







一图胜千言!
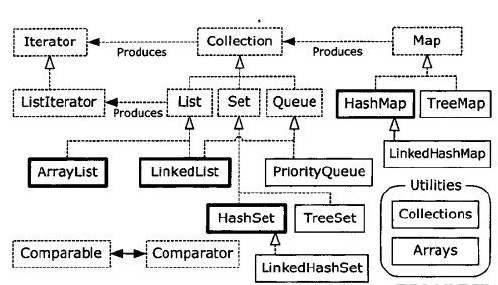
从容器类图中可以发现,数据容器主要分为了两类:
Collection: 存放独立元素的序列。
Map:存放key-value型的元素对。(这对于一些需要利用key查找value的程序十分的重要!)
在使用时,应该根据不同的适用场景灵活的进行选择!
Map
-HashMap 提供了key-value的键值对数据存储机制,可以十分方便的通过键值查找相应的元素,
而且通过Hash散列机制,查找十分的方便。不支持线程的同步.
-LinkedHashmap 保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,
先得到的记录肯定是先插入的。在遍历的时候会比HashMap慢。有HashMap的全部特性。
-TreeMap 能够把它保存的记录根据键排序,默认是按升序排序,也可以指定排序的比较器。
当用Iteraor遍历TreeMap时,得到的记录是排过序的。TreeMap的键和值都不能为空。
-ConcurrentHashMap 支持线程的同步。
Collection
-List(有序列表)
-LinkedList 其数据结构采用的是链表,此种结构的优势是删除和添加的效率很高,
但随机访问元素时效率较ArrayList类低。
-ArrayList 其数据结构采用的是线性表,此种结构的优势是访问和查询十分方便,
但添加和删除的时候效率很低。
-Set(无序且唯一)
-HashSet HashSet利用Hash函数进行了查询效率上的优化,其contain()方法经常被使用,
以用于判断相关元素是否已经被添加过。
-LinkedHashSet 介于HashSet和TreeSet之间。它也是一个hash表,但是同时维护了一个双链表
来记录插入的顺序。保证输入和输出的顺序,该顺序恒久不变。
-TreeSet 采用树结构实现(红黑树算法)。元素是按顺序进行排列。TreeSet支持两种排序方式,
自然排序 和定制排序,其中自然排序为默认的排序方式。
Queue(队列)
-LinkedList 同上
-PriorityQueue 本质上就是堆排序里面建的最小堆。对入队的元素进行排序,
所以在队列顶端的总是最小的元素。















 2961
2961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









