







高性能分布式计数器中的并发设计
场景介绍
对实时数据流以不同纬度进行计数并将结果保存到Oracle表中.要求达到以下目标:
- 实时性有要求,单并非是严格要求,根据数据量的大小可适当延迟
- 严格要求数据一致性,即在数据正确的情况下计数的结果应该和总记录数是一致的
- 服务是可扩展的,尽量避免受限于单一资源的限制
- 尽可能的考虑容错
服务设计
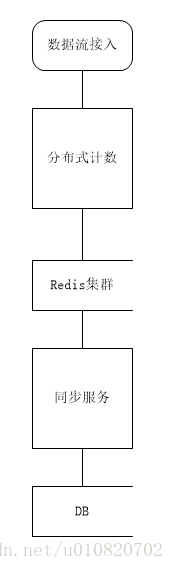
整体架构
实时数据流接入后由Spark服务按要求进行分布式计数,并将计数器的结果写入到Redis集群中.
使用Redis集群可以降低单个Redis节点的压力.Redis中存储的是增量的数据.
同步服务以一定的周期从Redis集群中获取计数器的数据并删除计数器的Key,使得计数器重新开始计数.并将结果更新到关系数据库中供业务系统使用.
可靠性保证
1.Spark分布式计算+Redis集群的写入和性能有保证,支持可扩展
2.Redis集群支持原子的计数器操作,实践证明是可靠的稳定的
3.同步服务删除Redis key的过程和获取数据的过程可以使用Lua脚本来保证整个操作的原子性
性能关键点
Spark到Redis集群的写并发,目前来说每秒对一个节点的写入保守在1W/S+,集群中更高效
同步服务从Redis中获取Key集合的方式,计数器key的数据结构设计,避免使用复杂数据结构
从拿到Redis中key的集合到删除key获取数据消耗的时间
将数据写入DB消耗的时间
从JVM角度看“同步服务”
Redis集群本身不提供对所有节点的keys(“match”)操作,且该操作本身会引起节点的停顿,建议针对单个master节点进行keys操作,对JVM来说可以并发的从多个maser节点中获取对应的key集合
拿到每个master中的keys后,并发的执行”删除&获取流量数据”的操作
并发的操作数据库,如果可能应尽可能的使用批处理写库
保证一个同步周期执行完后执行下一个同步周期,控制上述各个环节的等待时间和超时时间
实现关键点
向Redis写入计数,根据业务设计合理的key规则,选择合适的key数据结构即可
class CarFlowBolt extends RDDVehicleTask {
val log = LogFactory.getLog(classOf[CarFlowBolt])
def execute(input: RDD[Vehicle]) {
//"yyyyMMddHHmm
val flowData = input.map { vehicle => (vehicle.getTgsId + ":" + TimeUtil.format(new Date(vehicle.getPassTime), TimeUtil.MIN_TIME_MINUTE) + ":" + vehicle.getDriveWay + ":" + vehicle.getDriveDir, 1) }
.reduceByKey((n1, n2) => n1 + n2)
flowData.foreach(flow => {
val keys = flow._1.split(":")
//前缀:卡口编号:压缩时间戳:方向编号:车道编号:标记位
val key_minute = RedisKey.Flow.flow_prefix + ":" + flow._1+":M"
val key_hour = RedisKey.Flow.flow_prefix + ":" + keys(0) + ":" + keys(1).substring(0, 10) + ":" + keys(2) + ":" + keys(3)+":H";
val key_day = RedisKey.Flow.flow_prefix + ":" + keys(0) + ":" + keys(1).substring(0, 8) + ":" + keys(2) + ":" + keys(3)+":D";
// one minute 卡口数*方向*车道 key
RedisUtil.cluster.incrBy(key_minute, flow._2)
// one hour 卡口数*方向*车道 key
RedisUtil.cluster.incrBy(key_hour, flow._2)
// one day 卡口数*方向*车道卡口数 key
RedisUtil.cluster.incrBy(key_day, flow._2)
})
}
}设计保证一个同步周期完成后下一个周期才可以开始,可以使用闭锁(CountDownLatch)、Future等语意来实现,应该妥善的处理超时.
public void syncCarflowJob() {
if (config.isEnableha()) {
if (!MasterHeartbeat.isMaster.get()) {
log.warn("current nodes is not master and return .");
return;
}
}
if (run) {
log.warn("last task has runing. wait next cycle.");
return;
}
run = true;
singleThreadPool.execute(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
log.info("start update thread");
Map<String, JedisPool> nodes = jedisCluster.getClusterNodes();
List<Future<?>> futures = new ArrayList<>();
for (JedisPool pool : nodes.values()) {
FlowJob flowJob = context.getBean("flowJob", FlowJob.class);
flowJob.setPool(pool);
Future<?> future = rThreadPool.submit(flowJob);
futures.add(future);
}
for (Future<?> future : futures) {
try {
future.get(config.getTimeout(), TimeUnit.MINUTES);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
syncTime.update(end - start);
log.info("flow update finish ,total:" + nodes.size() + " redis nodes,use time " + (end - start)
+ " millisecond");
run = false;
}
});
}现有设计采用了同时从多个Master节点中并发获取key集合并分别针对于每个master节点进行操作,受限于JedisAPI第一步应该过滤掉非Master节点,对应的对一个master节点的所有”读取-删除”、”写数据库”操作应该保证在一个同步周期内完成。
@Override
public void run() {
Jedis jedis = null;
Set<String> keys = null;
String sha1 = null;
try {
jedis = pool.getResource();
String nodes = jedis.clusterNodes();
// 从节点放弃执行
if (nodes.contains("myself,slave")) {
return;
}
sha1 = jedis.scriptLoad(
"local num=redis.call('get',KEYS[1]); redis.call('del',KEYS[1]);if(not num) then return 0 ;else return num end;");
keys = jedis.keys(RedisKey.Flow.flow_prefix + ":*");
} finally {
if (jedis != null) {
try {
jedis.close();
} finally {
}
}
}
if (keys == null || sha1 == null) {
return;
}
log.info("thread:" + Thread.currentThread().getName() + "start update.");
long start = System.currentTimeMillis();
List<Task> tasks = new ArrayList<>();
for (String key : keys) {
String[] fields = key.split(":");
if (fields != null && fields.length == 6) {
String type = fields[5];
Task task = null;
if ("M".equals(type)) {
task = context.getBean("flowTaskM", FlowTaskM.class);
} else if ("H".equals(type)) {
task = context.getBean("flowTaskH", FlowTaskH.class);
} else if ("D".equals(type)) {
task = context.getBean("flowTaskD", FlowTaskD.class);
}
if (task != null) {
task.setPool(pool);
task.setSha1(sha1);
task.setKey(key);
tasks.add(task);
}
}
}
CountDownLatch countDownLatch = new CountDownLatch(keys.size());
for (Task task : tasks) {
task.setCountDownLatch(countDownLatch);
wThreadPool.execute(task);
requestRate.mark(keys.size());
}
try {
countDownLatch.await(config.getTimeout(), TimeUnit.MINUTES);
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
log.info("thread:" + Thread.currentThread().getName() + " finishd. record " + tasks.size() + ". used time "
+ (end - start) + " millisecond");
}内部作业的超时时间应该小于等于整个批次的超时时间
使用锁一定要特别小心,CountDownLatch一定要在你的资源不在变化的时候开始new,同时应该使得锁的释放操作尽可能的在一个非常狭小的范围finally中执行,否则是非常危险的,上面的代码块也正是先对资源进行预处理,避免在处理资源的过程中在多个地方释放锁.
资源的释放一定要及时,用完就释放,否则就是”占着茅坑不拉屎”对资源的极大浪费,try{}finally{}的时机一定要把握好,切记上来就是一个大大的try{}catch(){}finally{}
如果你不明白这块代码的深意,应该深深的思考一会儿
最后把数据更新到数据库里面去,这到底是一个插入?更新?更新-插入?很遗憾这里用了一个不太高效的做法”更新-插入”
public void run() {
try {
Jedis jedis = null;
long count = 0;
try {
jedis = pool.getResource();
count = Long.parseLong(jedis.evalsha(sha1, 1, key).toString());
} finally {
if (jedis != null) {
try {
jedis.close();
} finally {
}
}
}
if (count == 0) {
return;
}
String[] fields = key.split(":");
// get and delete flow key
// 前缀:卡口编号:压缩时间戳:方向编号:车道编号:标记位
FlowObject flow = new FlowObject();
flow.setKkbh(fields[1]);
flow.setRq(fields[2]);
//2018061320
flow.setXs(fields[2].substring(8,10));
flow.setCxfx(fields[3]);
flow.setCdbh(fields[4]);
flow.setType(fields[5]);
flow.setLl(count);
flow.setBh(key.substring(5));
int result = 0;
log.debug(flow);
result = jdbcTemplate.update(HUPDATESQL, new Object[] { flow.getLl(), flow.getBh() });
if (result < 1) {
log.debug("try update not exists .. execute install....");
result = jdbcTemplate.update(HINSERTSQL, new Object[] { flow.getBh(), flow.getKkbh(),
flow.getCdbh(), flow.getCxfx(), flow.getRq(), flow.getXs(), flow.getLl() });
}
} catch (Exception e) {
log.error(e);
} finally {
countDownLatch.countDown();
}
}可以使用缓存来确定是否要执行插入还是更新
可以等待以执行批量的更新、插入操作
资源的释放和锁的释放是有差别的,锁的释放一定要在真的确认需要被保护的事情已经完成了















 8181
8181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









