







 本文介绍了四种无监督聚类算法:K-means、层次聚类、DBSCAN和均值漂移。K-means通过迭代寻找簇中心,依赖于初始质心的选择和K值的确定。层次聚类以簇间距离为基础形成树状结构。DBSCAN基于密度,能处理不规则形状的簇。均值漂移算法寻找数据的密集区域。K-means的优点包括快速收敛和简单实现,但对K值敏感且易受异常点影响。
本文介绍了四种无监督聚类算法:K-means、层次聚类、DBSCAN和均值漂移。K-means通过迭代寻找簇中心,依赖于初始质心的选择和K值的确定。层次聚类以簇间距离为基础形成树状结构。DBSCAN基于密度,能处理不规则形状的簇。均值漂移算法寻找数据的密集区域。K-means的优点包括快速收敛和简单实现,但对K值敏感且易受异常点影响。
文章目录
一、K-means简介
1.1 K-means简介
K-means是无监督的聚类算法。其主要思想是选择K个点作为初始聚类中心, 将每个对象分配到最近的中心形成K个簇,重新计算每个簇的中心,重复以上迭代步骤,直到簇不再变化或达到指定迭代次数为止。,让簇内的点尽量紧密的连接在一起,而让簇间的距离尽量的大。
K-means每次计算质心,第一次是随机产生质心,第二次开始,是根据第一次分类后,每类的平均值作为质心,所以叫K-means聚类。
K-means如果簇中存在异常点,将导致均值偏差比较严重。例如:
一个簇中有2、4、6、8、100五个数据,那么新的质点为24,显然这个质点离绝大多数点都比较远;在当前情况下,使用中位数6可能比使用均值的想法更好,使用中位数的聚类方式叫做K- Mediods聚类(K中值聚类)。
1.1.1 K值的确定
在实际的应用中,主要两种方法进行K值的确定:
- 经验法:在实际的工作中,可以结合业务的场景和需求,来决定分几类以确定K值。
- 肘部法则(畸变程度):在使用聚类算法时,如果没有指定聚类的数量,即K值,则可以通过肘部法则来进行对K值得确定。肘部法则是通过成本函数来刻画的,其是通过将不同K值的成本函数刻画出来,随着K值的增大,平均畸变程度会不断减小且每个类包含的样本数会减少,于是样本离其重心会更近。但是,随着值继续增大,平均畸变程度的改善效果会不断减低。因此找出在K值增大的过程中,畸变程度下降幅度最大的位置所对应的K较为合理。
k-means是以最小化样本与质点平方误差作为目标函数,将每个簇的质点与簇内样本点的平方距离误差和称为畸变程度(distortions),那么,对于一个簇,它的畸变程度越低,代表簇内成员越紧密,畸变程度越高,代表簇内结构越松散。 畸变程度会随着类别的增加而降低,但对于有一定区分度的数据,在达到某个临界点时畸变程度会得到极大改善,之后缓慢下降,这个临界点就可以考虑为聚类性能较好的点。
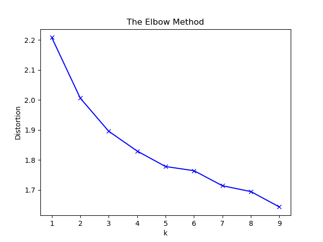
1.1.2 K-means 成本函数(利用SSE选择k)
指定一个i值,即可能的最大类簇数。然后将类簇数从1开始递增,一直到i,计算出i个簇内误方差(SSE)。根据数据的潜在模式,当设定的类簇数不断逼近真实类簇数时,SSE呈现快速下降态势,而当设定类簇数超过真实类簇数时,SSE也会继续下降,当下降会迅速趋于缓慢。通过画出K-SSE曲线,找出下降途中的拐点,即可较好的确定K值。
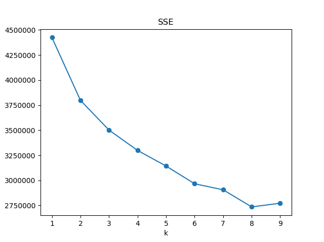
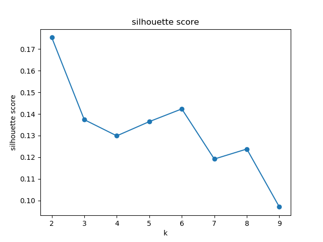
从图中可以看出,根据平均轮廓系数最大的开始选择聚类数量,当取2类时,SSE过大,取3类或5类或6类时,SSE相对较小,在手肘法(elbow method)中没有明显拐点,为了后续分析,这里取三类。
1.1.3 Silhouette Coefficient(评估聚类好坏)
- 廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。最早由 Peter J. Rousseeuw 在 1986 提出。它结合内聚度和分离度两种因素。
- 可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。
- 轮廓系数越接近1,说明聚类的合理。接近-1,说明聚类发生了错误。轮过系数在0附近,说明大多数样本在两个簇的边界上。
- 对于一个聚类任务,我们希望得到的类别簇中,簇内尽量紧密,簇间尽量远离,轮廓系数便是类的密集与分散程度的评价指标,公式表达如下
1.2 层次聚类
尽管k-means的原理很简单,然而层次聚类法的原理更简单。它的基本过程如下:
- 每一个样本点视为一个簇;
- 计算各个簇之间的距离,最近的两个簇聚合成一个新簇;
- 重复以上过程直至最后只有一簇。
层次聚类不指定具体的簇数,而只关注簇之间的远近,最终会形成一个树形图。
1.3 DBSCAN - 基于密度的聚类算法
1.3.1 简介
DBSCAN(Density-Based Spatial Clustering of Application with Noise) - 基于密度的聚类算法.
基于密度的聚类方法与其他方法的一个根本区别是:它不是基于各种各样的距离度量的,而是基于密度的。因此它能克服基于距离的算法只能发现“类圆形”的聚类的缺点。
DBSCAN的指导思想是:用一个点的∈邻域内的邻居点数衡量该点所在空间的密度,只要一个区域中的点的密度大过某个阈值,就把它加到与之相近的聚类中去
1.3.2 具体步骤
与均值漂移聚类类似,DBSCAN也是基于密度的聚类算法。
具体步骤:
- 首先确定半径r和minPoints. 从一个没有被访问过的任意数据点开始,以这个点为中心,r为半径的圆内包含的点的数量是否大于或等于minPoints,如果大于或等于minPoints则改点被标记为central point,反之则会被标记为noise point。
- 重复1的步骤,如果一个noise point存在于某个central point为半径的圆内,则这个点被标记为边缘点,反之仍为noise point。重复步骤1,知道所有的点都被访问过。
优点:不需要知道簇的数量
缺点:需要确定距离r和minPoints
1.4 均值漂移聚类
1.4.1 简介
均值漂移聚类是基于滑动窗口的算法,来找到数据点的密集区域。这是一个基于质心的算法,通过将中心点的候选点更新为滑动窗口内点的均值来完成,来定位每个组/类的中心点。然后对这些候选窗口进行相似窗口进行去除,最终形成中心点集及相应的分组。
1.4.2 步骤
具体步骤:
- 确定滑动窗口半径r,以随机选取的中心点C半径为r的圆形滑动窗口开始滑动。均值漂移类似一种爬山算法,在每一次迭代中向密度更高的区域移动,直到收敛。
- 每一次滑动到新的区域,计算滑动窗口内的均值来作为中心点,滑动窗口内的点的数量为窗口内的密度。在每一次移动中,窗口会想密度更高的区域移动。
- 移动窗口,计算窗口内的中心点以及窗口内的密度,知道没有方向在窗口内可以容纳更多的点,即一直移动到圆内密度不再增加为止。
- 步骤一到三会产生很多个滑动窗口,当多个滑动窗口重叠时,保留包含最多点的窗口,然后根据数据点所在的滑动窗口进行聚类。
二、代码
2.1 原理推导
from scipy.io import loadmat
import pandas as pd
import seaborn as sb
import matplotlib.pyplot as plt
import numpy as np
''
'''
K-means是一个迭代的,无监督的聚类算法,将类似的实例组合成簇。 该算法通过猜测每个簇的
初始聚类中心开始,然后重复将实例分配给最近的簇,并重新计算该簇的聚类中心。
'''
def find_closest_centroids(X, centroids): # 初始质心centroids
m = X.shape[0] # m是样本数
k = centroids.shape[0]
idx = np.zeros(m)
for i in range(m):
min_dist = 1000000 # 初始距离 样本与质心
for j in range 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









