







本篇博客主要是对Tungsten-sort Based Shuffle简单分析,因为钨丝计划还没有成熟,所以这里不会太详细的介绍。
一:使用Tungsten功能
1, 如果想让您的程序使用Tungsten的功能,可以配置:
Spark.Shuffle.Manager = tungsten-sort
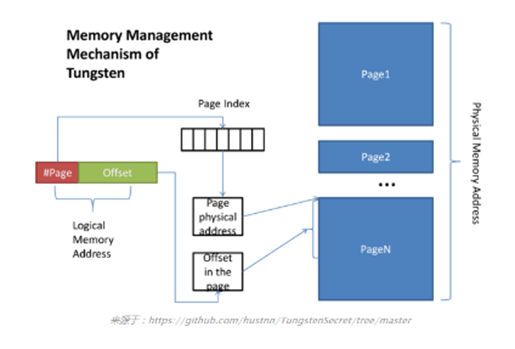
Spark在钨丝计划下要管理两种类型的内存存储方式:堆内和堆外。为了管理他们,所以搞了一个Page。
堆外:指针直接指向数据本身。
堆内:指针首先指向Object,然后通过偏移量OffSet再具体定位到数据。
2. DataFrame中自动开启了Tungsten功能。
二:Tungsten-sort base Shuffle writer内幕
下图是写入的过程:
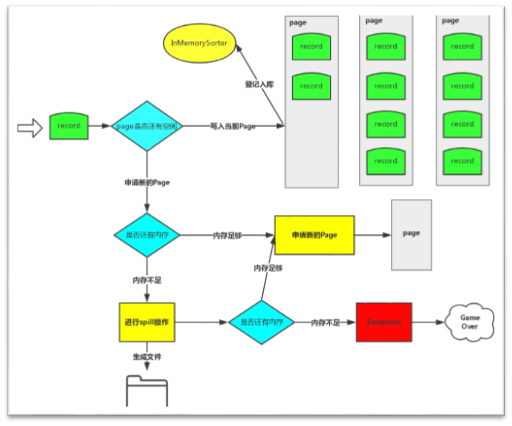
输入数据的时候是循环每个Task中处理的数据Partition的结果,循环的时候会查看是否有内存,一个Page写满之后,才会写下一个Page。
如何看内存是否足够?
a) 系统默认情况下给ShuffleMapTask最大准备了多少内存空间?默认情况下是通过ExecutorHeapMemory*0.8*0.2
Spark.shuffle.memoryFraction=0.2
spark.shuffle.safetyFraction=0.8
b) 另外一方面是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1039
1039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









