







这一章,我们一起来看系统编程里最重要的话题的第一个即进程的概念以及它的结构,会深入了解进程虚拟内存的内容,并且我们会检查一些额外的进程属性。在后面章节中我们还会继续探讨关于进程权限(第9章),进程优先级以及调度的问题在第35章。在第24到第27章,我们会继续深入如何创造进程,如果终结进程以及如果使用它们来执行新的程序。
6.1 进程和程序
一个进程是一个执行的程序的实例。在这部分当中,我们会解释进程的定义,并且会讲解 程序和进程的区别。
一个program是一个包含了一些列信息用来描述如何在runtime的时候构建一个进程。信息包含:
- Binary format identification: 每一个程序文件包含了元信息(meta information)来描述该执行文件的格式,该信息可以使得内核可以解释文件的剩余的信息。历史上来讲,两个广泛用于在UNIX上可执行的程序类型是a.out或者时后来更成熟一些的COFF(common object file format)。现在大多数UNIX(包括Linux)都喜欢使用ELF(Executable and Linking Format)。
- Machine-language instructions:指令编码程序算法
- Program entry-point address: 记录执行程序开始指令的位置
- Data:程序文件包含用于初始化变量的值并且他们会被以常量的形式在程序中使用。
- Symbol和relocation tables:描述了在程序中函数和变量的位置以及名字。表用于多种目的,包括debug以及runtime中的符号解析(动态链接)
- shared-library和dynamic linking information:程序文件包括列出程序在runtime需要使用的共享库的fields还有用于加载这动态库的文件名
- 其他信息
一个程序可以被用于构建任何进程,或者说多个进程都有可能运行同一个程序。这里我们可以这样描述进程:进程是一个由kernel定义的抽象实体,它可以被分配系统资源而来执行程序。
从kernel的观点来看,一个进程由用户空间内存里的程序代码以及变量所组成,并且一系列内核数据结构用来维持该进程的信息,其中包含了多个与该进程相关的ID,虚拟向量表以及打开文件的FD,信号传递信息和处理,进程资源使用情况以及限制,目前的工作文件夹以及host等信息。
6.2 进程ID和母进程ID
每一个进程都拥有一个进程ID(PID),它是一个正整数并且在这个系统里是唯一。进程ID会被很多系统调用使用或者返回。比如说kill()就会允许调用者发送一个信号给想要关闭的进程ID所对应的进程来达到kill该进程的目的。
读取进程ID的方法如下,并且该方法总是会成功返回调用进程ID
#include <unistd.h>
pid_t getpid(void);除过一些特殊的系统进程,比如init(PID 1)总是初始化系统的进程外,其余的用来运行程序的进程ID和该程序并没有必然联系。
Linux内核限制进程ID数量小于或者等于32767。当一个进程被创建的时候,它会被赋予顺序上下一个可用的PID号。但是当PID号码到达32767的时候,它就会从头找最小的还未被赋予的PID号码(当然,事实上它会从PID300开始重新开始查找而非1,原因是有大量系统常用PID号码都是在300以内,如果从0开始会发现总是需要经常到300以后才开始有可用的号码,所以是为了避免浪费资源所以这么设计的)。但是对于64位系统而言,这个最大进程号可能是大约400万左右。
每一个进程都会有一个母进程,并且由该母进程创建。如果想要知道自己的母进程的号码,可以使用以下方法读取:
#include <unistd.h>
pid_t getppid(void);事实上,因为有母进程ID这种特性的存在,所以所有的进程都是以树状结构存在在该系统当中,因为每一个最终的进程节点都可以向上回溯到最初的那一个进程也就是process 1。
当然进程的母进程是可以被终结的。一旦当一个进程的母进程被终结后,该进程就会自动被原初进程process 1所“领养”,这时候如果调用getppid()的话就会得到1。
任何进程的母进程都可以在查找/proc/PID/status 的 ppid field而找到。下面是我的Linux系统底下的一个例子
Name: kworker/3:0-events
Umask: 0000
State: I (idle)
Tgid: 29275
Ngid: 0
Pid: 29275
PPid: 2
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 32
Groups:
NStgid: 29275
NSpid: 29275
NSpgid: 0
NSsid: 0
Threads: 1
SigQ: 0/28771
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: ffffffffffffffff
SigCgt: 0000000000000000
CapInh: 0000000000000000
CapPrm: 0000003fffffffff
CapEff: 0000003fffffffff
CapBnd: 0000003fffffffff
CapAmb: 0000000000000000
NoNewPrivs: 0
Seccomp: 0
Speculation_Store_Bypass: unknown
Cpus_allowed: 8
Cpus_allowed_list: 3
Mems_allowed: 1
Mems_allowed_list: 0
voluntary_ctxt_switches: 1201
nonvoluntary_ctxt_switches: 14
6.3 进程的内存分布
每一个给进程被分配的内存空间都是由很多部分所组成,通常他们被称之为段segments。这里不仅仅是linux系统这样,实际上任何一种RTOS也都是这样。个人认为这一段非常重要,因为很多时候有一些系统对安全性要求比较高的时候,会明确需要知道什么东西在什么位置,并且绝对不允许相互能够使用非自己有权限的地址的时候。
段通常又被细化而且表达成:
- text segment,这个包含了被进程运行的程序的机器码指令。text segment是一个进程只读的区域,并且不可能被坏指令或者内部指令所修改。这也是为什么多个进程可以运行同一个program的原因,同一个program的单次在内存中的拷贝可以被映射到所有执行它的进程的虚拟地址当中。
- initialized data segment,它包含了被显式初始化的全局和静态变量。当program被加载到内存的时候,这些变量的值也会被从可执行文件当中读取出来。
- unitialized data segment,包含了未被显式初始化的全局和静态变量。在启动程序之前,系统会将在该段内的所有内存都初始化位0。由于历史的原因,这个部分会经常被称之为bss段,一个来源于以前汇编中的“block started by symbol”的历史名称。至于为什么要将上面被初始化和这里未被初始化的全局和静态变量分开放在两个segment的原因是,当程序存储在磁盘上时,我们并不需要为未被初始化的变量分配空间。可执行程序只需要记录上未初始化数据segment所需要的位置和大小即可,并且这个空间只有在程序加载的时候才会被分配在内存上。
- stack,栈是一个动态生长减小的段。一个栈的一个frame即是为现在被调用的函数所分配的空间。这个被分配的frame里包含了函数的临时本地变量(也就是经常听到的所谓的automatic variables),参数以及返回值。在6.5章当中我们会进一步讨论关于栈的内容。
- heap,堆是一个可以在运行过程中被动态分配的区域(为变量)。heap的顶被称之为program break。
剩下用的比较少,但是对初始化和未被初始化数据段更具有描述性标签还有user-initialized data segment还有zero-initialized data segment。
size(1) (使用man 1 size查阅)可以用来帮助查阅一个二进制程序的指令段大小,初始化数据大小,未初始化数据段大小(bss)。效果如下:
pi@raspberrypi:~/sysprog/learn_tlpi/build $ size out
text data bss dec hex filename
5589 884 12 6485 1955 out
书中给出了一个非常好的例子,C语言文件中的注释会说明在选择非优化模式下编译该程序的话,内存分配情况。但是实际当中,如果是以release为目的的编译器的话,一定会使用优化型比那一起来分配常用变量到寄存器当中或者可能会优化掉一些不用的变量。proc/mem_segments.c (from "The Linux Programming Interface")
#define _BSD_SOURCE
#include <stdio.h>
#include <stdlib.h>
char globBuf[65536]; /* Uninitialized data segment */
int primes[] = { 2, 3, 5, 7 }; /* Initialized data segment */
static int
square(int x) /* Allocated in frame for square() */
{
int result; /* Allocated in frame for square() */
result = x * x;
return result; /* Return value passed via register */
}
static void
doCalc(int val) /* Allocated in frame for doCalc() */
{
printf("The square of %d is %d\n", val, square(val));
if (val < 1000) {
int t; /* Allocated in frame for doCalc() */
t = val * val * val;
printf("The cube of %d is %d\n", val, t);
}
}
int
main(int argc, char *argv[]) /* Allocated in frame for main() */
{
static int key = 9973; /* Initialized data segment */
static char mbuf[10240000]; /* Uninitialized data segment */
char *p; /* Allocated in frame for main() */
p = malloc(1024); /* Points to memory in heap segment */
doCalc(key);
exit(EXIT_SUCCESS);
}这里是对上述文件的测试,可以得到如下静态代码数据对内存的占用情况
pi@raspberrypi:~/sysprog/learn_tlpi/build $ size out
text data bss dec hex filename
1184 308 10305540 10307032 9d45d8 out
虽然没有在SUSv3中所定义,但是在大多数UNIX系统当中包括Linux,他们提供了三个全局符号:etext(程序段截止地址), edata(初始化数据段截止地址)以及end(未被初始化数据段截止地址)。
下图6.1给出了x86-32架构下多个内存段的架构形式。在最上面标记为argv, environ的空间保存着程序的命令行参数还有该进程使用的环境变量列表。由于内核设置的不同或者因为程序链接的设置的不同也会导致地址的位置会发生变化。表中灰色部分代表了该进程虚拟空间的无效范围,他们是页表上没有被生成的部分,这部分会在后面的章节中讲解-虚拟内存管理。

6.4 虚拟内存管理
就之前对进程的内存排布的讨论来说,实际我们在讨论的就是虚拟内存的排布。这里对虚拟内存管理理解的意义在于之后的一些主题关于fork(),共享内存还有映射文件等都非常重要。这里我们就讲展开讨论虚拟内存的细节。
像大多数现代内核一样,Linux也使用虚拟内存管理Vitual memory management。虚拟内存可以帮助有效使用CPU和RAM通过发掘大多数程序的一个典型特征:locality of reference访问局部性。多数程序可以证明有以下两种局部性:
- Spatial locality 空间局部性,程序总是有一种趋势会容易接下来执行上一条执行指令地址附近的程序,因为一般执行指令都是沿着地址顺序执行并且数据结构一般也是顺序处理
- Temporal locality 时间局部性,程序有一种趋势会在近未来进入他之前访问过的相同的内存地址(比如循环)
上面所述访问局限性的意义就在于它使得只需要维持执行程序的一部分在物理内存当中即可。
一个虚拟内存列表将每一个程序所使用的内存都分成小份,每一份都是固定大小,这样子的一个单元unit被称之为页page。相应的来说也就是RAM被分成一系列等大小的page frame。在任何一个时间,程序仅仅部分页内容寄居在物理内存的页内,这些页的形式被称之为resident set。程序未使用的页的拷贝被维持在一个叫交换的区域swap area-一个磁盘上被预定的位置用于补充计算机RAM所用,并且只有在需要的时候才会被加载进入物理内存。
当进程访问一个不存在物理内存的地址的时候,page fault页错误则会出现,然后kernel会suspend暂停进程的执行,并加载相应的页从磁盘到内存上。
注意:x86-32架构上,一个页的大小是4096字节。一些其他的Linux可能会使用更大的页。决定一个系统的虚拟内存页的大小可以用sysconf(_SC_PAGESIZE)来了解,具体内容见11.2章。
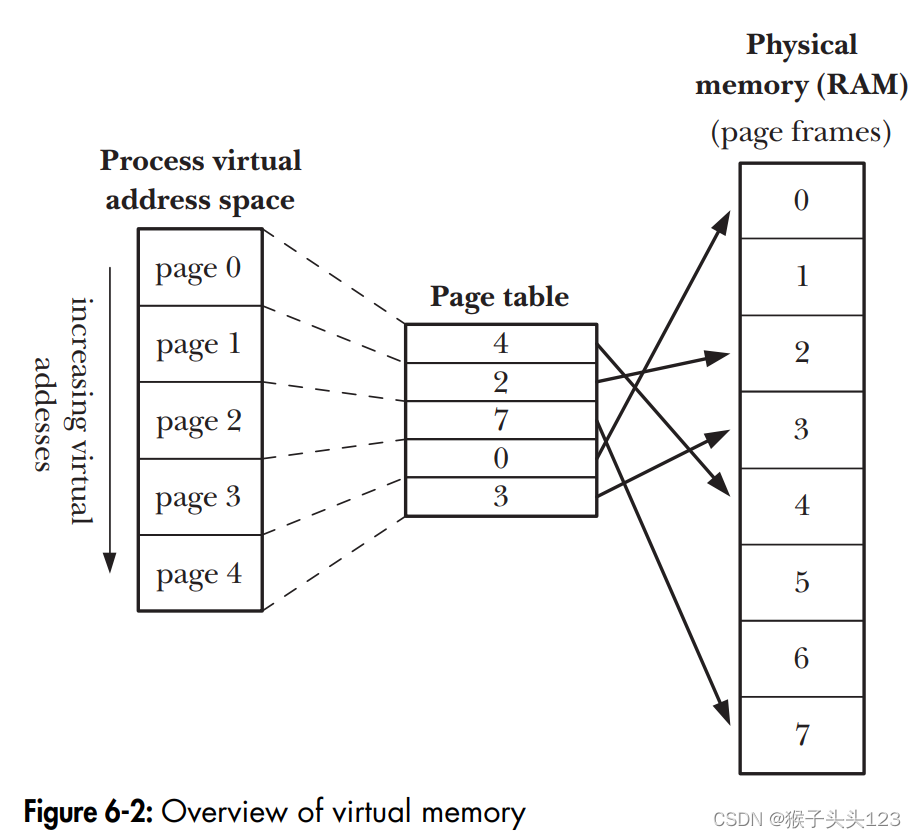
为了能够使得虚拟内存管理良好运行,内核还有一个很重要的任务就是维持一个page table页表来映射进程虚拟地址到实际物理地址上,见图6.2。page table包含了进程的每一个页在其虚拟内存的地址空间。该页表的每一项要么是虚拟页在RAM上的位置信息或者就是表明它还在磁盘上。
并非所有进程的虚拟地址空间都需要维持在页表项里。一般来说其实有大量潜在的地址空间都没有被使用,所以也就没有必要来为他们维持页表项。但是如果一个进程尝试着进入一个没有相应被维持的页表项对应的地址,则他会收到一个SIGSEGV的信号。
一个进程的有效虚拟地址是会在运行过程当中不断变化,因为内核会不断分配,取消分配进程的页:
- 当stack向下增加到之前的限制的时候
- 当内存被分配或取消分配heap通过使用brk(), sbrk()或者其他malloc家族的函数,提升program break。具体见第七章
- 在使用system V中共享内存用shmat()挂载,使用shmdt()卸载,见第48章
- 当使用mmap()进行内存映射之后或者使用munmap()取消映射
虚拟内存管理将进程的虚拟地址空间从RAM的实际物理中分离出来提供了以下几个好处:
- 进程在kernel中是相互隔离的,所以一个进程不能读取或者修改另一个内核中的进程虚拟内存空间。这个是通过虚拟内存页表项指向不同RAM中实际物理页表集合或者swap空间所完成的。
- 多个进程可以分享实际物理内存。内核可以使不同进程的页表项指向相同的RAM页。物理内存分享出现在以下两种常见情况下:
- 多个执行同一个程序的进程可以分享同一个(只读)程序拷贝。这个会在多个程序执行同一个程序文件的时候(或者共享库)隐式发生。
- 进程可以使用shmget()以及mmap()系统调用来显式要求与其他进程共享内存区域。这个是为了实现跨进程通信的目的
- 内存保护因此也可以被实现。内存表项可以根据实际情况被标记成可读,可写,可执行或者多个保护组合。当多个进程共享RAM页的时候,这样子就有可能会使得不同的进程对该程序有不同的保护权限,比如一个进程对该页只读,但也另一个对该进程可读写。
- 程序设计者或者工具比如编译器并不需要考虑程序在RAM中的排布情况
- 因为只有一部分程序需要真的在内存中存在,程序可以根据情况被加载以及快速运行。另外一个虚拟内存的大小是可以远远大于一个实际RAM的大小。
6.5 栈和栈帧
当函数被调用和返回的时候,栈会相应地增长或者收缩。对于运行在x86-32架构上的Linux系统的栈会保持在较高的地址位上并且向低地址增长,见6.1图。一个特殊目的寄存器,stack pointer就是用来保存目前栈所生长到的地址上(被称为top of stack,但实际是栈里目前的地址,向下的低地址位)。每一次当函数被调用的时候,一个额外的栈帧就会被分配给栈,当函数返回的时候栈帧会被收回。
有些时候,用户栈是和我们这里所描述的内核栈是不一样的。内核栈是一个在进程运行前所提前分配的内核内存用于执行被调用的system call而准备的。
每一个(用户)栈帧都包含了以下信息:
- 函数参数和局部变量:在C语言中这些被称为automatic变量,因为他们是由函数在被调用的时候自动产生的。这些函数也会在函数返回之后被自动删除。
- call linkage information:每一个使用特定CPU寄存器的函数,比如用来指向下一个被执行的机器指令的程序计数器pc。当一个A函数调用另一个B函数的时候,对应于A函数的寄存器内容则会被保存在被调用B函数的栈帧当中,当B函数返回的时候,则A函数的寄存器内容将被恢复以继续A函数的执行。
因为一个函数可以调用另一个函数, 所以在堆栈当中一般会存在很多栈帧。以上面6.3章中的程序为例,当执行square()函数的时候,栈中看上去会是这样子:

6.6 命令行参数(argc, argv)
每一个C程序的起始位置都会是一个main()函数。当程序被执行的时候,命令行参数(被shell所解析的分隔词)被通过argc和argv传递给进程里的main()。int argc表明有多少个参数被传递,char *argv[]记录了被传递的参数的数组地址,他们指向所记录的字符串。第一个argv[0]是程序名自己(并非我们想要给入的参数)。argv[argc] = NULL,用来作为参数列表终结符。
虽然argv[0]只是存储了被执行程序的名称,看上去似乎有点鸡肋,但是它其实在一些场景下提供一些比较有用的帮助。我们可以给同一个程序创造多个链接,然后在执行程序的时候检查argv[0]的值来确定采取什么样的执行任务。一个这里的例子就是gzip(1), gunzip(1), zcat(1),他们事实上都链接在同一个可执行程序上面。
下图展示了接下来例子在执行过程当中所涉及到的argc和argv的数据结构:
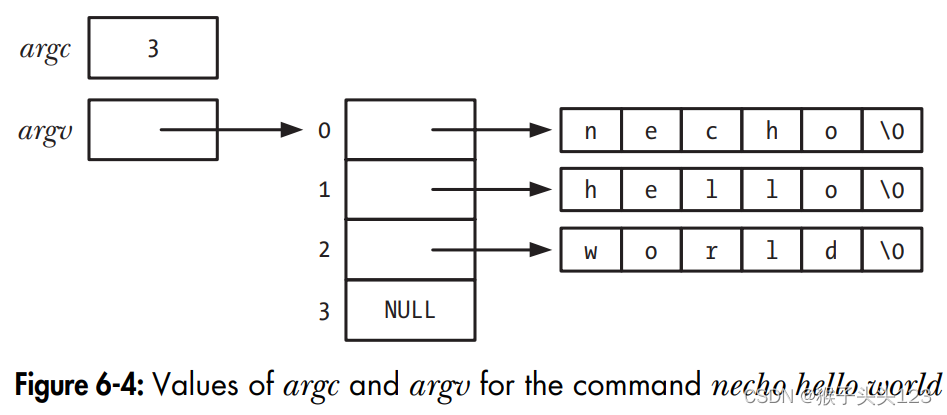
这个程序非常简单,仅仅是根据输入的参数的数量来输出刚才输入的参数字符串。
proc/necho.c (from "The Linux Programming Interface")
#include "tlpi_hdr.h"
int
main(int argc, char *argv[])
{
int j;
for (j = 0; j < argc; j++)
printf("argv[%d] = %s\n", j, argv[j]);
exit(EXIT_SUCCESS);
}当然,我使用的时候和书上的例子稍有不同,实际上参数里存了三个内容,第一个是被执行文件,第二个第三个才是真正的参数内容,当然实际他们最后还带有一个"\0"字符串结束符。
pi@raspberrypi:~/sysprog/learn_tlpi/build $ ./out hello world
argv[0] = ./out
argv[1] = hello
argv[2] = world
除过使用argc来知晓我们一共存储了几个有效argv内容外,也可以直接只通过loop argv来输出所有参数内容,这是
char **p;
for (p = argv; *p != NULL; p++)
puts(*p);argc/argv会先导入到main中,如果想要在别的函数中接着使用argc,则需要继续向下传递,如果想要使用argv,则可以传递argv的地址。
就像图6.1所示那样,argv和environ数组都在一个单独的连续的内存区域内存放着,他们位于stack区域的上面。当然,对于该区域所能存储信息的字节总数使用ARG_MAX所定义和表示(该定义位于<limits.h>),或者也可以通过sysconf(_SC_ARG_MAX)读出。
很多程序也会用getopt()库函数解析命令函参数。
6.7 环境列表
每一个进程都有一个数组保存着字符串-环境列表,或者简单叫环境environment。每一个这样的字符串都是一个以name=value为形式的定义。因此,环境代表着可以保存任意信息的name-value对的集合。name在这个列表里被称之为环境变量,environment variables。
当一个新的进程被创造的时候,它会从母环境那里继承到该环境内容的拷贝。环境是一种很原始但是有用的很多的一种进程间通信的形式,它提供了一种方式从一个母进程传信息到子进程当中。因为子进程从母进程的环境中在创建的时候得到了拷贝,这个信息就只会从母进程单向单次传递给子进程。在子进程被创建之后,各自进程都可以任意改变自己的环境而不会影响以及被其他进程观察到。
一个常用的环境变量的使用就是在shell中。通过在自己的环境中放置好需要的数值,shell可以保证这些值都被传递给在这个shell中用户通过命令行所开启的进程当中。比如说环境变量SHELL被设置成shell程序的路径名,那么很多程序就会解析这个变量作为shell的名字,如果程序需要执行这个shell的时候,那么该SHELL所对应的shell程序就可以执行。
一些库函数允许他们的行为通过设置环境变量而被改变。这就允许用户使用函数在不改变程序代码的情况下或者重链接到相应的库上来实现库函数的行为控制。一个例子就是getopt()函数,它的行为可以通过设置POSIXLY_CORRECT环境变量而得到改变。
在大多数shell中,一个值可以通过export的方式添加到该shell的环境中:
$ SHELL=/bin/bash Create a shell variable
$ export SHELL Put variable into shell process’s environment上述命令可以永久添加该值到shell的环境当中(永久添加是开打bash文件,在文件末尾添加该内容并保存关闭,通过重启shell可以生效),并且这个环境会被所有该shell创建的子进程所继承。
在Bourne shell和它的继任shell(比如bash和Korn shell)当中,下面语句可以用来在执行一个单独程序的时候添加环境变量而不影响到母shell。
$ NAME=value program
如果想要知道现在目前的环境变量有哪些,可以在terminal中输入printenv来获取,有的时候可以方便检查想要的env var是否存在。
比如
$ printenv
LOGNAME=mtk
SHELL=/bin/bash
HOME=/home/mtk
PATH=/usr/local/bin:/usr/bin:/bin:.
TERM=xterm这里需要注意的是,上面的env list并不是以被排序输出的。但是这也不是问题,一般我们只会去寻找一个单一的env 变量而不是一个被排好序的变量集。
当然对于每一个process来说,也有一种直接查看所拥有的env list的办法,就是去/proc/PID/enviro当中读取它的内容。它的每一行 NAME=value后面都是以null byte所结束
从程序里访问环境
在C程序当中,环境列表是可以通过一个全局变量char **environ的形式访问的(他是在C运行时的启动文件中定义并且绑定在它所对应的env列表上)。类似于argv,environ指向一个环境列表,但是这个环境列表的最后一个是以NULL Pointer而终结。

下面是书里给出的程序的具体例子:proc/display_env.c (from "The Linux Programming Interface")
#include "tlpi_hdr.h"
extern char **environ;
int
main(int argc, char *argv[])
{
char **ep;
for (ep = environ; *ep != NULL; ep++)
puts(*ep);
exit(EXIT_SUCCESS);
}它的功能就是类似于printenv一样,将所有environment打印出来。
另一种进入env list的方式就是在main中声明第三个参数,也就是:
int main(int argc, char *argv[], char *envp[])
这个参数可以以同样的方式被当作environ一样使用,不同的是它仅仅是对于main来说是个局域变量。但因为它并不是SUSv3所定义和使用的,即使在很多UNIX系统中它都被广泛使用,但在书中也建议尽量少使用该方法。
如果想要得到某一个单一的env variable,可以通过以下方法实现:
#include <stdlib.h>
char *getenv(const char *name);它会根据所给定的变量名,自动在env环境中解析出来环境变量值。如果没有找到所对应的变量,则返回NULL。
在使用getenv()的时候应该额外考虑以下点:
- SUSv3规定应用程序不应该也不能够修改通过getenv()所读到的字符串,因为这个字符串是环境的一部分,它应当与该进程所使用的字符串保持一致。如果我们想要去改变环境变量的数值的话,那么我们需要使用setenv()或者putenv()函数来改变环境变量。
- SUSv3允许getenv()返回结果并保存在一个静态分配的buffer当中,而且这个buffer在随着之后的getenv(),setenv(),putenv()或者unsetenv()调用而被改写。虽然glibc对getenv()的实现并没有使用一个静态buffer。因此对于一个想要实现可执行性的程序,则应该先将getenv读取到的内容保存在另一个变量当中,再去执行其他事情,这样子可以保证之前读到的东西不会被抹掉。
修改环境
有的时候,在一个进程当中修改环境是有用的。其中一个理由就是想要修改一些环境变量,并且这些变量仅对该进程所产生的子进程可见。另一个可能就是在一个新的程序要被加载到这个进程的时候,我们想要设置一个变量仅对这个程序可见。在这种情况下,环境就不仅仅是一种进程间通信,而也可以是一种程序间通信,这一点具体会在第27章中讲解,那里会讲解如果使用exec()在一个进程中如何允许一个新程序替换另一个程序。
putenv()
putenv()可以用来帮助添加或者修改进程中的环境变量,用法:
#include <stdlib.h>
int putenv(char *string);string是一个指向字符串的指针,它的形式是 name=value。另外,在使用该方法的时候,实际上是使用一个在environ中的element指向所给入字符串的地址,那么当然我们在修改该字符串的时候,实际上他就已经会直接作用在env list上了。从上面的描述出发,我们则不可以将string放在一个临时变量里面,而应该是静态变量,否则当函数结束的时候,所指向的stack的地址则会被直接修改,那么env list则将失效。
glibc对putenv()的执行还多了一个非标准扩展。如果string中不包含“=”符号,那么包含这里指定环境变量的字符串将被从env list中所移除。
setenv()
setenv()是一个对putenv()的替换方法
#include <stdlib.h>
int setenv(const char *name, const char *value, int overwrite);setenv()不需要"=",因为它需要显式输入环境变量名称和值,然后它会将这两个string结合并拷贝到buffer当中。overwrite为1的时候表示如果环境变量已经存在,我们可以对他进行修改。如果overwrite为0的话,那么如果*name已存在,则不会发生任何事情。
setenv()会发生拷贝,这点不同于putenv(),即使后面我们修改当时输入*name和*value的字符串,也不会导致env list发生改变,这也就意味着输入*name和*value所使用的变量可以是一个局部临时变量。
unsetenv()
这个方法会帮忙移除*name所指定的环境变量。
#include <stdlib.h>
int unsetenv(const char *name);setenv()和unsetenv()均来源于BSD,他们相比于putenv()在以前应用并不是非常广泛,但是现在他们已经是SUSv3的一部分。
clearenv()
有的时候移除整个环境也是非常有用的,这样子我们就可以重建所需要的环境变量。比如我们可能想要执行一些和userID相关的有安全相关性的程序,这时候我们就会选择将所有环境设置成
environ = NULL;当然我们也可以使用clearenv()库函数来实现这一点
#define _BSD_SOURCE /* Or: #define _SVID_SOURCE */
#include <stdlib.h>
int clearenv(void)有的时候,在一些环境当中,setenv()和clearenv()可能会导致内存泄漏。我们注意到上面setenv()会分配一个内存buffer给环境作为一部分。当我们调用clearenv()的时候,它并不会释放这个buffer(因为clearenv本身并不知道它的存在)。当一个程序在不断的调用这两个函数的时候,则会有很高概率造成内存泄漏。当然,一般来讲,在一般情况下clearenv()只会在程序启动的时候调用一下,或者移除所有从母进程所继承来的环境的时候帮助移除所有env时使用,所以这样子一般并不会造成问题。
例程
下面列出了所有在该段所描述的函数的使用。proc/modify_env.c (from "The Linux Programming Interface")
#define _GNU_SOURCE /* Get various declarations from <stdlib.h> */
#include <stdlib.h>
#include "tlpi_hdr.h"
extern char **environ;
int
main(int argc, char *argv[])
{
int j;
char **ep;
clearenv(); /* Erase entire environment */
for (j = 1; j < argc; j++)
if (putenv(argv[j]) != 0)
errExit("putenv: %s", argv[j]);
if (setenv("GREET", "Hello world", 0) == -1)
errExit("setenv");
unsetenv("BYE");
for (ep = environ; *ep != NULL; ep++)
puts(*ep);
exit(EXIT_SUCCESS);
}该例程的结构非常明显,它会首先清除所有继承来的环境变量,然后讲我们在调用程序时给入的正确的环境变量通过putenv输入到该进程的环境变量中,再之后它会通过显式输入创造一个GREET=Hello world的环境变量。如果在我们调用该程序的时候给入过一个BYE为变量名的环境变量的时候,会自动移除它。最后我们可以来观察最后在我们的环境变量中到底有什么。
测试1,string的输入可以有多种方式,并且"GREET=Guten Tag"被早于"GREET=Hello world"被输入,因为setenv的overwrite是0,所以不会修改GREET的内容。因为BYE始终会被删除,所以最后的输出并看不到BYE相关的环境变量。
pi@raspberrypi:~/sysprog/learn_tlpi/build $ ./out "GREET=Guten Tag" SHELL=/bin/bash BYE=Ciao
GREET=Guten Tag
SHELL=/bin/bash
测试2,
pi@raspberrypi:~/sysprog/learn_tlpi/build $ ./out SHELL=/bin/sh BYE=byebye
SHELL=/bin/sh
GREET=Hello world
这里,GREET会用程序中默认的生成,同样看不到BYE相关内容。
6.8 实现一个非局域GOTO: setjmp()和longjmp()
setjmp()和longjmp()是可以用来实现非局域跳转的库函数。顾名思义,非局域即可以从正执行函数的位置跳出该函数范围。
就像其他编程语言一样,C语言也包含了goto语句,但是它会使得程序难以阅读和维持,所以一般写C语言的时候建议避免使用goto。但是goto又带来一定的好处,偶尔的使用可以使得程序得执行更简单更快。
。。。
这部分之后再说。。














 1616
1616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









