









Chapter 8:Reading and Writing Natural Languages
Summarizing Data
自然语言处理这块有一项重要的内容就是文本摘要,本节涉及的只是去停用词,类似中文的“地,的,得”,英文中对应的“the,be,and”等等。大概有5000个高频词汇,这足够过滤掉很多无用的2-grams,下面展示的是前100个词汇:
def isCommon(ngram):
commonWords = ["the", "be", "and", "of", "a", "in", "to", "have", "it","i", "that", "for", "you",\
"he", "with", "on", "do", "say", "this","they", "is", "an", "at", "but","we", "his", "from", "that",\
"not","by", "she", "or", "as", "what", "go", "their","can", "who", "get","if", "would", "her", "all", \
"my", "make", "about", "know", "will","as", "up", "one", "time", "has", "been", "there", "year",\
"so","think", "when", "which", "them", "some", "me", "people", "take","out", "into", "just",\
"see", "him", "your", "come", "could", "now","than", "like", "other", "how", "then", "its",\
"our", "two", "more","these", "want", "way", "look", "first", "also", "new", "because",\
"day", "more", "use", "no", "man", "find", "here", "thing", "give","many", "well"]
for word in ngram:
if word in commonWords:
return True
return False
Markov Models
所有的文本自动生成工具都是基于马尔可夫模型,以简单的天气预报系统为例:
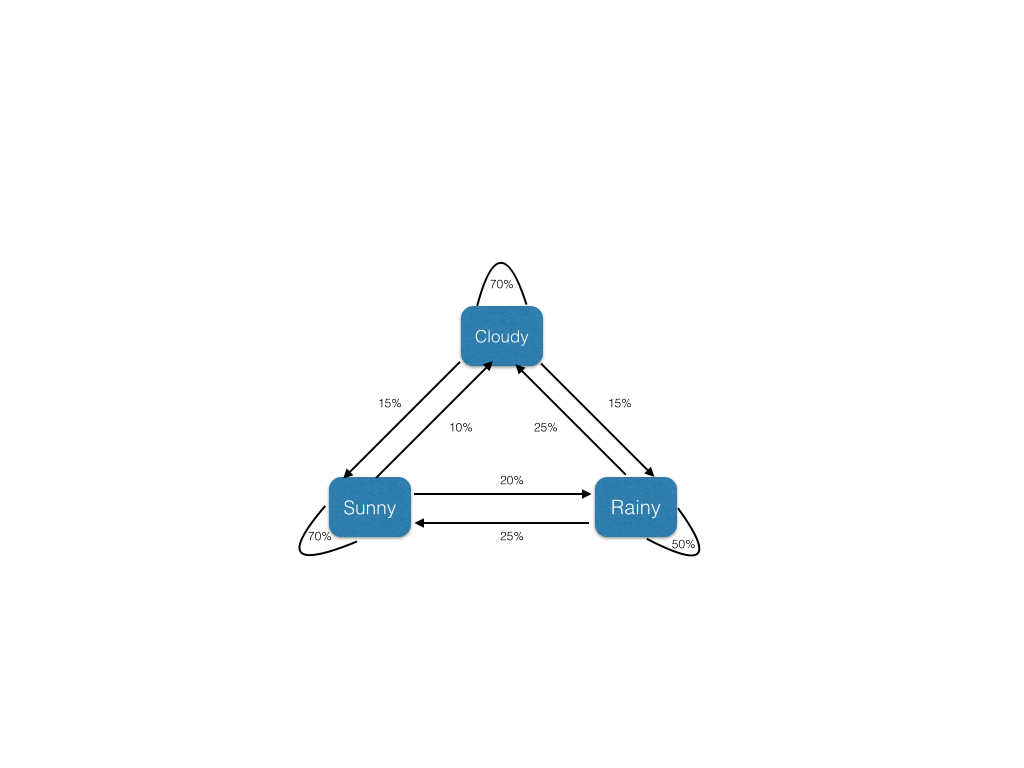
模型中,如果今天是晴天的话,第二天是晴天的概率为70%,10%的概率第二天是雨天,剩下20%的概率是多云天气,类似如果今天是雨天,接下来的一天是雨天的概率是50%。
马尔可夫模型满足三个条件:
- 从一点出发的所有概率和胃为1,不管该模型有多么复杂
- 虽然例子中只有三个状态转换,但是可产生无数个天气状态链
- 下一个状态的产生仅跟现在所在点的状态相关,比如现在是Sunny,明天是Rainy的概率就是10%,不管前100天天气如何
- 如果模型足够复杂,可能到达模型中某个点(状态)的概率比到其他点(状态)的概率小的多,这涉及到背后的数学问题
值得一提的是,Google的pagerank 算法部分基于的就是马尔可夫模型,是近年来很受欢迎的模型之一。让我们来写一个简单的文本生成器,它的2-grams词典是基于the inauguration speech of William Henry Harrison本身的。
from urllib import urlopen
from random import randint
#计算与所有词跟某个词相连的总数,比如某个词“中国”,与“中国”相连的词有“人民”,“铁路”,“外交部”等
#“中国人民”组合在文章中出现8次记作{"人民":8},类似{"铁路":3},{"外交部":5}
def wordListSum(wordList):
sum = 0
for word,value in wordList.items():
sum += value
return sum
#随机从"人民","铁路","外交部"选取一个词作为"中国"的相连组合
def retrieveRandomWord(wordList):
randIndex = randint(1,wordListSum(wordList))
for word, value in wordList.items():
randIndex -= value
if randIndex <= 0:
return word
def buildWordDict(text):
#去除换行和引号
text = text.replace("\n"," ")
text = text.replace("\"","")
#把标点符号也作为单词,也是马尔可夫链的一个node之一
punctuation = [',','.',':',';']
for symbol in punctuation:
text = text.replace(symbol," "+symbol+" ")
words = text.split(" ")
#过滤掉空单词
words = [word for word in words if word != ""]
#建立比如{"中国":{"人民":8,"铁路":3,"外交部":5},
# "美国":{"人民":2,"铁路":5,"外交部":1}
# }这样的二维词典
wordDict = {}
for i in range(1,len(words)):
if words[i-1] not in wordDict:
wordDict[words[i-1]] = {}
if words[i] not in wordDict[words[i-1]]:
wordDict[words[i-1]][words[i]] = 0
wordDict[words[i-1]][words[i]] += 1
return wordDict
text = str(urlopen("http://pythonscraping.com/files/ inaugurationSpeech.txt").read())
wordDict = buildWordDict(text)
length = 100
chain = ""
currentWord = "I"
for i in range(0,length):
chain += currentWord+" "
currentWord = retrieveRandomWord(wordDict[currentWord])
print chain
显然基于马尔可夫模型原理,每次运行程序生成的文本都不一样,文本长度限定100词,其中一次运行结果:
I shall now so long as those of the arrangement and fostering a people and so far the destruction of Congress should doubt that the master of half a distinguished for one time act not of a misconstruction of ascertaining the United States . Fellow- citizens , indeed , the most essential difference . There are told by their subjects . It is to them . There is an Executive of liberty , how much the power to prevent his disposal . He claims of wealth , and knowing the institutions of interest , quadrupled in this danger to matters connected
Six Degrees of Wikipedia:Conclusion
Wikipedia的六度空间理论不同于真实的六度空间理论,在Wikipedia中由A可以链接到B,但由B不一定能链接到A,这是A->B的有向图。六度空间理论是基于无向图的。在有向图中,找到A->D的最常用的方法是最短路径优先,使用广度优先算法进行路径搜索。
#The link tree may either be empty or contain multiple links
def searchDepth(targetPageId, currentPageId, linkTree, depth):
if depth == 0:
#Stop recursing and return, regardless
return linkTree
if not linkTree:
linkTree = constructDict(currentPageId)
if not linkTree:
#No links found. Cannot continue at this node
return {}
if targetPageId in linkTree.keys():
print("TARGET "+str(targetPageId)+" FOUND!")
raise SolutionFound("PAGE: "+str(currentPageId))
for branchKey, branchValue in linkTree.items():
try:
#Recurse here to continue building the tree
linkTree[branchKey] = searchDepth(targetPageId,branchKey,branchValue, depth-1)
except SolutionFound as e:
print(e.message)
raise SolutionFound("PAGE: "+str(currentPageId))
return linkTree
进行广度优先搜索的算法主函数,算法遵循的规则:
- 迭代次数达到给定的限制,算法结束
- 某个初始点没有下一个链接,也就是没有targetPageId,返回
- 某个初始点有下一个链接,但此链接已经被访问过,返回到该初始点,选择它另外一个targetPageId,继续搜索
- 如果在给定的深度depth下没有找到一条A->D的路径,将depth减1,再次调用该函数
Natural Language Toolkit
我想搞自然语言处理的没人不知道NLTK吧,非常强大的自然语言处理的Python第三方库,更多的安装细节请访问NLTK website,安装完之后需要下载其中的语料库,nltk.book里包含9本书,分别是命名text1到text9。
Lexicographical Analysis with NLTK
使用NLTK进行一些简单的操作,具体更为详细的内容请学习用Python进行自然语言处理这本经典之作
注:本文为读书笔记,内容基本来自Web Scraping with Python(Ryan Mitchell著),部分代码有所改动,版权归作者所有,转载请注明出处















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









