







文章目录
1、PageMemory
PageMemory 是用于处理内存中页面的抽象。 它在内部与文件存储交互,该文件存储负责分配页面ID,写入和读取页面。 应该区分页面和页面缓冲区的概念。 页是固定长度的数据块,具有唯一的标识符,称为FullPageId。 页面缓冲区是内存中与某个页面关联的区域。 PageMemory完全处理将页面加载到相应页面缓冲区以及从内存中清除未使用的页面缓冲区的过程。 在任何时候页面存储器都可以保留页面缓冲区的任何子集(适合分配的RAM)。
2、FullPageId
FullPageId 由高速缓存ID(32位)和Page ID(64位)组成。 Page ID 实际上是一个虚拟页面标识符,可以在页面生命周期内更改(请参见下面的PageRotation)。EffectivePageId 是 Page ID (partition ID, page index)的一部分,在页面生命周期中不会更改。
2.1、PageId 和 EffectivePageId
PageId 的结构:
+---------+-----------+------------+--------------------------+
| 8 bits | 8 bits | 16 bits | 32 bits |
+---------+-----------+------------+--------------------------+
| OFFSET | FLAGS |PARTITION ID| PAGE INDEX |
+---------+-----------+------------+--------------------------+
| EFFECTIVE PAGE ID |
+---------------------------------------+
偏移量(OFFSET)是保留字段,用于 PAGE ID 旋转或引用数据页中的记录
标志(FLAGS)是用于 PAGE ID 旋转的保留字段
分区ID(PARTITION ID)可以是[0,65500]中的分区标识符,也可以是用于索引分区的保留值0xFFFF。 其他值保留供将来使用。
页面索引(PAGE INDEX)是每个分区中单调增长的数字
3、Page State(页状态)
页面随时可能处于以下状态:
(1)Unloaded(未加载页): 内存中没有加载相应的页面缓存。
(2)Clean(干净页): 页面缓冲区已加载,并且页面缓冲区的内容等于写入磁盘的数据
(3)Dirty(脏页): 页面缓冲区已被修改,并且页面缓冲区的内容不等于写入磁盘的数据
(4)Dirty in checkpoint(检查点脏页): 在第一次修改被写入磁盘之前,页面缓冲区已被修改,检查点已启动,并且页面缓冲区已被再次修改。 在这种状态下,PageMemory 为每个页面保留两个页面缓冲区-第一个用于当前检查点(进行中),第二个用于下一个检查点。
PageMemory会跟踪脏页ID,并能够将此列表提供给检查指针线程。 当检查点启动时,脏页的集合会自动重置为新的空集合。
3.1、Page Modification(页修改)
每个页面缓冲区都有一个关联的读写锁和一个标签。 页面标签是页面ID的一部分,用于页面旋转。
为了读取或写入页面缓冲区内容,必须获得读写锁。 页面缓冲区读写锁要求传递正确的标记,以便获取该锁。
如果传入的标记与实际的页面标记不同,则表示该页面已被重用,并且指向该页面的链接不再有效(请参见下面的页面ID旋转)。
4、Internal Data Structures(内部数据结构)
根据页面类型和页面中的可用空间量,可以选择在FreeList或ReuseList中对其进行跟踪。 FreeList是一种数据结构,用于跟踪部分空闲的页面(适用于数据页面)。 ReuseList跟踪完全空闲的页面,这些页面可以由数据库中的任何其他数据结构使用。
每个分区都有一个特殊的专用页面(元页面),该页面保存分区的状态,页面ID用作与该分区关联的所有数据结构的根。
4.1、Data partitions(数据分区)
对于数据分区,使用以下数据结构:
(1)FreeList(同时用作重用列表)以跟踪空闲页面和空白页面。
(2)分区哈希索引用作缓存的主要存储。
(3)RowStore保留键值对
4.2、Index partition(索引分区)
对于索引分区,使用以下数据结构:
(1)ReuseList(因为BTrees完全获取页面并且不需要跟踪可用空间)
(2)元数据存储,该数据结构跟踪所有分配的索引,并包含【索引名称(index name),根页面ID( root page ID)】的键值对。
5、Page ID Rotation(页面ID轮换)
B+Tree 的结构与 ReuseList(重用列表) 相结合意味着,当 B+Tree 上的页引用通过并发删除返回到 ReuseList 列表中时,可以观察到一种状态,并且此页已在同一 B+Tree 中的另一个位置(ABA问题)。
在这种情况下,可能会发生死锁,因为可能会违反页面锁定的顺序。 为了避免这种情况,每次将页面返回到重用列表时,我们都会更新页面标签。 在这种情况下,如果读者发现由于页面标签不匹配而无法获取锁,它将从头开始重新操作,并读取更新的链接。
6、Checkpointing(检查点)
检查点是将脏页从内存写入持久性存储的过程。
检查点包含以下关键组件:
(1)Checkpoint read-write lock(检查点读写锁): 当数据结构被更新时,此锁可保护PageMemory避免捕获中间状态。 执行数据结构更新(缓存更新,分区迁移等)的线程必须获取读取锁,更新数据结构后释放锁。 Checkpointer 必须获取写锁,捕获脏页面的ID,将页面持久保存到磁盘并释放写锁。
(2)WAL checkpoint record(WAL 检查点记录): 当检查点保持检查点写入锁定时,此记录将插入WAL。如果将WAL从之前的检查点记录变更为当前检查点记录,则数据结构将处于一致状态。
(3)Database checkpoint markers(数据库检查点标记) 当检查点开始或完成时,每个标记都是写入本地FS的文件。这些标记包含WAL检查点记录在WAL中的位置。
检查点开始后,PageMemory 将转变为“写时复制(copy-on-write)”模式。这意味着,如果修改了脏页缓冲区,则该页将在检查点状态下移动到脏页,而 PageMemory 将创建一个对 PageMemory 用户可见的页缓冲区临时副本(页的当前内容)。同时,检查点页面缓冲区仅对检查点程序可见,检查点程序最终会将其刷新到磁盘。当检查点程序完成写入时,它会将所有复制的页刷新到主内存中。
每次修改页面缓冲区时(在释放页面写锁之前),必须将相应的更改记录到WAL中。更具体地说,如果要修改的页面是干净的,则必须记录整个已修改的页面缓冲区。如果要修改的页是脏的,则只应修改二进制页增量,以减少WAL消耗并提高性能。
启动时,节点可以观察检查点标记的以下状态:
最后一个检查点开始标记具有相应的检查点结束标记。
这意味着当没有检查点进行时,进程停止或崩溃,因此页面存储(磁盘)包含一致的数据结构状态。 我们只需要重播自上一个检查点标记之后的记录到WAL的逻辑更新。
最后一个检查点开始标记没有相应的检查点结束标记。这意味着进程在检查点期间崩溃或停止,并且页面存储包含半写页面状态。在这种情况下,恢复包括两个步骤。首先,我们必须从最后完成的检查点标记开始到以开始检查点标记结束的所有WAL记录。这将使数据结构处于一致状态。在此之后,我们必须将WAL逻辑更新从记录B重放到日志的末尾(同上)。
7、Page Store
页面存储的所有方法都必须是线程安全的。
页存储是一个接口,负责页缓冲区分配、读取和写入物理持久性存储。页存储是按分区分配的。相关API可参考,org.apache.ignite.internal.pagemem.store.PageStore。
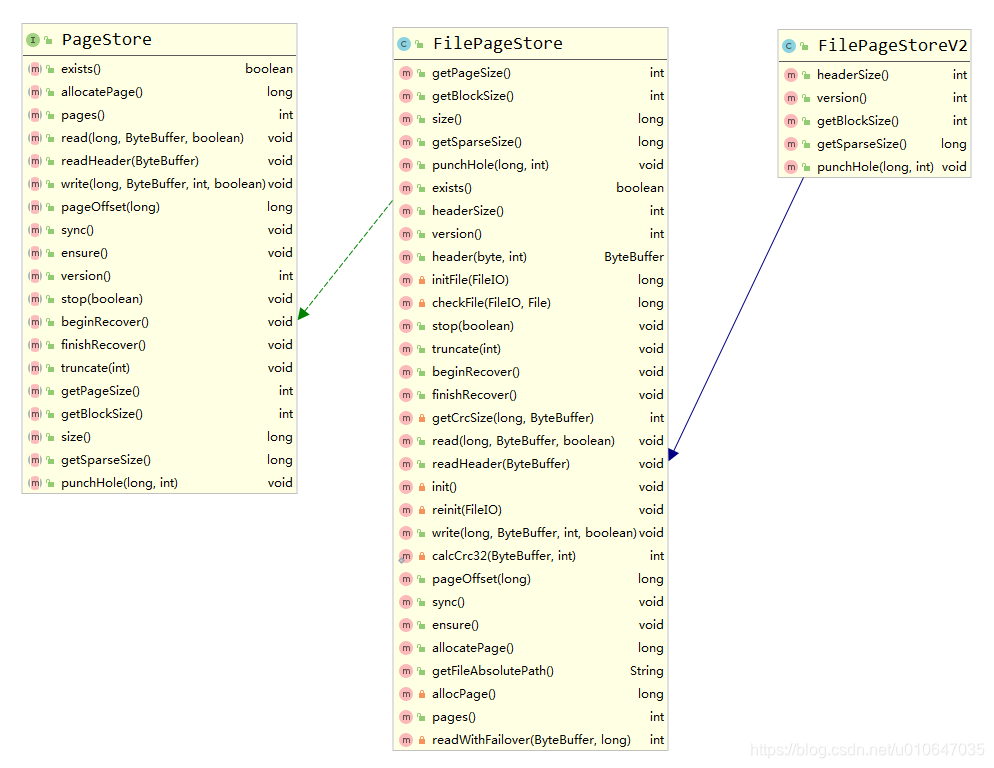
7.1、allocatePage() 页分配
此方法应返回下一个未使用的页索引(新页的地址)。当存储开始时,相应的计数器必须恢复到上次写入页的索引。换句话说,分配的页索引的持久性由检查点执行。
FilePageStore.java
public long allocatePage() throws IgniteCheckedException {
//初始化页
init();
//返回分配页的索引
return allocPage() / pageSize;
}
FilePageStore.java >> init()
/**
* @throws 如果存储文件初始化失败,将抛出异常StorageException
*/
private void init() throws StorageException 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









