





- GPU设置
- 默认用全部GPU并且内存全部占满
- 避免内存不浪费
- 内存自增长
- 虚拟设备机制
- 多GPU使用
- 虚拟GPU&实际GPU
- 手工&分布式
- API列表
- tf.debugging.set_log_device_placement
- tf.config.experimental.set_visible_devices
- tf.config.experfimental.list_logical_devices
- tf.config.experfimental.list_phyical_devices
- tf.config.experfimental.set_memory_growth
- tf.config.experfimental.VirtualDeviceConfiguration
- tf.config.set_soft_device_placement 自动分配计算资源
- 分布式策略
-
MirroredStrategy
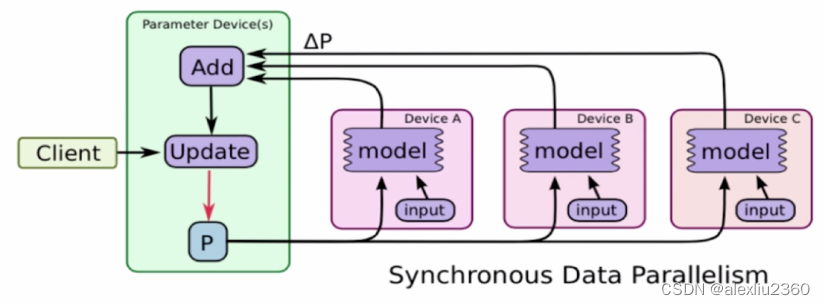
- 同步式分布式训练
- 适用于一机多卡
- 每个GPU都有网络结构的所有参数,这些参数会被同步
- 数据并行
- batch数据且为N分给各个GPU
- 梯度聚合然后更新给各个GPU上的参数
-
CentralStorageStrategy
- 参数不是每个GPU上,而是存储在一个设备上
- CPU或者唯一的GPU上
- 计算是在所有GPU上并行的
- 除了参数计算
- 参数不是每个GPU上,而是存储在一个设备上
-
MultiworkerMirroredStrategy
- 适用于多机多卡的情况
-
TPUStrategy
- 使用在TPU上的策略
-
ParameterServerStrategy 参数服务策略
-
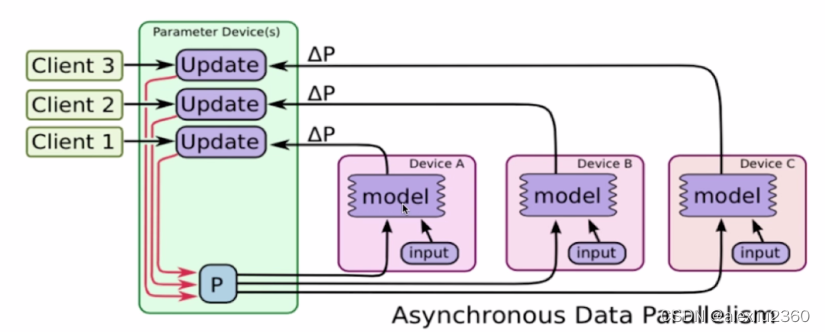
异步分布式
-
更加适用于大规模分布式系统
-
机器分为server和worker
-
-

-
-
同步异步的差异
- 多机多卡
- 异步可以便面短板效应
- 一机多卡
- 同步可以避免过多的通信
- 异步的计算会增加模型的泛化能力
- 异步不是严格正确的,所以模型更容忍错误
- 多机多卡
-
- nvidia相关命令
- nvidia-msi 查看GPU运行情况
- watch -n 0.1 -x nvidia-smi 监控nvidia-smi命令
【tf2-基础】分布式训练
最新推荐文章于 2023-10-09 09:15:29 发布
















 3927
3927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









