一:使用Tungsten功能
1, 如果想让您的程序使用Tungsten的功能,可以配置:
Spark.Shuffle.Manager = tungsten-sort
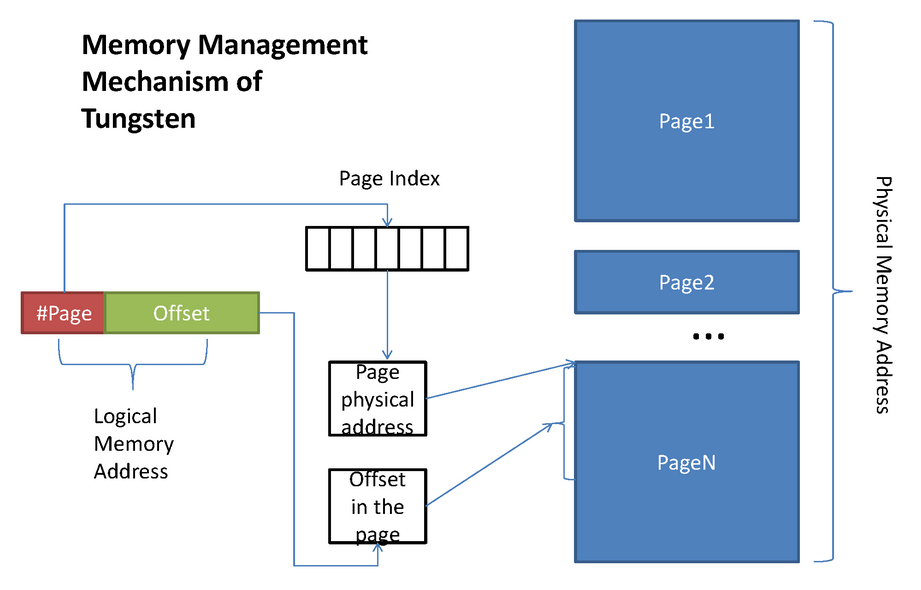
Spark在钨丝计划下要管理两种类型的内存存储方式:堆内和堆外。为了管理他们,所以搞了一个Page。
堆外:指针直接指向数据本身。
堆内:指针首先指向Object,然后通过偏移量OffSet再具体定位到数据。
2. DataFrame中自动开启了Tungsten功能。
二:Tungsten-sort base Shuffle writer内幕
下图是写入的过程:
Spark Core
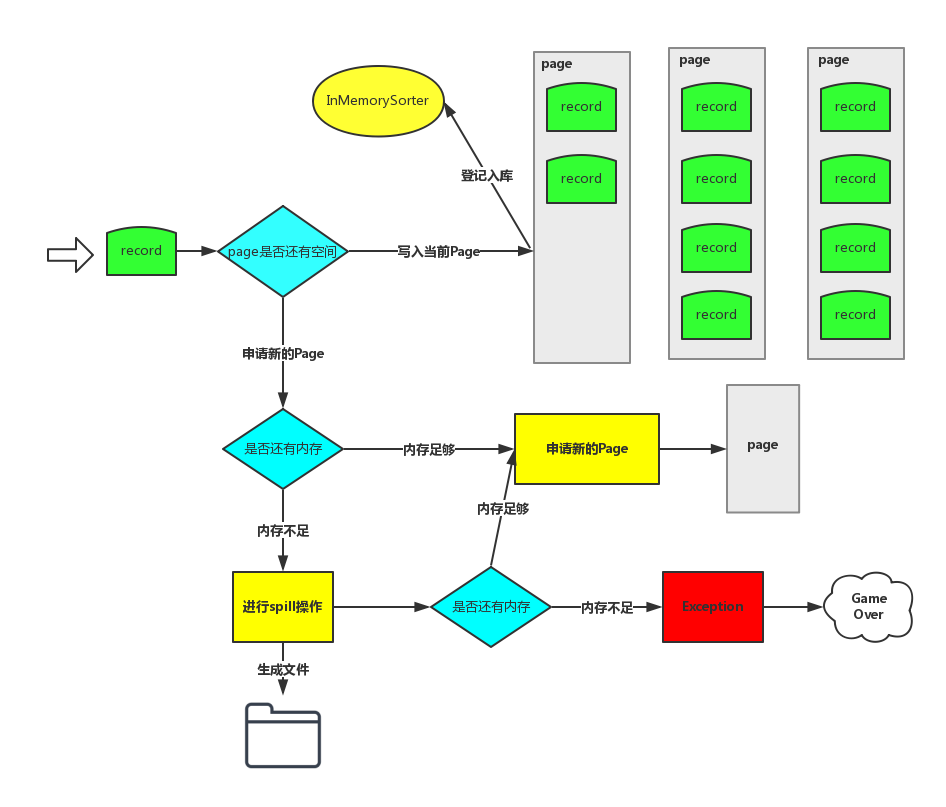
输入数据的时候是循环每个Task中处理的数据Partition的结果,循环的时候会查看是否有内存,一个Page写满之后,才会写下一个Page。
如何看内存是否足够?
a) 系统默认情况下给ShuffleMapTask最大准备了多少内存空间?默认情况下是通过ExecutorHeapMemory*0.8*0.2
Spark.shuffle.memoryFraction=0.2
spark.shuffle.safetyFraction=0.8
b) 另外一方面是和Task处理的Partition大小紧密相关。
1.mergeSpills的功能是将很多小文件合并成一个大文件。然后加上index文件索引。
/**
* Merge zero or more spill files together, choosing the fastest merging strategy based on the
* number of spills and the IO compression codec.
*
* @return the partition lengths in the merged file.
*/
private long[] mergeSpills(SpillInfo[] spills, File outputFile) throws IOException {
final boolean compressionEnabled = sparkConf.getBoolean("spark.shuffle.compress", true);
final CompressionCodec = CompressionCodec$.MODULE$.createCodec(sparkConf);
final boolean fastMergeEnabled =
sparkConf.getBoolean("spark.shuffle.unsafe.fastMergeEnabled", true);
final boolean fastMergeIsSupported = !compressionEnabled ||
CompressionCodec$.MODULE$.supportsConcatenationOfSerializedStreams(compressionCodec);
2.和Sort Based Shuffle 过程基本一样。
3.写数据在内存足够大的情况下是写到Page里面,在Page中有一条条的Record,如果内存不够的话会Spill到磁盘中。此过程跟前面讲解Sort base Shuffle writer过程是一样的。
4.基于UnsafeShuffleWriter会有一个类负责将数据写入到Page中。
5.insertRecordIntoSorter: 此方法把records的数据一条一条的写入到输出流。
而输出流是: ByteArrayOutputStream
@VisibleForTesting
void insertRecordIntoSorter(Product2<K, V> record) throws IOException {
assert(sorter != null);
final K key = record._1();
final int partitionId = partitioner.getPartition(key);
serBuffer.reset();
serOutputStream.writeKey(key, OBJECT_CLASS_TAG);
serOutputStream.writeValue(record._2(), OBJECT_CLASS_TAG);
serOutputStream.flush();
final int serializedRecordSize = serBuffer.size();
assert (serializedRecordSize > 0);
sorter.insertRecord(
serBuffer.getBuf(), Platform.BYTE_ARRAY_OFFSET, serializedRecordSize, partitionId);
6.serBuffer实例化,默认大小是1M,也就是输出流的大小默认是1M。
serBuffer = new MyByteArrayOutputStream(1024 * 1024);
三:Tungsten-sort base Shuffle Read内幕
1. 基本上是复用了Hash Shuffle Read.
2. 在Tungsten下获取数据的类叫做BlockStoreShuffleReader,其底层其实是Page。

























 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









