







本文参考虫师python2实现简单爬虫功能,并增加自己的感悟。
#coding=utf-8
import re
import urllib.request
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
#print(type(html))
html = html.decode('UTF-8')
#print(html)
return html
def getImg(html):
reg = r'img class="BDE_Image" src="(.+?\.jpg)"'
imgre = re.compile(reg)
#print(type(imgre))
#print(imgre)
imglist = re.findall(imgre,html)
#print(type(imglist))
#print(imglist)
num = 0
for imgurl in imglist:
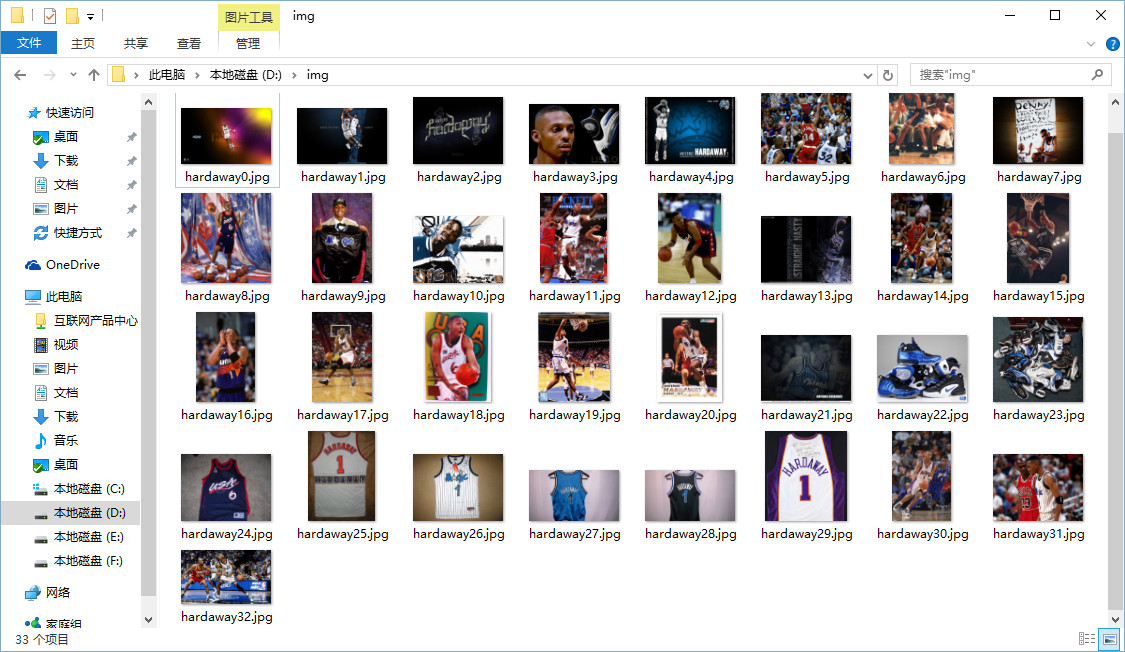
urllib.request.urlretrieve(imgurl,'D:\img\hardaway%s.jpg' %num)
num+=1
html = getHtml("http://tieba.baidu.com/p/1569069059")
print(getImg(html))
- re-python自带模块,用于正则表达式的相关操作
- https://docs.python.org/3/library/re.html
- urllib.request,来自扩展库urllib,用于打开网址相关操作
先定义了一个getHtml()函数
- 使用urllib.request.urlopen()方法打开网址
- 使用read()方法读取网址上的数据
使用decode()方法指定编码格式解码字符串
我这里指定的编码格式为UTF-8,根据页面源代码得出:

再定义了一个getImg()函数,用于筛选整个页面数据中我们所需要的图片地址
根据需要的图片来编写正则表达式 reg = r’img class=”BDE_Image” src=”(.+?.jpg)”’
- 使用re.compile()方法把正则表达式编译成一个正则表达式对象,在一个程序中多次使用会更有效。
- 使用re.findall()方法匹配网页数据中包含正则表达式的非重叠数据,作为字符串列表。
- urllib.request.urlretrieve()方法,将图片下载到本地,并指定到了D盘img文件夹下
上文中的例子所编写的编码格式是通过查看网页源代码的方式得知的,后来我尝试了下通过正则表达式去匹配获取charset定义的编码格式,然后指定使用匹配来的编码格式。def getHtml(url): page = urllib.request.urlopen(url) html = page.read() #print(type(html)) rehtml = str(html) #print(type(rehtml)) reg = r'content="text/html; charset=(.+?)"' imgre = re.compile(reg) imglist = re.findall(imgre,rehtml) print(type(imglist)) code = imglist[0] print(type(code)) html = html.decode('%s' %code) return html说一说这里的思路,html = page.read()方法处理后,返回的为bytes对象。而re.findall()方法是无法在一个字节对象上使用字符串模式的
所以我新定义了一个变量rehtml,使用str()方法把html的值转为了字符串,供re.findall()方法使用
定义了一个新变量code用来放编码格式的值,因为re.findall()方法获取回来的是列表类型,我需要使用的是字符串类型。

















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









