







二叉搜索树是在二叉树的基础上的根据子树的值的大小进行了排序调整后的结果,而且它是红黑树的基础结构,在了解红黑树之前学习二叉搜索树对后面掌握红黑树是有很大帮助的。
定义
二叉树的任意结点,它的左子树关键字不超过父结点,右子树关键字不小于父结点,则这样的二叉树成为二叉搜索树。
查找
相对于普通二叉树的查找,二叉搜索树可以借助待查数与当前结点的相对大小确定下一步搜索的方向。
查找代码的递归版本:
Node search(Node node,int value){
if(node==null){
return;
}
if(node.value==value){
return node;
}
if(value<node.value){
return search(node.lChild,value);
}
if(value>node.value){
return search(node.rChild,value);
}
}非递归版本代码:
Node search(Node node,int value){
if(node==null){
return;
}
while(node.value!=value&&node!=null){
if(value<node.value){
node=node.lChild;
}
if(value>node.value){
node=node.rChild;
}
}
return node;
}插入
二叉搜索树的插入操作和查找很类似,直接看代码
递归版插入伪代码:
void insert(Node node,int value){
if(node==null){
if(node.p!=null){//node.p表示node父结点
if(node.p.value<value){
node.rChild.value=value;
}else{
node.lChild.value=value;
}
}
return;
}
if(value>node.value){
insert(node.rChild,value);
}
if(value<node.value){
insert(node.lChild,value);
}
}非递归的代码
void insert(Node node,int value){
if(node==null){
return;
}
while(node!=null){
temp=node;//暂存下node,作为插入结点的父结点
if(value<node.value){
node=node.lChild;
}else{
node=node.rChild;
}
}
if(temp.value>value){
temp.lChild.value=value;
}else{
temp.rChild.value=value;
}
}删除
二叉查找树的删除分三种情况考虑(假设要删除的结点是z):
- z是叶子结点,直接删除,并将z在父结点的子树位置空
- z只有一个孩子结点,直接将孩子结点放置到z的位置,修改z在父结点的子树位置为z的孩子结点
- z有两个孩子结点,找到z的后继结点y,让y占据原来z的位置,z的左右子树分别称为y的左右子树。该情况还得再分为y是否为z的右孩子。
如下图所示:
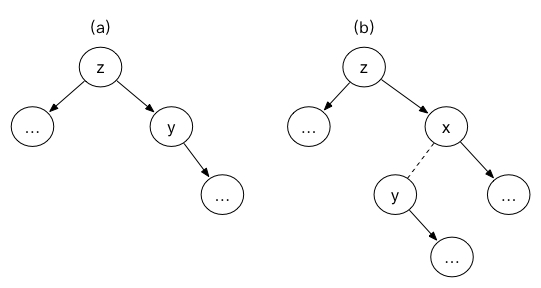
后继结点是指二叉查找树中从小到大排序后,排在删除结点的后一个的结点,也就是中序遍历时,访问删除结点后下一个要访问的结点,所以访问z之后,再访问z的右子树,如果右子树的左子树为空,则访问右子树的根结点,否则访问右子树的最左子结点。所以说第三种删除情况又分为两种情况:图(a)中,y代替z,z原来的左子树成为y的左子树,y原来的右子树仍作为y的右子树,z结点删除;图(b)中,y结点代替z结点,z原来的左子树作为y的左子树,y原来的 右子树作为y原来的父结点的左子树,z结点删除。
可以看到,四种情况下,都包含有将某个节点的整个子树替换原来的结点操作(第一种情况可理解成空子树替换原来的结点)。先给出某结点替换另一结点的统一操作注意,替换操作,只是调整了old点的父结点,并没有调整new点的左右子树指向old点左右指数,因为四种情况,子树的调整上并不完全统一:
void replace(Node root,Node old,Node new){
if(old.p==null){//考虑原来的结点是头结点
root=new;
}
if(old.p.lChild!=null){
old.p.lChild=new;
}else{
old.p.rChild=new;
}
if(new!=null){//父结点指向子结点之后,子结点也需要指向父结点
new.p=old.p;
}
}从上述代码看出,old为root结点,new为null结点等特殊情况下,均可以实现new替换old的操作。
有了replace方法,我们写delete方法就方便了,代码如下:
void delete(Node root,Node z){
if(root==null||z==null){
return;
}
if(z.lChild==null&&z.rChild==null){//删除叶子结点
replace(root,z,null);
}else if(z.lChild==null&&z.rChild!=null){//只有右子树
replace(root,z,z.rChild);
}else if(z.rChild=null&&z.lChild!=null){//只有左子树
replace(root,z.z.lChild);
}else{//左右子树均不为空
//找中继结点
Node y=z.rChild;
while(y!=null){
y=y.lChild;
}
if(y.p==z){//中继结点就是z的右孩子
replace(root,z,y);
y.lChild=z.lChild;//调整y新的左子树
y.lChild.p=y;
}else{//中继结点是z的右孩子的最左孩子
replace(root,y,y.rChild);//先用y的右孩子替换y
y.rChild=z.rChild;//调整y和z.rChild
y.rChild.p=y;
replace(root,z,y);
y.lChild=z.lChild;//调整y新的左子树
y.lChild.p=y;
}
//关于中继结点对应的if/else,可以优化成
// if(y.p!=z){
// replace(root,y,y.rChild);//先用y的右孩子替换y
// y.rChild=z.rChild;//调整y和z.rChild
// y.rChild.p=y;
// }
// replace(root,z,y);
// y.lChild=z.lChild;//调整y新的左子树
// y.lChild.p=y;
//博主个人觉得不优化的时候适合初学者理解,理解了之后再优化成这样,也是好理解的。
}
}优化的过程相当于下图所示:
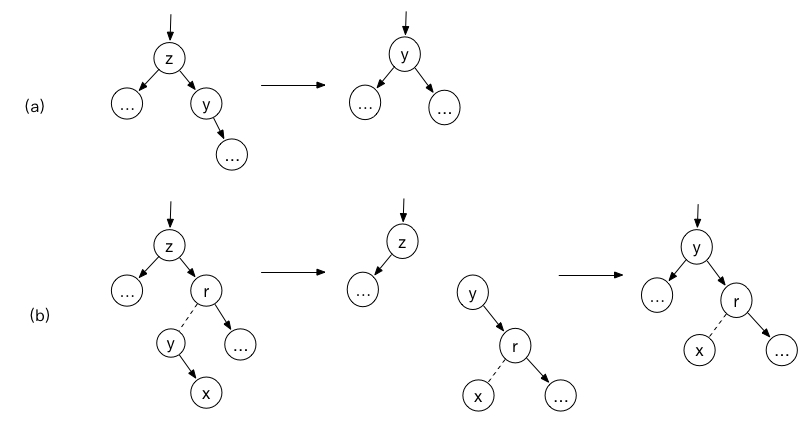
图(a)表示第三种情况的第一种可能,图(b)表示第三种情况的第二种可能。此时可以将图(b)的中继结点先调整到位,构成图(a)的样子,然后再和图(a)一样replace(root,z,y),所以如果第二种情况,就多执行如下几步即可。
if(y.p!=z){
replace(root,y,y.rChild);//先用y的右孩子替换y
y.rChild=z.rChild;//调整y和z.rChild
y.rChild.p=y;
}
总结
关于二叉搜索树的常见操作就说完了, 下篇文章我们分析二叉搜索树的升级版红黑树。
本文主要参考《算法导论——第三版》第12章。
很惭愧,做了一点微小的贡献!















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









