









目录
- 题目
- 描述
- 数据集
- 输入格式
- 输出格式
- 思路
- 代码
- 实现效果
- 总结
主要内容是校设课程的习题和课外学习的一些习题。
欢迎关注 『Python习题』 系列,持续更新中
欢迎关注 『Python习题』 系列,持续更新中
题目
描述
假设我们有一份文件(编码格式UTF-8),文件中包含了很多个人隐私信息。 现在需要一份去除其中敏感信息的版本,将文件中所有手机号的4~7位和身份证号的7~14位用 * 替换。 示例: 如果读入文件内容为: 张三 居住地:武汉 身份证号:420111199909091234 手机号:13013013130
输出结果是:
张三 居住地:武汉 身份证号:420111********1234 手机号:130****3130
数据集
data.txt
张三
居住地:武汉
身份证号:420111199909091234
手机号:13212341234
李四
居住地:北京
身份证号:11010120000101234X
手机号:13988777777
王五
居住地:深圳
身份证号:610101198808082222
手机号:13766654321
输入格式
读取附件的文件
输出格式
张三 居住地:武汉 身份证号:420111********1234 手机号:130****3130
示例 1
输入:
输出:
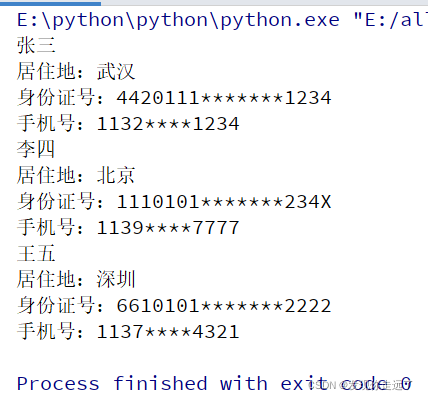
张三
居住地:武汉
身份证号:4420111*******1234
手机号:1132****1234
李四
居住地:北京
身份证号:1110101*******234X
手机号:1139****7777
王五
居住地:深圳
身份证号:6610101*******2222
手机号:1137****4321
思路
- 先读取数据,然后按行分割成列表
- 接下来根据每一行的长度判断是手机号码还是身份证(因为这个长度一定是不变的,固定的)
- 最后使用切片的方式完成字符串的替换。
代码
### 朴实无华的实现空值替换(只有这种可以过测试点,下面两种答案对的,但是过不了判题系统)
with open('data.txt', 'r', encoding='utf-8') as f:
lines = f.read().split("\n")
for i in range(len(lines)):
x = lines[i]
if len(lines[i]) == 15:#手机号码11位,这一行总共长15
lines[i] = x[0:4]+x[4:7] + "*" * 4 + x[-4:]
elif len(lines[i]) == 23:#身份证18位,这一行总共长23
lines[i] = x[0:5]+x[5:11] + "*" * 8 + x[-4:]
for i in lines:
print(i)
实现效果
总结
大家喜欢的话,给个👍,点个关注!给大家分享更多有趣好玩的Python习题!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2022 mzh
Crated:2022-3-1
欢迎关注 『Python习题』 系列,持续更新中
欢迎关注 『Python习题』 系列,持续更新中
【更多内容敬请期待】

















 2626
2626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











