



 当Python尝试用GBK编码读取非GBK格式的CSV文件时,会引发UnicodeDecodeError。解决方法是将CSV文件转换为UTF-8编码,然后在Python代码中使用utf-8编码读取文件,避免解码错误。
当Python尝试用GBK编码读取非GBK格式的CSV文件时,会引发UnicodeDecodeError。解决方法是将CSV文件转换为UTF-8编码,然后在Python代码中使用utf-8编码读取文件,避免解码错误。
一、问题描述
python读取csv文件,结果报错:‘UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xfe in position 683: illegal multibyte sequence’。
with open('my_data.csv', 'r') as f:
reader = csv.reader(f)
headers = next(reader) # skip header row
batch = []
二、问题原因
这个错误通常是由于CSV文件的编码格式与Python代码的编码格式不匹配导致的。实际读取文件,默认是GBK。
with open('my_data.csv', 'r') as f:
reader = csv.reader(f)
headers = next(reader) # skip header row
batch = []
而实际csv文件,外面传来的可能是一些其他编码,而GBK无法完全解析。导致报错。
三、解决办法
将文件和代码的编码格式统计
1.将csv文件保存为UTF-8。
2.python代码通过utf-8编码读取csv文件
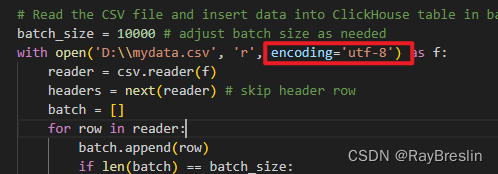
with open('my_data.csv', 'r', encoding='utf-8') as f:



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









