







一、前言
系统设计:电商系统设计到开发01 第一版设计到编码-CSDN博客
接着上篇文章:电商系统设计到开发02 单机性能压测-CSDN博客
本篇为大制作,内容有点多,也比较干货,希望可以耐心看看
已经开发的代码,并对其下单接口进行了压力测试压力测试,该接口一个请求需要查询数据库4次,更新4次 ,插入2次,总共访问数据库10次,其中2个事务,3次查询是加锁查询,还有 1 次 rpc 请求,单实例情况下吞吐量为110/s
今天我们将其引入Kafka,看看吞吐量会有多少的提升,又会引入什么新的问题呢?
Kafka的安装流程:SpringBoot3.1.7集成Kafka和Kafka安装-CSDN博客
二、流程图
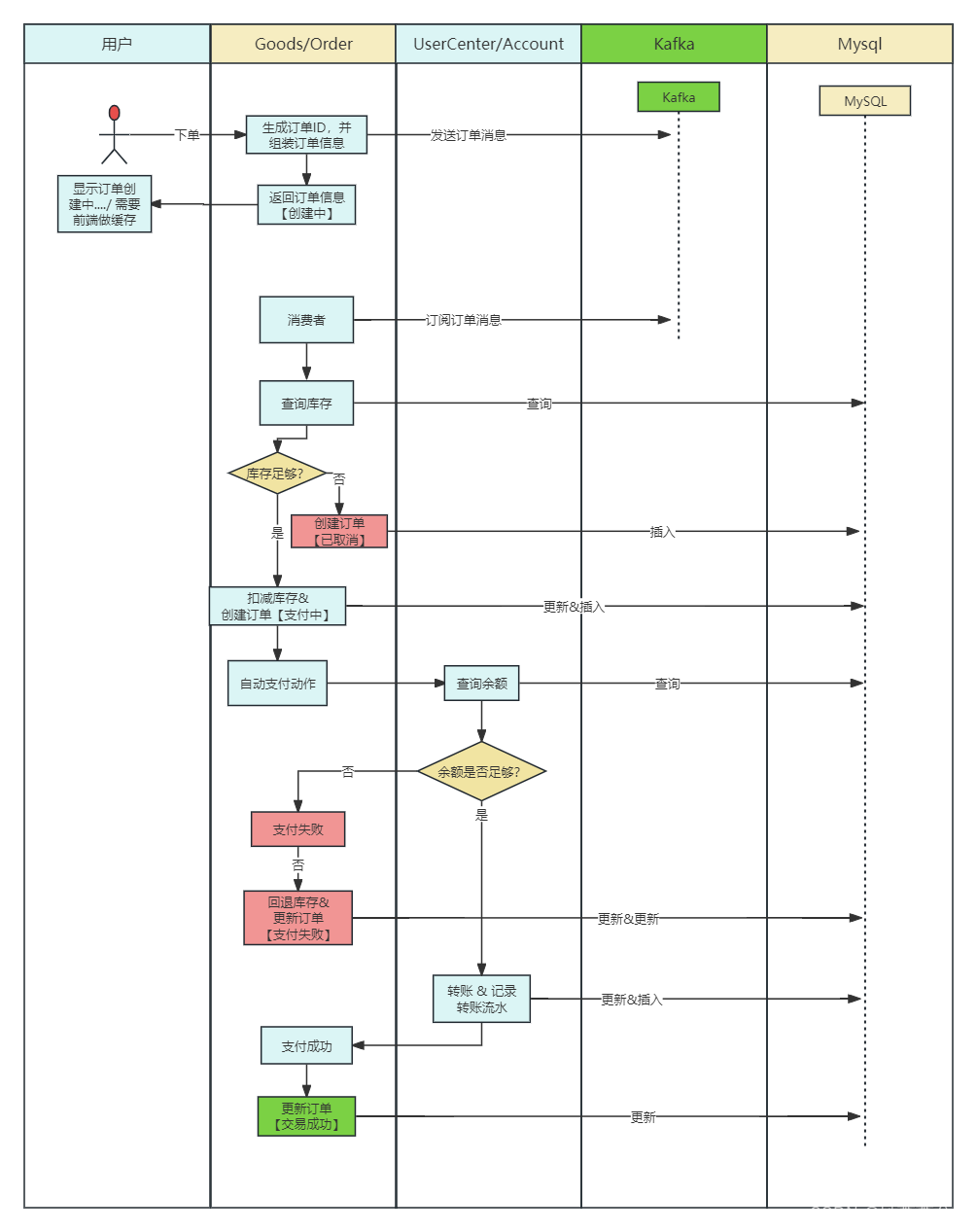
三、要求
保证消息的精准一次,不能多下单,也不能少下单
因为订单提交改成了异步创建,那么后端不会立即返回下单结果,所以一般需要前端也配合着改动,我们现在暂时不考虑前端的具体实现,但是另外一个问题就是消息要做到精准一次,不能多下订单,也不能少下订单,后面我们会进行破坏性测试,然后验证是否可以做到保证消息的精准一次
1 生产者保证消息不丢失
配置生产者的acks = all (表示要等到Kafka集群中所有的isr队列里的的broker落盘以后才返回确认)
2 kafka集群保证消息不丢失
要保证服务器不丢消息:min.insync.replicas 要设置为>1 (只要不是2台服务同时宕机就不会丢消息) Kafka 2.6.0 版本引入了针对 Topic 的 min.insync.replicas 配置,允许您为每个 Topic 单独设置 ISR 的最小副本数。在这之前,min.insync.replicas 配置是全局的,适用于所有 Topic。
3 消费者保障消息不丢失
取消自动提交offset,spring: kafka: consumer:enable:auto:commit: false ,等消息成功消费后手动提交消息的offset
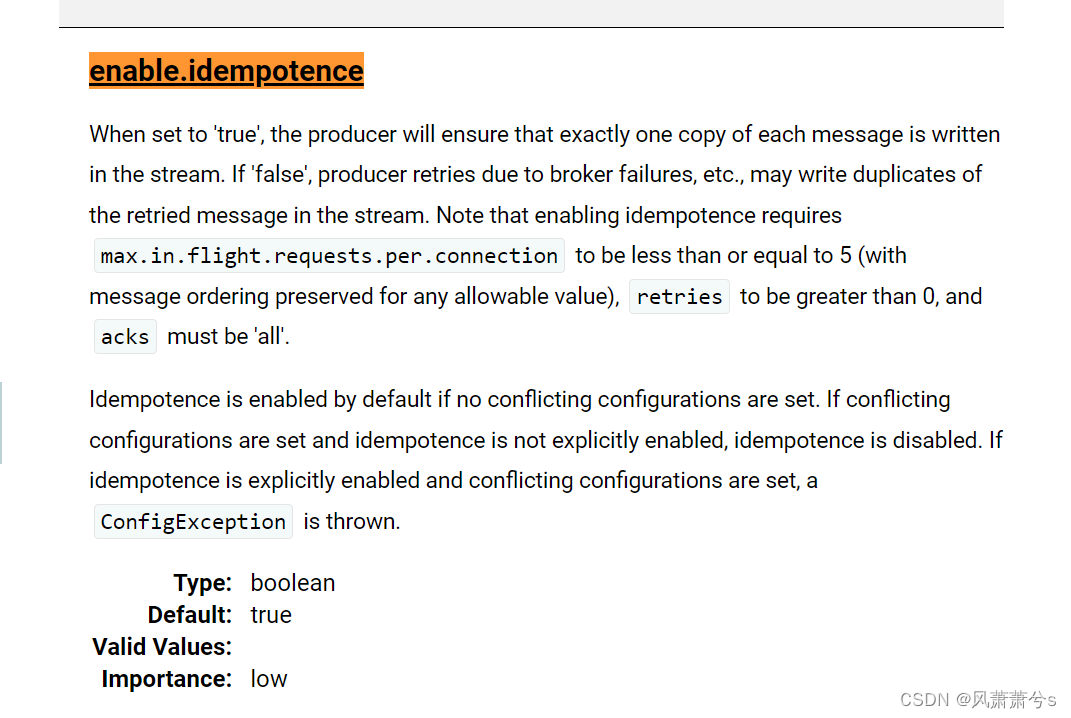
4 保证消息不多发
enable.idempotence(生产者配置)可以保证消息不多发(默认是true,可以不用配置)
四、Kafka集群服务端配置
条件有限,我暂时在一台1核2G的Centos虚拟机上面配置并启动3个Kafka实例实现伪分布式集群,启动模式采用的是Kraft模式,Kafka集群端口分别为9093,9193,9293
1 复制3分Kafka实例

2 配置服务配置
kafka00/config/kraft/server.properties


kafka01/config/kraft/server.properties


kafka02/config/kraft/server.properties


3 初始化Kafka
先生成一个集群ID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"然后分别在Kafka00、Kafka01、Kafka02的目录下执行下面初始化命令
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties


确认一下,他们3个的集群ID是否相同

4 启动Kafka集群
编写启动脚本
nohup kafka00/bin/kafka-server-start.sh kafka00/config/kraft/server.properties >kafka00/out.log 2>&1 &
nohup kafka01/bin/kafka-server-start.sh kafka01/config/kraft/server.properties >kafka01/out.log 2>&1 &
nohup kafka02/bin/kafka-server-start.sh kafka02/config/kraft/server.properties >kafka02/out.log 2>&1 &执行,启动成功了

5 创建一个订单topic
找到Kafka目录,输入bin/kafka-topics.sh,如果不知道如何填参数,可以先按下回车,会列举所有的参数选项,我这边创建一个topic名称为order-message-topic,分区数为2,副本为3
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic order-message-topic --partitions 2 --replication-factor 3 --config min.insync.replicas=2 创建完成,我们看一眼刚刚已创建的topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic order-message-topic
这里有个小插曲:
本来想安装一个Kafka的可视化界面,因为我使用的是去zookeeper化的Kraft模式启动,市面上居然还没有支持这种模式的界面,看看Kafka-manager CMAK 已经在催更了

五、应用程序开发
1 配置Kafka参数到应用程序的application.yml
spring:
kafka:
bootstrap-servers: 192.168.31.114:9092,192.168.31.114:9192,192.168.31.114:9292
producer:
acks: all
timeout.ms: 5000
retries: 3
# 值序列化:使用Json
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
key-serializer: org.apache.kafka.common.serialization.LongSerializer
enable:
idempotence: true # 默认为True
# 因为消费者需要更加细粒度的控制,所以单独写配置文件
kafka-consumer:
bootstrapServers: 192.168.31.114:9092,192.168.31.114:9192,192.168.31.114:9292
groupId: goods-center
#后台的心跳线程必须在30秒之内提交心跳,否则会reBalance
sessionTimeOut: 30000
autoOffsetReset: latest
#取消自动提交,即便如此 spring会帮助我们自动提交
enableAutoCommit: false
#自动提交间隔
autoCommitInterval: 1000
#拉取的最小字节
fetchMinSize: 1
#拉去最小字节的最大等待时间
fetchMaxWait: 500
maxPollRecords: 100
#300秒的提交间隔,如果程序大于300秒提交,会报错
maxPollInterval: 300000
#心跳间隔
heartbeatInterval: 10000
keyDeserializer: org.apache.kafka.common.serialization.LongDeserializer
valueDeserializer: org.springframework.kafka.support.serializer.JsonDeserializer2 编写生成者代码发送订单信息
kafkaTemplate.send 方法采用的是异步发送,先将消息发送到缓冲区,然后再批量打包异步发送出去,从而提高Kafka的性能,但是这样操作,可能会导致消息的丢失,然后前端认为消息已经发送出去了,解决这种方式,可以采用同步等待消息发送的结果,代码如下
package com.ychen.goodscenter.fafka;
import com.ychen.goodscenter.vo.req.SubmitOrderReq;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import java.util.concurrent.CompletableFuture;
@Component
@Slf4j
public class MessageProducer {
@Autowired
private KafkaTemplate<Long, SubmitOrderReq> kafkaTemplate;
public void sendOrderMessageSync(SubmitOrderReq msg) {
CompletableFuture<SendResult<Long, SubmitOrderReq>> future =
kafkaTemplate.send(TopicConstants.ORDER_MESSAGE_TOPIC, msg.getOrderId(), msg);
try {
// 同步等待发送结果
SendResult<Long, SubmitOrderReq> result = future.get();
// 处理成功发送的情况
log.info("order-message-topic message send successfully: " + result.getRecordMetadata().toString());
} catch (Exception e) {
// 处理发送失败的情况
log.info("order-message-topic message send error message: " + e.getMessage());
throw new RuntimeException(e);
}
}
}
package com.ychen.goodscenter.controllers;
import com.ychen.framework.utils.Result;
import com.ychen.framework.utils.SnowFlakeUtils;
import com.ychen.goodscenter.entity.OrderInfo;
import com.ychen.goodscenter.fafka.MessageProducer;
import com.ychen.goodscenter.service.OrderService;
import com.ychen.goodscenter.vo.req.SubmitOrderReq;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class OrderController {
@Autowired
private MessageProducer messageProducer;
@PostMapping("/submitOrderAsync")
public Result submitOrderAsync(@RequestBody SubmitOrderReq req) {
// 生成订单ID,消息幂等处理
req.setOrderId(SnowFlakeUtils.nextId());
messageProducer.sendOrderMessageSync(req);
return Result.ok();
}
}
3 编写消费者代码
为了更加细粒度的控制消费者的消费失败处理,所以单独写配置文件,并且通过自定义KafkaListenerContainerFactory的方式实现
- 手动提交
- 消息消费失败重试3次
- 重试3次仍然失败后会将消息保存到Kafka的死信队列
KafkaConsumerProperties
package com.ychen.goodscenter.fafka;
import lombok.Getter;
import lombok.Setter;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
@Configuration
//指定配置文件的前缀
@ConfigurationProperties(prefix = "kafka-consumer")
@Getter
@Setter
public class KafkaConsumerProperties {
private String groupId;
private String sessionTimeOut;
private String bootstrapServers;
private String autoOffsetReset;
private boolean enableAutoCommit;
private String autoCommitInterval;
private String fetchMinSize;
private String fetchMaxWait;
private String maxPollRecords;
private String maxPollInterval;
private String heartbeatInterval;
private String keyDeserializer;
private String valueDeserializer;
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
// 服务器地址
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 是否自动提交
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
// 自动提交间隔
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
//会话时间
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeOut);
//key序列化
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer);
//value序列化
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);
// 心跳时间
propsMap.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, heartbeatInterval);
// 分组id
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
//消费策略
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
// poll记录数
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecords);
//poll时间
propsMap.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, maxPollInterval);
propsMap.put("spring.json.trusted.packages", "com.ychen.**");
return propsMap;
}
}KafkaConsumerConfig
package com.ychen.goodscenter.fafka;
import com.alibaba.fastjson2.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.listener.*;
import org.springframework.util.backoff.BackOff;
import org.springframework.util.backoff.FixedBackOff;
import java.util.Map;
@Configuration
@EnableConfigurationProperties(KafkaConsumerProperties.class)
@Slf4j
public class KafkaConsumerConfig {
@Autowired
private KafkaConsumerProperties kafkaConsumerProperties;
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 并发数 多个微服务实例会均分
factory.setConcurrency(2);
// factory.setBatchListener(true);
factory.setCommonErrorHandler(commonErrorHandler());
ContainerProperties containerProperties = factory.getContainerProperties();
// 是否设置手动提交
containerProperties.setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
private ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> consumerConfigs = kafkaConsumerProperties.consumerConfigs();
log.info("消费者的配置信息:{}", JSONObject.toJSONString(consumerConfigs));
return new DefaultKafkaConsumerFactory<>(consumerConfigs);
}
public CommonErrorHandler commonErrorHandler() {
// 创建 FixedBackOff 对象
BackOff backOff = new FixedBackOff(5000L, 3L);
DefaultErrorHandler defaultErrorHandler = new DefaultErrorHandler(new DeadLetterPublishingRecoverer(kafkaTemplate), backOff);
return defaultErrorHandler;
}
}
MessageListener
package com.ychen.goodscenter.fafka;
import com.ychen.goodscenter.service.OrderService;
import com.ychen.goodscenter.vo.req.SubmitOrderReq;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.dao.DuplicateKeyException;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class MessageListener {
@Autowired
private OrderService orderService;
@KafkaListener(topics = TopicConstants.ORDER_MESSAGE_TOPIC, containerFactory = "kafkaListenerContainerFactory")
public void processMessage(ConsumerRecord<Long, SubmitOrderReq> record, Acknowledgment acknowledgment) {
log.info("order-message-topic message Listener, Thread ID: " + Thread.currentThread().getId());
try {
log.info("order-message-topic message received, orderId: {}", record.value().getOrderId());
orderService.submitOrder(record.value());
// 同步提交
acknowledgment.acknowledge();
log.info("order-message-topic message acked: orderId: {}", record.value().getOrderId());
} catch (DuplicateKeyException dupe) {
// 处理异常情况
log.error("order-message-topic message error DuplicateKeyException", dupe);
// 重复数据,忽略掉,同步提交
acknowledgment.acknowledge();
}
}
}六、整体并发测试
接着上次的测试进行改正:电商系统设计到开发02 单机性能压测-CSDN博客
1 数据准备
用户数:100w,用户ID 1~100_0000,每个用户余额 10w
商品数:100w,商品ID 1~100_0000, 单价都为1元,数量均为1亿件,商家ID均为 100
模拟:1w个用户同时抢购同一件商品
通过查询订单数,账户总金额来核对来验证程序是否正确
测试前总金额为1000 0000 0000

通过查看Jmeter的聚合报告看接口的吞吐量
2 机器准备
我的本地window电脑作为测试机器(i7 13代处理器,32G内存+1T固态硬盘)
使用Wmware 虚拟了4台Centos机器分别是
Centos00 ,1CPU + 2G内存+ 20G固态硬盘 | 部署 Consul server,Sentinel Dashboard
Centos01 ,1CPU + 1G内存+ 20G固态硬盘 | 部署 MySQL5.7.44
Centos02 ,1CPU + 1G内存+ 20G固态硬盘 | 部署 user-center
Centos03 ,1CPU + 1G内存+ 20G固态硬盘 | 部署 goods-center
Centos04 ,1CPU + 3G内存+ 20G固态硬盘 | 部署 kafka3.5 kraft 3个broker集群模式
3 压测脚本
随机1w个用户,模拟下订单操作
4 压测 (10000个样本)
100个线程,循环100次

查看结果:
数据库 10000个订单,符合预期,总金额1000 0000 0000符合预期,程序没有问题


聚合报告 (用户请求的吞吐量为295)

kafka消费者总耗时:480秒
吞吐量 = 10000/480 = 20.8
5 压测总结
下图为没有使用kafka100个线程并发下单的接口测试报告

对比上次没由使用kafka的接口,用户吞请求吐量增加了将近3倍,平均响应时间下降为原来的1/3
但是业务吞吐量,却只有原来的1/5 不到,从查看消费者日志我们可以看到,因为只有一台消费者且用的都是同一个线程,自然吞吐量会很低,下一步,我们考虑如何提升消息吞吐量

七、提升生产者吞吐量
说明:每一步性能的提升,都可能会导致数据安全性的减少
1 生产者相应同步改异步
为了不受消费者影响,我们在启动程序时,先注销消费者代码
单独测试只有生产者代码时的吞吐量,另外加大线上数和循环次数,让差距更加明显一点
采用200线程,200次循环

改造代码,改成默认的异步发送到Kafka,这个改动将有丢失消息的风险
改造前
public void sendOrderMessageSync(SubmitOrderReq msg) {
CompletableFuture<SendResult<Long, SubmitOrderReq>> future =
kafkaTemplate.send(TopicConstants.ORDER_MESSAGE_TOPIC, msg.getOrderId(), msg);
try {
// 同步等待发送结果
SendResult<Long, SubmitOrderReq> result = future.get();
// 处理成功发送的情况
log.info("order-message-topic message send successfully: " + result.getRecordMetadata().toString());
} catch (Exception e) {
// 处理发送失败的情况
log.info("order-message-topic message send error message: " + e.getMessage());
throw new RuntimeException(e);
}
}改造后
public void sendOrderMessage(SubmitOrderReq msg) {
log.info("order-message-topic message sending, orderId: {}", msg.getOrderId());
kafkaTemplate.send(TopicConstants.ORDER_MESSAGE_TOPIC, msg.getOrderId(), msg);
log.info("order-message-topic message sent, orderId: {}", msg.getOrderId());
}改造前吞吐量595

改造后吞吐量663

这种改造提升不明显,吞吐量有微量的提升,不过中位数时延降的比较明显(毕竟是异步立即返回)
2 生产者ack = all 改成ack = 1
表示只要只要master收到消息并落盘就可以返回了
改造前吞吐量595
改造后吞吐量616

提升不是很明显,可能是因为我使用的是伪集群模式,3台实例都部署在同一个虚拟机中
八、提升消费者吞吐量
这一步,没有部署监视器(前面说了使用Kraft模式部署,太新了,目前可部署的监控还没找到),只能我使用手动计时测试
统计5分钟,数据库生成的订单数
改造前,我们使用之前已经测试过的吞吐量数据 20
1 增加并发数
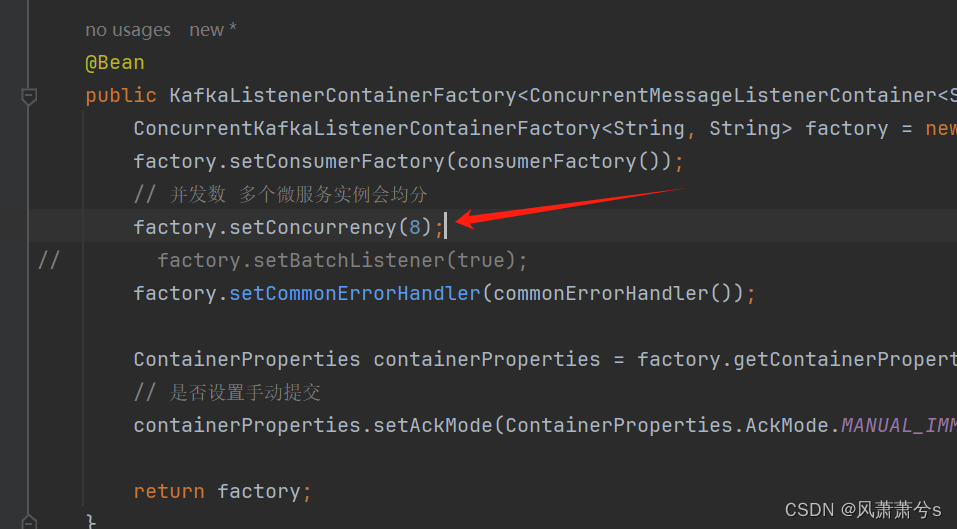
执行5分钟后,生成的订单数为:10114
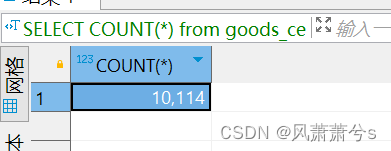
吞吐量为: 10114 / 300 = 33
原因:因为我创建分区的时候指定的分区数为2,那么即使并发数设置为8,那么也最多只能运行2个线程消费,从下面日志中能验证这一点

2 增加topic分区数
将分区数从2个增加到8个,执行下面命令
bin/kafka-topics.sh --bootstrap-server localhost:9092 --alter --topic order-message-topic --partitions 8然后发送一些消息到新的分区用于测试

消息准备的好了,清空数据库的订单,开始测试,这次有8个线程进行消费了

测试结果:
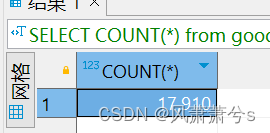
吞吐量为: 17910/ 300 = 59
原因:比原来的20吞吐量,已经提升了将近3倍,没有引入Kafka的情况下吞吐量为110,毕竟只有8个线程消费,最高吞吐量的线程数量
3 提交offset改成批量提交
代码改动如下:
// 改动前
containerProperties.setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
// 改动后
containerProperties.setAckMode(ContainerProperties.AckMode.MANUAL);在本章第2步的基础上改进的,所以一会对比第2步
测试结果:

吞吐量为: 18269/ 300 = 60
原因:相对第二步提升不明显,理论上能提升一点点,但是不明显
4 增加消费者机器消费
仍然是8个分区,由原来1台实例,改成现在2台实例,看看吞吐量
在本章第3步的基础改动
测试结果:
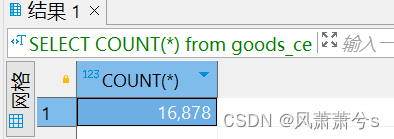
吞吐量为: 16878/ 300 = 56
原因:可能是我本地Window的机器消费能力不如Linux虚拟机的消费能力,但是大致看上去,启动2台实例去消费8个分区和启动一台实例开启8个线程去消费8个分区的消费能力是差不多的,当然需要的条件是吞吐量瓶颈不在CPU资源和网络资源上,我的推断我的程序的瓶颈在于数据库,那么8个线程用到的数据库连接数为8个,那么这8个线程决定了吞吐量的大小,为了验证这一猜想,我决定还是增加一小节,将分区数增加到20,并发数增加到20
5 增加分区和并发数为20
20个分区的数据准备好了,接下来开始测试吧

测试结果:
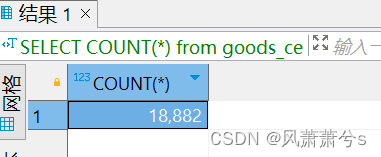
吞吐量为: 18882/ 300 = 62
原因:相比于第3步,增加的不是很明显,说明再提升并发数,性能已经不是很明显了,说明瓶颈不是在这里,要继续优化,估计只能从代码处入手了。















 1288
1288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









