







最近周边的人都不停的提到深度学习这个概念,貌似跟我研究的方向有那么一丢丢的关系,而且最近好像很火的样纸,恰巧在上个星期的组会上,老板也提到了这个概念,并且指派了他的三个得意门生来讲这个东西,最近的工作没有什么新的进展,所以也花那么点时间研究一下这个东西,希望对以后的科研方向有所帮助。(PS:首先看了好多人的博客,然后把其中我觉得精髓的东西copy了一部分,总结了一下,留给自己用)
机器学习虽然发展了几十年,但还是存在很多没有良好解决的问题:



以上两张可以很好地解释深度学习是个神马东东,就不用再啰嗦啦
例如图像识别、语音识别、自然语言理解、天气预测、基因表达、内容推荐等等。目前我们通过机器学习去解决这些问题的思路都是这样的(以视觉感知为例子):

从开始的通过传感器(例如CMOS)来获得数据。然后经过预处理、特征提取、特征选择,再到推理、预测或者识别。最后一个部分,也就是机器学习的部分,绝大部分的工作是在这方面做的,也存在很多的paper和研究。
而中间的三部分,概括起来就是特征表达。良好的特征表达,对最终算法的准确性起了非常关键的作用,而且系统主要的计算和测试工作都耗在这一大部分。但,这块实际中一般都是人工完成的。靠人工提取特征。
截止现在,也出现了不少NB的特征(好的特征应具有不变性(大小、尺度和旋转等)和可区分性):例如Sift的出现,是局部图像特征描述子研究领域一项里程碑式的工作。由于SIFT对尺度、旋转以及一定视角和光照变化等图像变化都具有不变性,并且SIFT具有很强的可区分性,的确让很多问题的解决变为可能。但它也不是万能的。
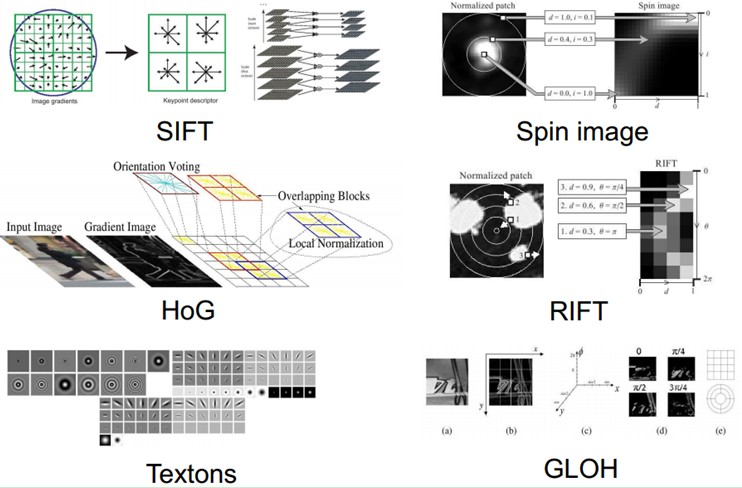
然而,手工地选取特征是一件非常费力、启发式(需要专业知识)的方法,能不能选取好很大程度上靠经验和运气,而且它的调节需要大量的时间。既然手工选取特征不太好,那么能不能自动地学习一些特征呢?答案是能!Deep Learning就是用来干这个事情的,看它的一个别名UnsupervisedFeature Learning,就可以顾名思义了,Unsupervised的意思就是不要人参与特征的选取过程。
那它是怎么学习的呢?怎么知道哪些特征好哪些不好呢?我们说机器学习是一门专门研究计算机怎样模拟或实现人类的学习行为的学科。好,那我们人的视觉系统是怎么工作的呢?为什么在茫茫人海,芸芸众生,滚滚红尘中我们都可以找到另一个她(因为,你存在我深深的脑海里,我的梦里 我的心里 我的歌声里……)。人脑那么NB,我们能不能参考人脑,模拟人脑呢?(好像和人脑扯上点关系的特征啊,算法啊,都不错,但不知道是不是人为强加的,为了使自己的作品变得神圣和高雅。)
近几十年以来,认知神经科学、生物学等等学科的发展,让我们对自己这个神秘的而又神奇的大脑不再那么的陌生。也给人工智能的发展推波助澜。
关于特征
特征是机器学习系统的原材料,对最终模型的影响是毋庸置疑的。如果数据被很好的表达成了特征,通常线性模型就能达到满意的精度。那对于特征,我们需要考虑什么呢?
特征表示的粒度
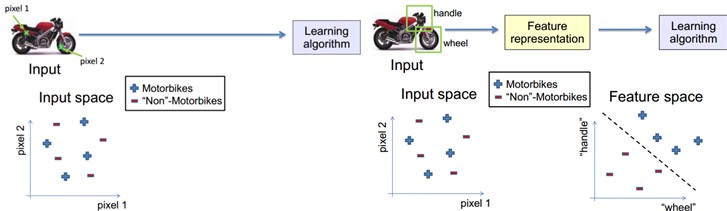
学习算法在一个什么粒度上的特征表示,才有能发挥作用?就一个图片来说,像素级的特征根本没有价值。例如下面的摩托车,从像素级别,根本得不到任何信息,其无法进行摩托车和非摩托车的区分。而如果特征是一个具有结构性(或者说有含义)的时候,比如是否具有车把手(handle),是否具有车轮(wheel),就很容易把摩托车和非摩托车区分,学习算法才能发挥作用。

初级(浅层)特征表示
既然像素级的特征表示方法没有作用,那怎样的表示才有用呢?
1995 年前后,Bruno Olshausen和 David Field 两位学者任职 Cornell University,他们试图同时用生理学和计算机的手段,双管齐下,研究视觉问题。
他们收集了很多黑白风景照片,从这些照片中,提取出400个小碎片,每个照片碎片的尺寸均为 16x16 像素,不妨把这400个碎片标记为 S[i], i = 0,.. 399。接下来,再从这些黑白风景照片中,随机提取另一个碎片,尺寸也是 16x16 像素,不妨把这个碎片标记为 T。
他们提出的问题是,如何从这400个碎片中,选取一组碎片,S[k], 通过叠加的办法,合成出一个新的碎片,而这个新的碎片,应当与随机选择的目标碎片 T,尽可能相似,同时,S[k] 的数量尽可能少。用数学的语言来描述,就是:
Sum_k (a[k] * S[k]) --> T, 其中 a[k] 是在叠加碎片 S[k] 时的权重系数。
为解决这个问题,Bruno Olshausen和 David Field 发明了一个算法,稀疏编码(Sparse Coding)。
稀疏编码是一个重复迭代的过程,每次迭代分两步:
1)选择一组 S[k],然后调整 a[k],使得Sum_k (a[k] * S[k]) 最接近 T。
2)固定住 a[k],在 400 个碎片中,选择其它更合适的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
经过几次迭代后,最佳的 S[k] 组合,被遴选出来了。令人惊奇的是,被选中的 S[k],基本上都是照片上不同物体的边缘线,这些线段形状相似,区别在于方向。
Bruno Olshausen和 David Field 的算法结果,与 David Hubel 和Torsten Wiesel 的生理发现,不谋而合!
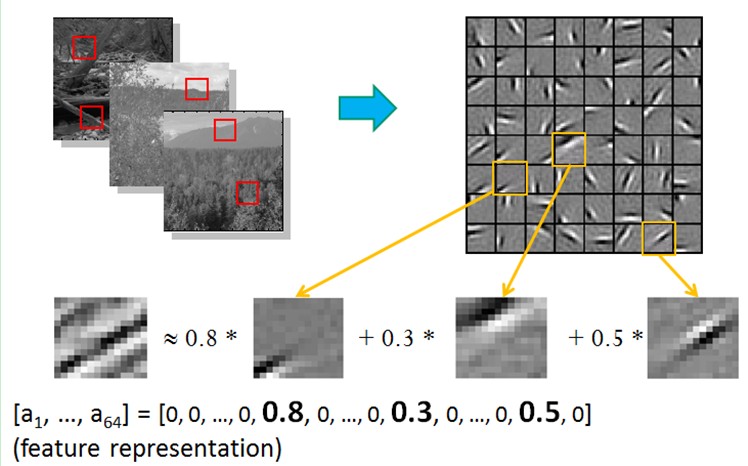
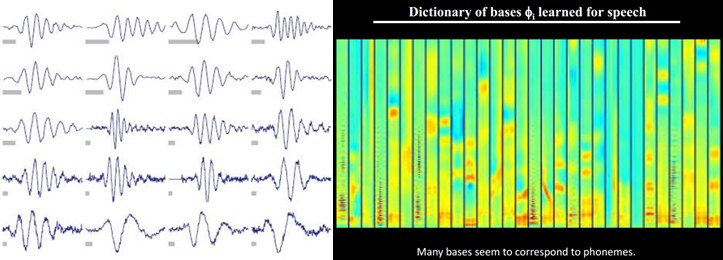
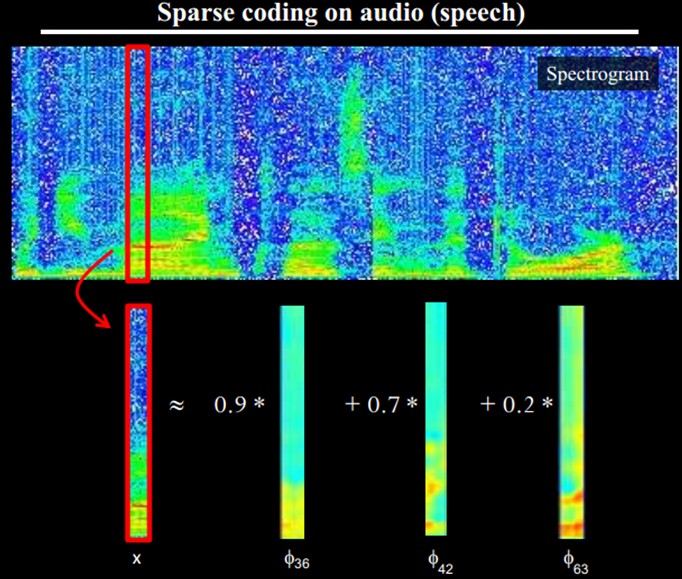
也就是说,复杂图形,往往由一些基本结构组成。比如下图:一个图可以通过用64种正交的edges(可以理解成正交的基本结构)来线性表示。比如样例的x可以用1-64个edges中的三个按照0.8,0.3,0.5的权重调和而成。而其他基本edge没有贡献,因此均为0 。
另外,大牛们还发现,不仅图像存在这个规律,声音也存在。他们从未标注的声音中发现了20种基本的声音结构,其余的声音可以由这20种基本结构合成。
结构性特征表示
小块的图形可以由基本edge构成,更结构化,更复杂的,具有概念性的图形如何表示呢?这就需要更高层次的特征表示,比如V2,V4。因此V1看像素级是像素级。V2看V1是像素级,这个是层次递进的,高层表达由底层表达的组合而成。专业点说就是基basis。V1取提出的basis是边缘,然后V2层是V1层这些basis的组合,这时候V2区得到的又是高一层的basis。即上一层的basis组合的结果,上上层又是上一层的组合basis……(所以有大牛说Deep learning就是“搞基”,因为难听,所以美其名曰Deep learning或者Unsupervised Feature Learning)
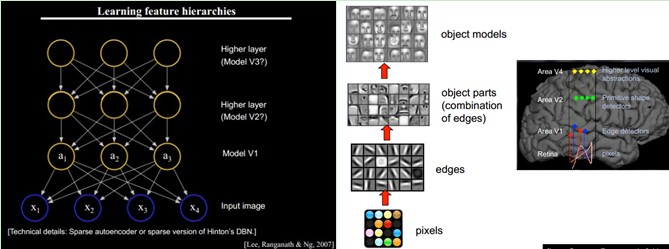
直观上说,就是找到make sense的小patch再将其进行combine,就得到了上一层的feature,递归地向上learning feature。
在不同object上做training是,所得的edge basis 是非常相似的,但object parts和models 就会completely different了(那咱们分辨car或者face是不是容易多了):

从文本来说,一个doc表示什么意思?我们描述一件事情,用什么来表示比较合适?用一个一个字嘛,我看不是,字就是像素级别了,起码应该是term,换句话说每个doc都由term构成,但这样表示概念的能力就够了嘛,可能也不够,需要再上一步,达到topic级,有了topic,再到doc就合理。但每个层次的数量差距很大,比如doc表示的概念->topic(千-万量级)->term(10万量级)->word(百万量级)。
一个人在看一个doc的时候,眼睛看到的是word,由这些word在大脑里自动切词形成term,在按照概念组织的方式,先验的学习,得到topic,然后再进行高层次的learning。
需要有多少个特征?
我们知道需要层次的特征构建,由浅入深,但每一层该有多少个特征呢?
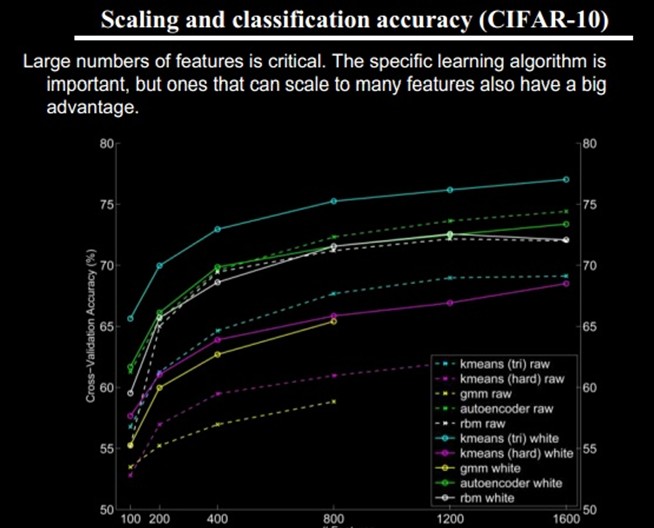
任何一种方法,特征越多,给出的参考信息就越多,准确性会得到提升。但特征多意味着计算复杂,探索的空间大,可以用来训练的数据在每个特征上就会稀疏,都会带来各种问题,并不一定特征越多越好。















 5658
5658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









