




 本文解析了在Spark中使用PhoenixOutputFormat时遇到的ClassNotFoundException异常,详细展示了异常堆栈跟踪,并提供了解决方案,包括在Spark的classpath中添加phoenix-core-*.jar的具体步骤。
本文解析了在Spark中使用PhoenixOutputFormat时遇到的ClassNotFoundException异常,详细展示了异常堆栈跟踪,并提供了解决方案,包括在Spark的classpath中添加phoenix-core-*.jar的具体步骤。
- 问题
ClassNotFoundException: Class org.apache.phoenix.mapreduce.PhoenixOutputFormat not found - 详细展示
Exception in thread "main" java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.phoenix.mapreduce.PhoenixOutputFormat not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2112)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getOutputFormatClass(JobContextImpl.java:232)
at org.apache.spark.rdd.PairRDDFunctions.saveAsNewAPIHadoopDataset(PairRDDFunctions.scala:971)
at org.apache.spark.rdd.PairRDDFunctions.saveAsNewAPIHadoopFile(PairRDDFunctions.scala:903)
at org.apache.phoenix.spark.ProductRDDFunctions.saveToPhoenix(ProductRDDFunctions.scala:51)
at com.mypackage.save(DAOImpl.scala:41)
at com.mypackage.ProtoStreamingJob.execute(ProtoStreamingJob.scala:58)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.mypackage.SparkApplication.sparkRun(SparkApplication.scala:95)
at com.mypackage.SparkApplication$delayedInit$body.apply(SparkApplication.scala:112)
at scala.Function0$class.apply$mcV$sp(Function0.scala:40)
at scala.runtime.AbstractFunction0.apply$mcV$sp(AbstractFunction0.scala:12)
at scala.App$$anonfun$main$1.apply(App.scala:71)
at scala.App$$anonfun$main$1.apply(App.scala:71)
at scala.collection.immutable.List.foreach(List.scala:318)
at scala.collection.generic.TraversableForwarder$class.foreach(TraversableForwarder.scala:32)
at scala.App$class.main(App.scala:71)
at com.mypackage.SparkApplication.main(SparkApplication.scala:15)
at com.mypackage.ProtoStreamingJobRunner.main(ProtoStreamingJob.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:569)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:166)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:189)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:110)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: Class org.apache.phoenix.mapreduce.PhoenixOutputFormat not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2018)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2110)
... 30 more
-
原因
- 生产环境出现此种问题:说明PhoenixOutputFormat类找不到,即phoenix-core-*.jar找不到、
- 此时环境出现此种问题:还是要考虑phoenix-core-*.jar的问题
-
解决方案
目前解决方案都是生产环境的:因为spark在运行程序的时候找不到该包,所以那我们就在spark的classpath添加上该文件,就可以了。
一般spark的classpath在 /etc/spark/conf/classpath.txt下,里面有一堆不知道什么用途的包,剩下的就是把phoenix所依赖的jar路径copy过来就行(注意此处:集群每台机器上都要copy),如下: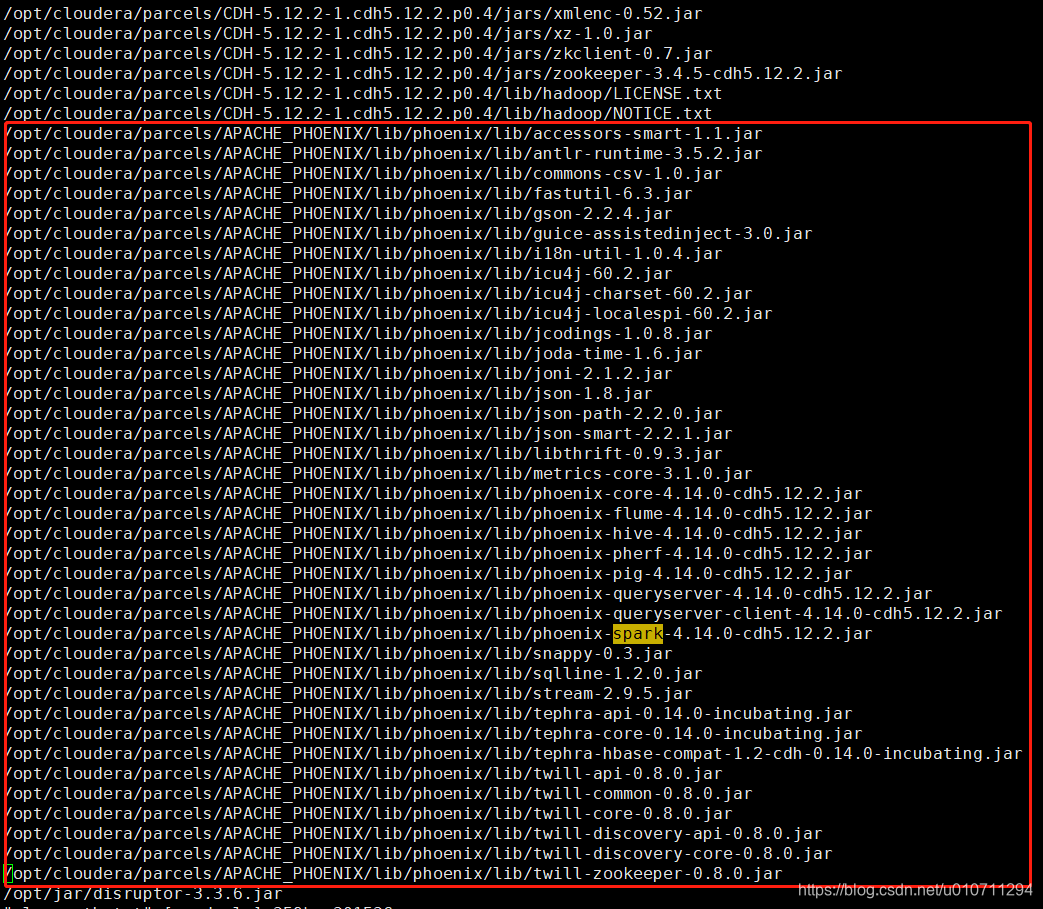
注意:感觉此种方式比较low,但是目前还没有找到其他比较好的方式来解决这个问题,所以就只能先这么搞了。
更多大数据相关问题、或者互联网金融相关问题可以咨询我,免费解答,

















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









