价机器组成的集群去执行大规模运算,主要是海量数据的处理。
在hadoop官网(http://hadoop.apache.org/)hadoop包含了4个模块分别是:
1、Hadoop Common
2、Hadoop Distributed File System (HDFS™)
3、Hadoop YARN
4、Hadoop MapReduce
这四个模块分别对应了4个配置文件1.core-site.xml 2.hdfs-site.xml 3.yarn-size.xml 4.mapred-size.xml
我在这里只是做了最简单的配置
1、core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-yarn.dragon.org:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-2.2.0/data/tmp</value>
</property>
2、hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
3、yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4、mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>我的hadoop是安装在linux(centOS-6.5)下面。
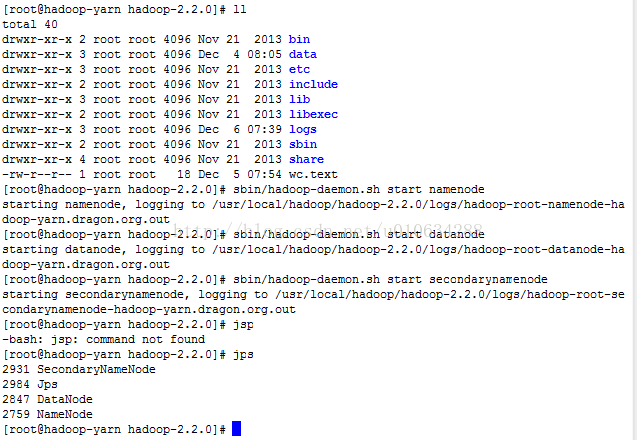
一、首先启动启动HDFS
1 启动NameNode
sbin/hadoop-daemon.sh start namenode
2 启动DataNode
sbin/hadoop-daemon.sh start datanode
3启动SecondaryNameNode
sbin/hadoop-daemon.sh start secondarynamenode
下面这张图表示已经启动成功三个HDFS节点
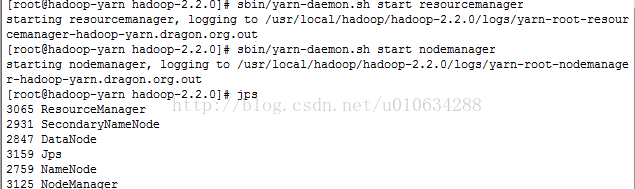
二、启动yarn
1/ 启动ResourceManger
sbin/yarn-daemon.sh start resourcemanager
2/启动NodeManager
sbin/yarn-daemon.sh start nodemanager
三、启动刚完毕之后,我们来启动word count程序
1、首先使用在hadoop根目录下面创建一个文件,我这里创建wc.text
2、将文件放到testdata文件夹中
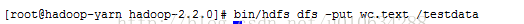
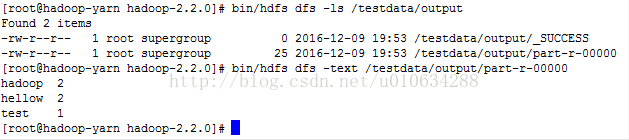
3、查看文件是否在文件中,里面的内容是

4、执行mapreduce命令

5、查看输出结果
至此,haddoop入门wordcount已经全部讲完,本人也是初学者,第一次写hadoop方面的博客,难免有疏漏之处,请大家批评指正。















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









