







 本文介绍了哈夫曼树的基本概念及其在数据压缩中的应用。通过构建哈夫曼树,可将频繁出现的数据用较短的二进制序列表示,从而实现高效的数据压缩。文章详细解释了构建哈夫曼树的过程,并演示了如何使用该树进行数据编码。
本文介绍了哈夫曼树的基本概念及其在数据压缩中的应用。通过构建哈夫曼树,可将频繁出现的数据用较短的二进制序列表示,从而实现高效的数据压缩。文章详细解释了构建哈夫曼树的过程,并演示了如何使用该树进行数据编码。
今天第一次接触到哈夫曼树,大概看了一遍,感觉太厉害了,忍不住 飙出了几个哇塞!哇塞! 哇塞! 然而仔细一想,就是那么一回事,只是我们还没想到而已,
在更好学习哈夫曼树之前,我们必须要先知道几个知识点。
1.bit(位)--->byte(字节)
带大家温习一下 计算机 如何存储数据的 , 计算机是很笨的 ,它只认识 0和1 ,相信各位应该都听说过吧! 如果它真的这么笨,那如何缔造出现在的互联网帝国呢 。那我们一起来见识一下吧!
首先 知道一下 bit--->byte 的关系。 8bit==1byte . 每个 bit 的位置只能是 0或者1, 也就是说 一个字节是由 8个不同顺序的 0和1 组成的 。
如 01001010 或者10110011 或者01110011 这样都算是一个字节,我们再想一下 , 8个 0和1 组成的状态 是不是有256中可能性呢 ? 就是2的8次方。 (这里扩展一下 ,如果一个字节里面可以记录256种可能,那是不是就可以知道,一个字节可以代表256个不同的字符, 在ASCII编码表中,就是放着256个字符对应256种状态,其中包含英文大小写各种符号,大家有兴趣可以去了解一下 ASCII)
说了这么多 ,就是让大家知道一下 ,一个字节 在计算机中是对应着8个bit的 。
下面我们来了解一下哈夫曼树
hello word hello word
上面这端字符串怎么变成一个哈夫曼树呢,是不是觉得很抽象? 不着急,我们慢慢庖丁解牛一下
首先看上面的字符串中是不是有很多重复的字母或者符号存在,这样存储或者传输是否很耗费空间,数据量多那是不是容量就很大啦 ,那有木有 优化的方法呢 。答案是肯定的 ,我们来实现一下吧 。
1.首先统计一下字符串的 重复出现次数、
h:2,e:2,l:4,o:4,空格:3,w:2,r:2,d:2
我再按照次数排序一下
h:2,e:2,w:2,r:2,d:2,空格:3,l:4,o:4
接下来 我们把这个排序好的集合变成哈夫曼树,又称最优的二叉树 记住哈夫曼树的一个特点 就是任何父节点都是空的
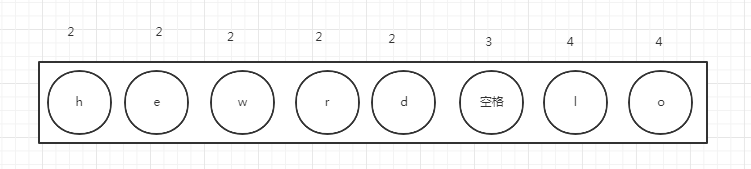
我们从最小数的两个元素来构建二叉树 第一步
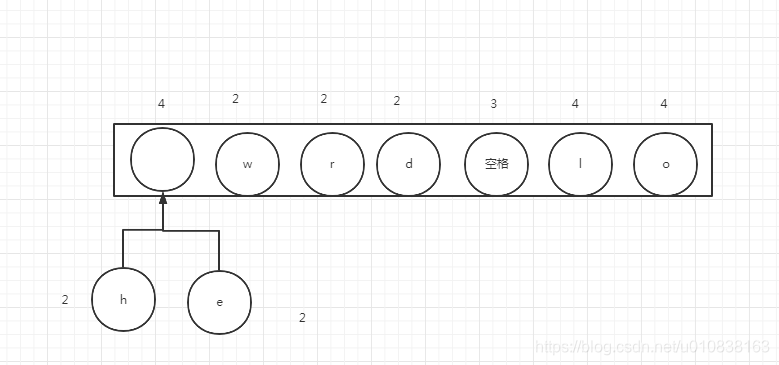
那前两个元素构建一个二叉树后,又将这个二叉树放回集合,这个二叉树的统计数等于子集合的总数,所有等于4 ,然后我们再排序一下
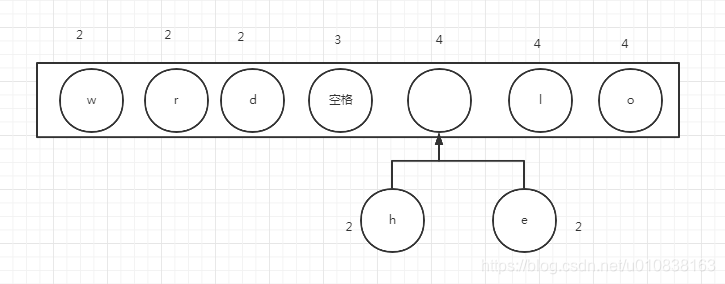
接下来我们再拿最前面的两个元素构建二叉树
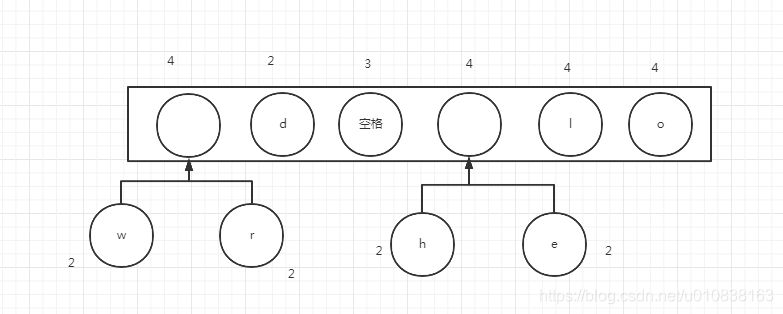
然后排序, 依次类推构成的最终二叉树
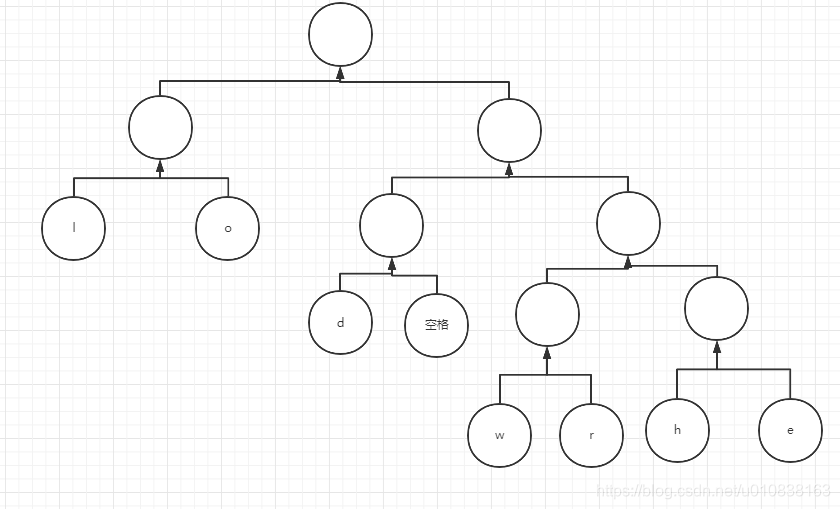
从这个二叉树中我们看到,出现频率多的元素 二叉树的层级是不是越小, 还有之前说过的,所有元素的节点 都是空的,为什么会这样呢 ,先给大家一个答案:保证一个元素在这颗树中唯一!
接下来我们给这颗树的 树枝指定 0和1 ,一个最小的二叉树只有两个子节点,那我们把左边的树枝定义为 0 右边的定义为1 :
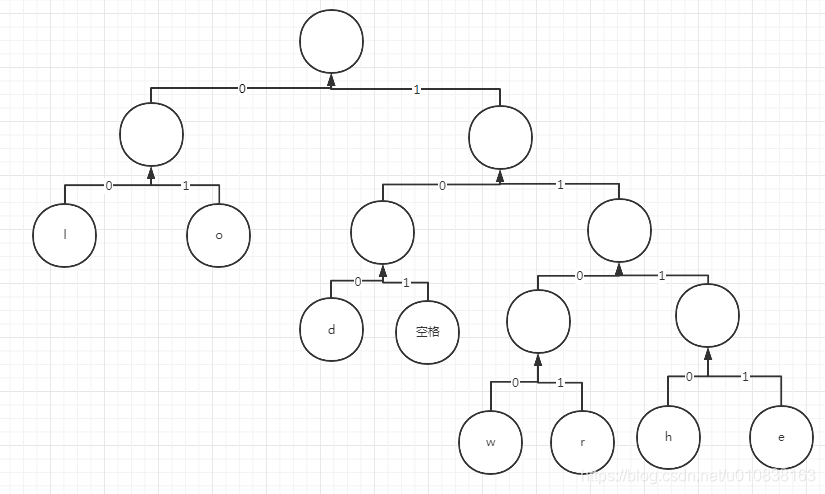
给这颗树标好树枝编号了, 那我们是不是可以通过树枝编号找到每个元素了。
l :00
o :01
d :100
空格 :101
w :1100
r :1101
h :1110
e :1111
咦!大家是不是有个疑问: 这么多 0和1 会不会找的时候会混乱呢 ,
这个不用担心,因为你从树上面找元素的时候,一个元素所经过的节点都是空的 ,所以一个元素的树枝组成都是唯一滴。
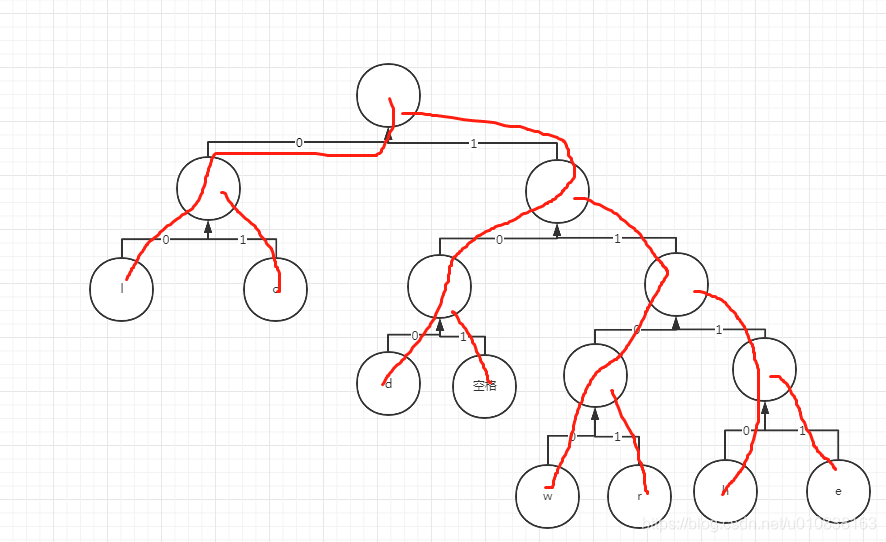
然后我们把上面的那段字符串通过树枝拼装一下:

然后我们把树枝来拼装一下
111011110000011011100011101100101111011110000011011100011101100
看到这么一串0和1组成的元素,大伙是不是想到了啥 ?
对,就是用bit 来标识 ,上面有64个0和1 那我们是不是正好装到 8*8个bit里面了 ,就是 8个字节,
我们看下原来的字符有多少个字节。
hello word hello word -----》 22个字节 ,
是不是很哇塞 一下减少了 2倍多。。 这样是不是我们是不是可以用来实现压缩功能啦。太棒了!!!
但是大家不要忘了一件事, 就是元素的字典,也就是刚才元素的统计集合, 我们在解压的时候,也要根据这个统计集合来还原数据哈 。
所以在数据量少的情况下 你用哈夫曼算法压缩 你的容量有可能还会变大。哈哈哈哈 !
不过不用担心,英文字母字符才有128个,常用的汉字不过才几千个 。汉字最多不过才几万个。
所以字符的字典肯定有限的, 你平常发现一个文件很小的时候,压缩发现没啥用 吧 。
所以内容越多,重复出现的字符越多,通过哈夫曼算法压缩后的内存节省比例就越高!
这是 本人这个对哈夫曼算法的理解和分析,如有不足或者错误之处,请大家多多指教,如有不明白的地方 可以评论留言,我们一起讨论一下哦 。这个是理论篇, 下一篇我将用c# 实现 哈夫曼算法实现压缩。 下期见咯 老铁们!!!

















 1924
1924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









