







爬取某页面的数据时,在我本机环境进行请求,返回的结果是正常的,即不乱码,但是把代码拷贝到其他电脑运行,返回的结果就是乱码了。如下:
我本机的请求结果:
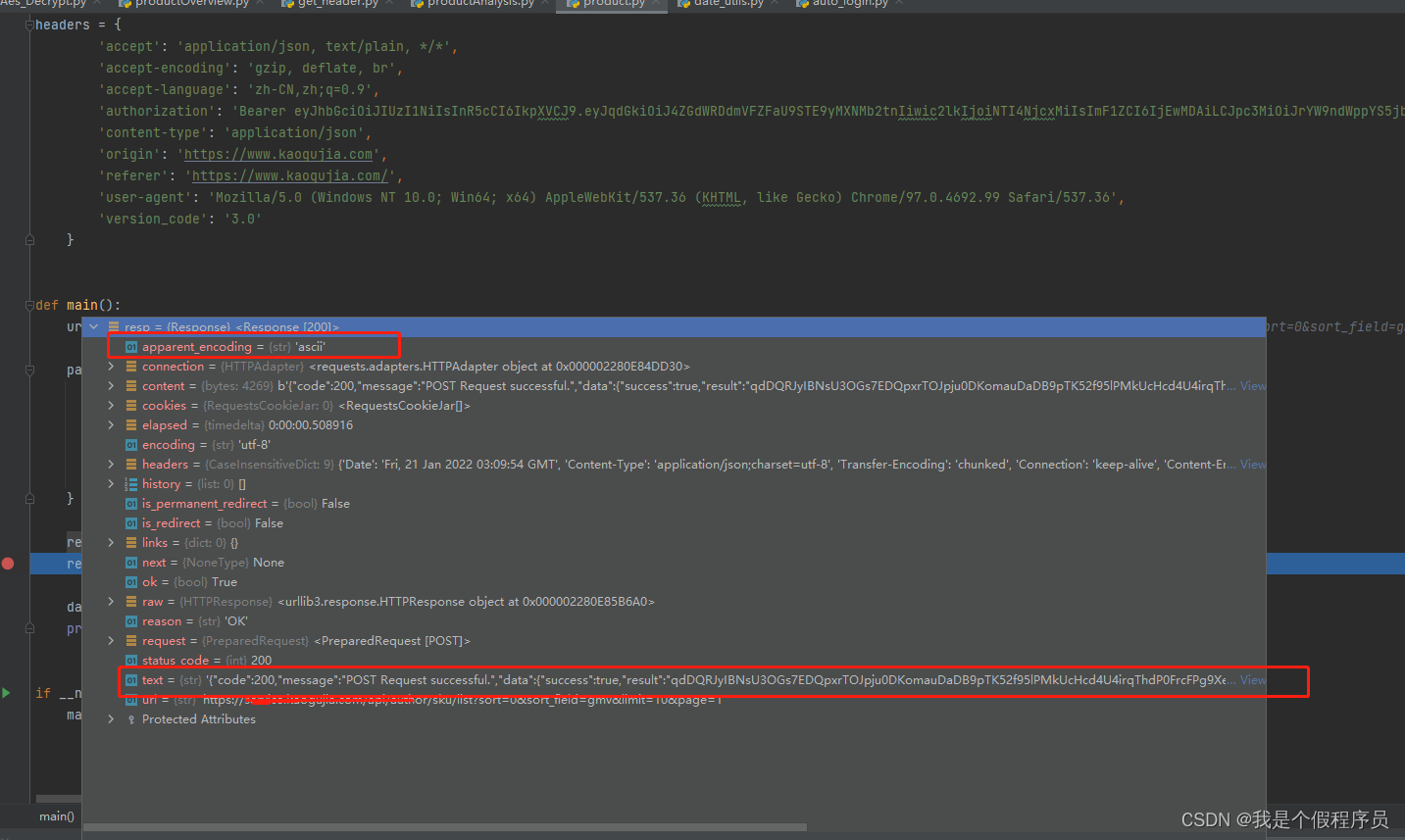
其他电脑运行返回的数据是乱码的,无论是设置utf-8、gbk还是设置gb2312,都无法解码:
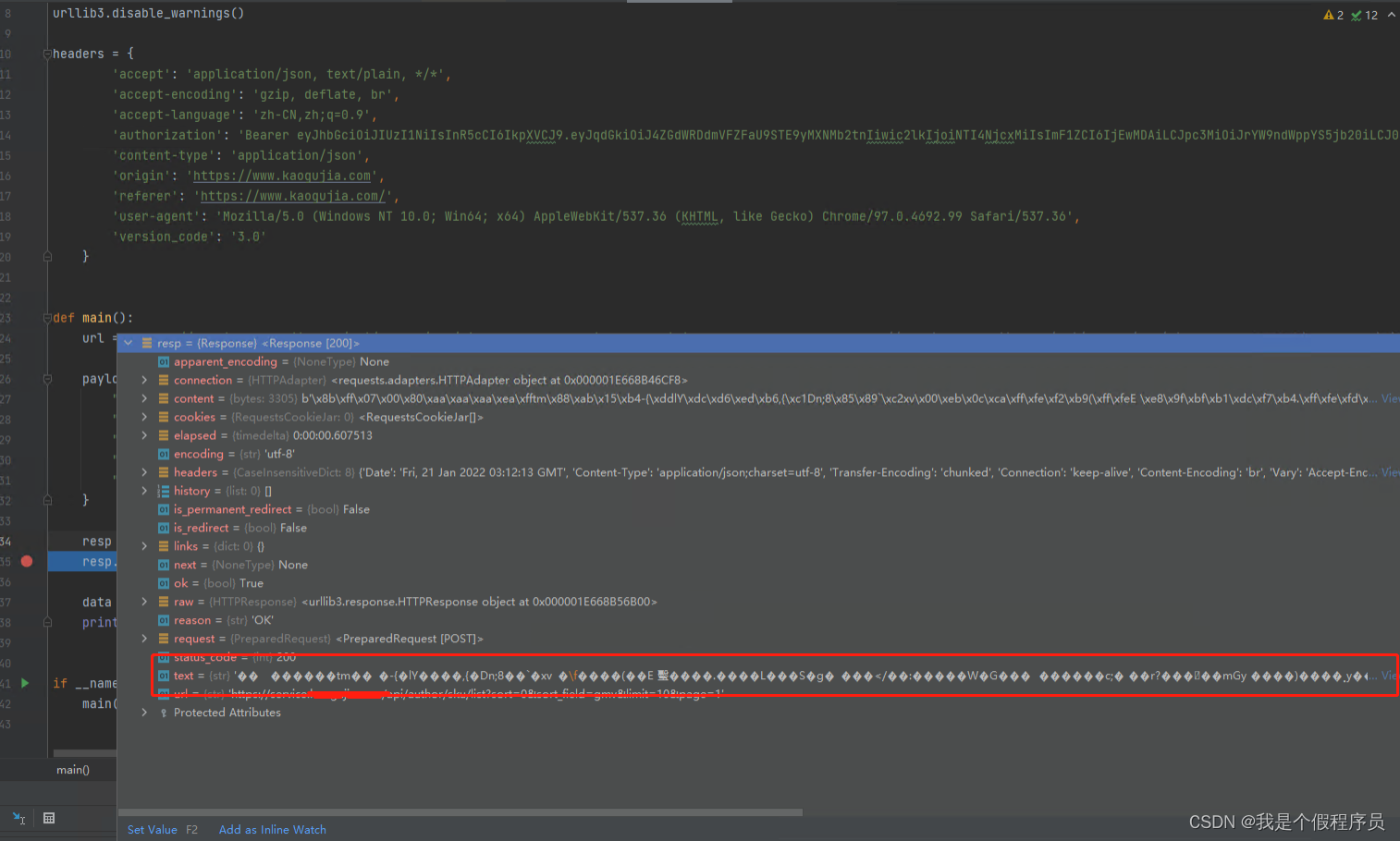
百度了好久,都是说返回结果中文乱码的解决方案,都没有把问题解决(原来是自己问题点没有搜索对,毕竟当时自己也想不到)。后面在技术群中请教大佬后,才知道是headers请求头的Accept-Encoding设置值的问题,即Accept-Encoding='gzip,deflate,br’。
因为代码都一样,在自己本机运行都正常,所以压根想不到是这个导致,所以也没有一个一个的注释进行调试。
最终解决方案就是把gzip去掉,或者把 Accept-Encoding='gzip,deflate,br’ 整行都注释了,再次请求就可以得到正常的结果了。如下:
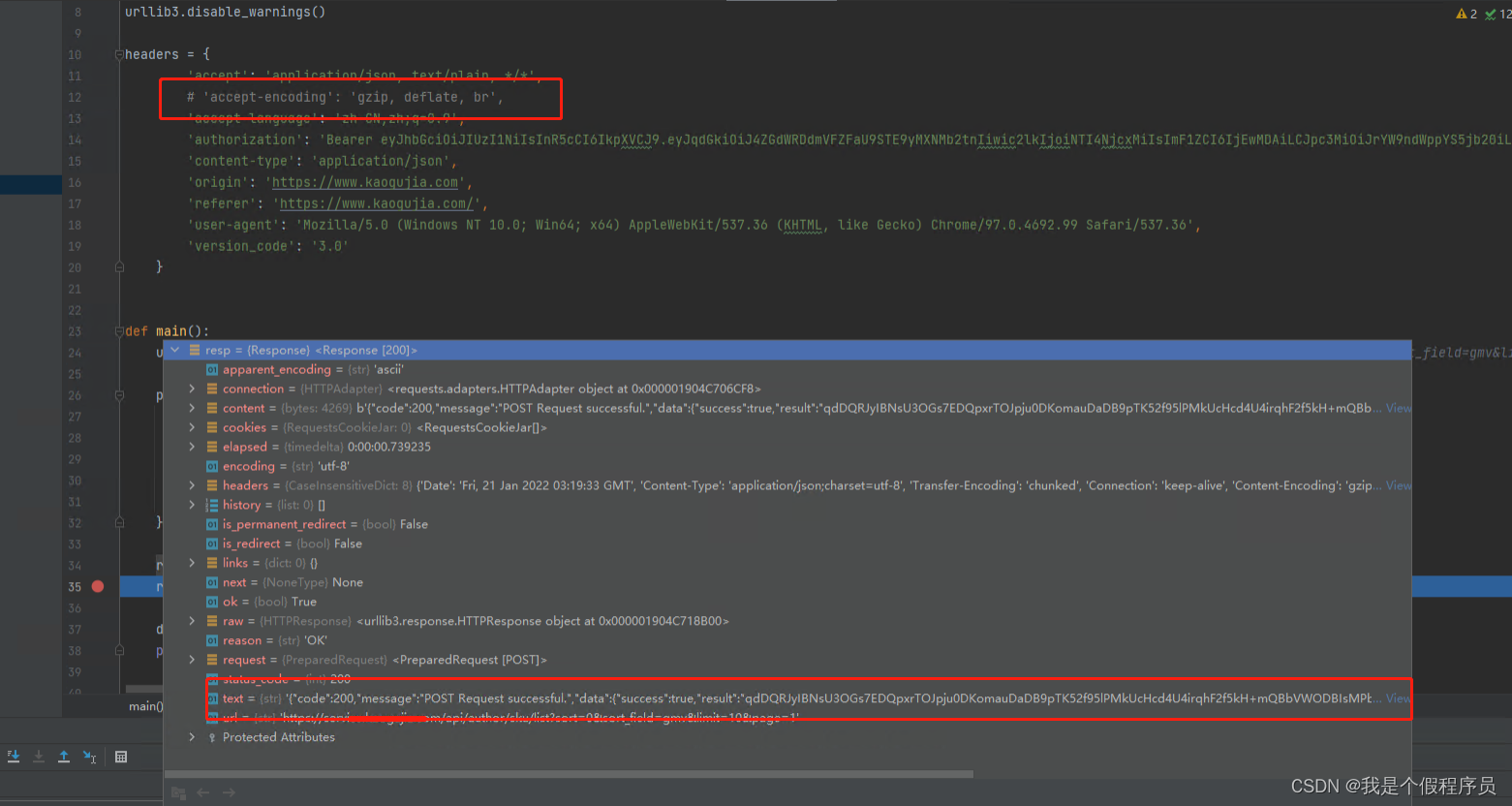
当然网上还有给出另一个方案(这方案在python我不知道怎么用,大家可以自行选择,有知道的也可以留意指导,毕竟本人菜鸟一枚):
设置Header的Accept-Encoding值的同时设置对应的自动解压缩的模式
req.Headers["Accept-Encoding"] = "gzip,deflate,br";
req.AutomaticDecompression = DecompressionMethods.GZip;
‘Accept-Encoding’:是浏览器发给服务器,声明浏览器支持的编码类型。一般有gzip,deflate,sdch,br 等等。
网上对这的解释,那就是:
普通浏览器访问网页,之所以添加"Accept-Encoding" = “gzip,deflate,br”,那是因为,浏览器对于从服务器中返回的对应的gzip压缩的网页,会自动解压缩,所以,其request的时候,添加对应的头,表明自己接受压缩后的数据。
而在我们编写的代码中,如果也添加此头信息,结果就是,返回的压缩后的数据,没有解码,而将压缩后的数据当做普通的html文本来处理,当前显示出来的内容,是乱码了。
相关信息:
从python爬虫引发出的gzip,deflate,sdch,br压缩算法分析 http://www.cnblogs.com/RainLa/p/8057367.html

















 2629
2629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









