







【原文链接:https://blog.csdn.net/qq_31329893/article/details/90451889】
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/qq_31329893/article/details/90451889
在对kafka的理解中,常常会被问及到kafka如何保证数据的顺序消费、kafka的数据重复消费怎么处理、如何保证kafka中数据不丢失?今天先说说数据的顺序消费问题。
关于顺序消费的几点说明:
①、kafka的顺序消息仅仅是通过partitionKey,将某类消息写入同一个partition,一个partition只能对应一个消费线程,以保证数据有序。
②、除了发送消息需要指定partitionKey外,producer和consumer实例化无区别。
③、kafka broker宕机,kafka会有自选择,所以宕机不会减少partition数量,也就不会影响partitionKey的sharding。
那么问题来了:在1个topic中,有3个partition,那么如何保证数据的消费?
1、如顺序消费中的第①点说明,生产者在写的时候,可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
2、消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。
3、但是消费者里可能会有多个线程来并发来处理消息。因为如果消费者是单线程消费数据,那么这个吞吐量太低了。而多个线程并发的话,顺序可能就乱掉了。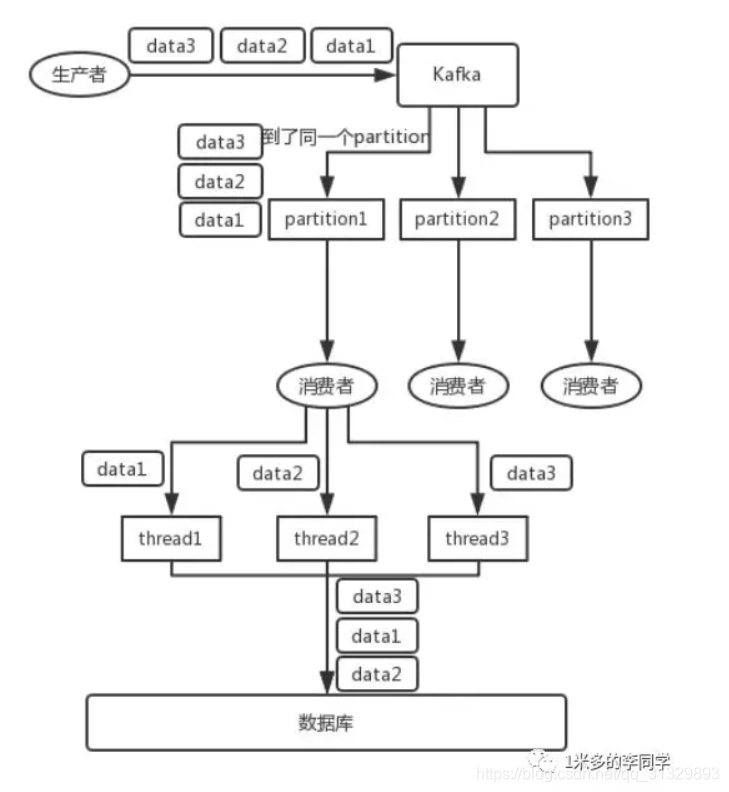
解决方案:
写N个queue,将具有相同key的数据都存储在同一个queue,然后对于N个线程,每个线程分别消费一个queue即可。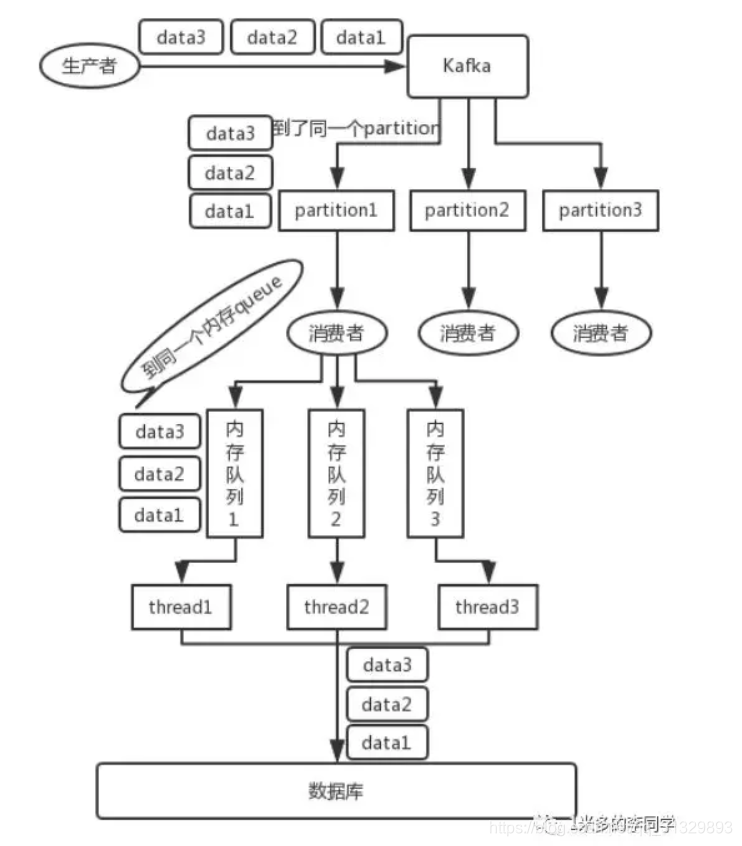
注:在单线程中,一个 topic,一个 partition,一个 consumer,内部单线程消费,这样的状态数据消费是有序的。但由于单线程吞吐量太低,在数据庞大的实际场景很少采用。














 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









