






终于到类了,感觉最近翻译速度好慢啊。
9.1 A Word About Names and Objects
同一个对象可以绑定不同的名称,其他语言把这种特性叫做别名(真是顾名思义啊...)。这种特性可能一开始不是很好理解,但是在使用不可改变的对象时这不会有什么影响。但是这种特性在使用可改变的对象时有惊人的效果,因为别名有限类似于指针,这样在传递数据的时候开销很低;并且将对象作为参数传入函数时,函数可以修改对象。
9.2 Python Scopes and Namespaces
在介绍类之前,我们先介绍一下作用域的规则。类的定义在命名空间上有些小技巧,你先要知道他的规则才能很好的进行理解,顺便说一下这部分知识对上进的青年极为重要。那么我们开始啦~
命名空间是一个从名字到对象的映射关系,大部分命名空间是用字典来实现的只是我们看不到而已,而且他们是可变的。举些例子:比如内建的函数和变量名、一个模块的全局变量、一个函数声明的局部变量等等。一个重点是:在不同的命名空间中的变量名没有任何关系。比如两个模块都有一个叫做maxsize的方法,用户使用的时候必须使用模块名在前面作为修饰来防止混淆的发生。
顺便说一下,我们把点后面的东西叫做属性(attribute)比如z.real。其中real是对象z的一个属性,严格来说模块内的方法也是模块的一个属性:比如module.funcname.modname这个表达式中funcname就是module的一个属性。这确保了模块的属性和他的全局变量有明确的关系,他们使用共同的命名空间。
属性的读写权限的可以设定的,只有在设定可写的情况下变量才能够被赋给属性。比如当属性可写的时候:表达式modname.the_anwser = 42是可行的。使用del协议可以删除可写的属性,比如del modname.the_answer就会将the_answer这个属性从modname中删除。
命名空间在不同的时间点生成,也有着不同的时效。包含内建函数的命名空间在解释器运行时就被创建,并且绝对不会被删除。模块的全局变量实在模块定义被引入时创建的,同样这个命名空间也会坚持的解释器被关闭。所有被解释器最优先执行的协议,无论是运行脚本还是交互模式,都会被认为是__main__模块的一部分,所以他们也有自己的命名空间。(其实所有的内建变量名也是在一个叫做builtins的模块中的)
函数的命名空间是局部的(只能它自己调用),他在函数被调用时生成,在函数返回或者引起了不能解决的异常后结束。当然递归的调用函数他们都会各自拥有自己的命名空间。
作用区域(scope)就是用来规定程序在那些区域可以进入那些命名空间,虽然作用区域是静态定义的,但是使用起来却是动态的,在执行任务的任何时刻,都至少有三个嵌套的作用区域的命名空间是可以直接访问的:
- 最内层的区域——最先被搜索,包含局部变量
- 被植入函数的区域——他们是从最近的区域开始搜索,包含非局域也非全局变量
- 剩余部分区域——包含当前模块的全局变量
- 最外层区域——最后被搜索,包括内建变量
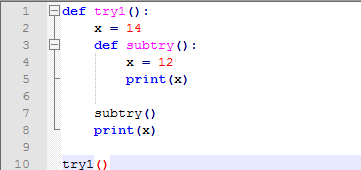
其实这个规则和c语言是差不多的,就是在作用域不断的向外层寻找而已。global协议声明这个变量是全局变量,在当且位置重新绑定不在当前作用域创建新变量;nonlocal表示该变量是在一个植入函数的空间中的,在当前位置重新绑定。
9.2.1 Scopes and Namespaces Example
我们先看一个比较详细的例子:
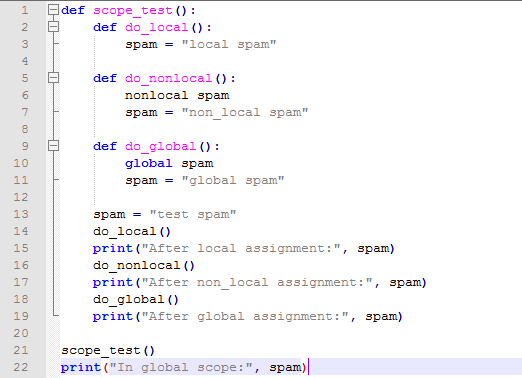

注意local中的赋值并没有修改scope_test()中的变量,而nonlocal则会修改这个变量。global变量修改的是全局变量,可以直接理解为就是模块的命名空间。
9.3 A First Look at Classes
这部分会介绍一些新语法,和三个新类型。
9.3.1 Class Definition Syntax
我们来看一个最简单的声明方式:
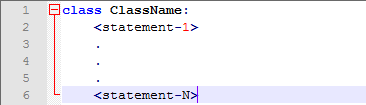
类的定义看上去和函数的定义比较相近,都需要先定义在使用,可以在函数内定义类,也可以在类中定义函数。我们在练习的时候一般在类中定义函数,但是记得其他的协议也是可以的。定义在类中的函数可能会有些奇怪的参数,这是由调用方法的协议决定的,这部分内容我们稍后再讲。
当新定义一个类的时候会创建一个新的命名空间作为局部变量的范围。实际上函数的名字也是存在这个命名空间中的。当一个类的定义正常的结束了后,一个新的对象类型就出现了。然后局部变量的空间就会恢复成定义类之前的那个。
9.3.2 Class Objects
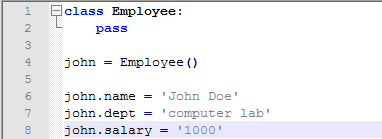
类对象有两种操作,引用类的属性和创建一个类实例。引用属性的语法和一般引用的语法一样都是点语法,比如Obj.name。所有可以有效引用的属性都在类被创建时保存在命名空间中了,所以如果我们这样定义一个类:
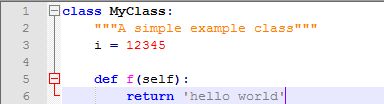
在上面这个例子中,MyClass.i和MyClass.f就是有效的引用,分别返回一个整型数字和一个函数对象。当然能调用就能修改,还有一个可用的属性__doc__,这里面保存了你对类的说明,至于如何写说明我们前面是介绍过的。创建类实例的方法有些类似于调用函数,假装这个函数没有参数,返回的就是类实例:x = MyClass(),这样我们就创建了一个实例并且名字叫做x。一般来说我们创建类都是为了实现特定的功能,所以在生成一个类实例的时候我们希望它按照我们的愿望包含一些东西,这个时候可以使用__init__方法:

当一个类对象内含有__init__方法的时候,每次新建类实例的时候都会运行这个方法。当然这个方法可以使用的很灵活,比如我们可以向其中传入参数:
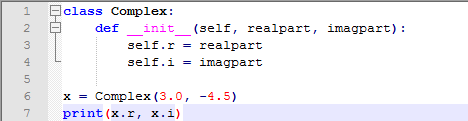
9.3.3 Instance Objects
接下来我们看看使用类实力我们可以干些什么~使用类实例必须使用属性引用的方式,无论是方法还是对象内的变量。记住对象的变量是不需要声明的,直接赋值就可以,这在使用上和一般的变量是一样的:

类实例中的方法调用起来和一般的函数是一样的,只要加上实例的名字作为前缀就可以了。但是要注意区分实例方法和类方法,这个以后会提到的。
9.3.4 Method Objects
通常情况我们使用实例的方法的时候都会用实例名点方法名,比如在MyClass例子中的x.f()。但这个方法同时也是一个对象,所以可以将他指向一个变量来方便的使用:
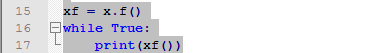
这段代码将会不停的打印hello world直到时间的尽头或者进程被关闭。当一个方法被调用的时候到底发生了什么那?事实上你可以已经猜到了:在调用实例对象的方法时,首先将实例对象作为参数传递,也就是说我们调用的x.f()相当于MyClass.f(x)。如果调用的方法接受了参数,那么这些参数都会被排在实例之后被传递。如果还是不明白也没关系,可以看看实现部分。当一个实例的属性(非变量属性)被调用的时候,他会先去类对象中搜索。其实方法对象是个很抽象的对象,他是把函数对象和实例对象合在一起然后在把参数作为列表传递给他。
9.3.5 Class and Instance Variables
实例变量主要为了数据的特性,类变量是整个类的特性。这么说怪怪的,看个例子很容易明白就是定义在不同的位置而已:
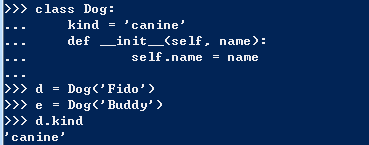

前面我们说过,共享的数据如果是可修改的,那么将会产生些奇妙的影响,看两个例子:
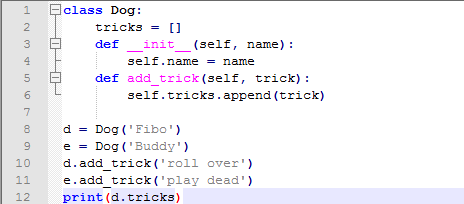
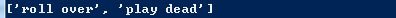


这个例子生动形象的说明的类变量和实例变量的却别,在使用的时候一定要明确自己的目的再进行设计。
9.4 Random Remarks
变量和方法如果同名的话会有冲突,原文中说变量属性会重构方法属性,但是我实验了发现好像恰恰想反?总之在大型程序中为了避免出现那些难以发现的错误,最好使用一个起名的协议。比如大写方法名、在数据属性名前置一个特殊的字符、或者使用动词作为方法名、使用名词作为变量名。
变量属性可以被方法和用户同样的调用,换句话说类并不能实现完全抽象的类型。事实上,在python中没什么能够做到隐藏起数据——这是基于协议的。另一方面,python用C实现,使用C语言可以完全隐藏实现的细节,并且控制访问类。
用户在使用变量属性的时候一定要小心,因为有些变量属性是由方法维护的,用户直接修改可能会导致混乱。所以用户可以向一个实例中增加自己的变量属性,这就不会影响方法了(注意不要出现命名冲突)。可见命名协议真的是减少了很多让人头疼的事。
在模块内引用变量属性或者其他方法时是绝对没有简写方式的!!!!因为这样会增加代码的可读性,这样一眼扫过也不会混淆局部变量和实例的变量属性~
通常来说方法的第一个参数就是self,这只是一个协议self并没有其他的什么特殊含义。无论如何,如果你不遵循这个协议的话其他的程序员可能很难读懂你的代码。而且一个类浏览器很可能就是依靠这个协议工作的。
每一个类的函数对象都会为这个类的实例提供方法属性,但是并不强制要求函数的定义必须在类的声明内。可以将一个函数对象分配给类中的一个局部变量:
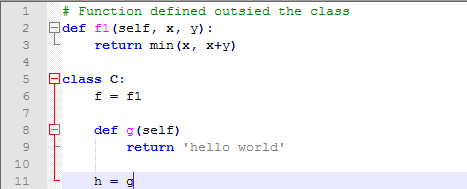
在这个例子中f,h,g都是类C的属性,他们也是类C实例变量的方法。这里的h和g是完全一样的,要注意的是这么做除了降低可读性外没有其他任何优点。方法还可以调用实例中的其他方法:
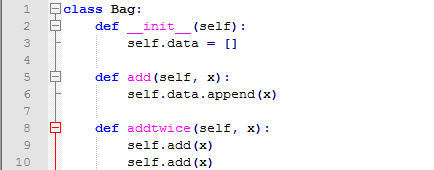
方法也是可以是像函数一样使用全局变量的,方法调用全局变量的作用域就是那个定义它的模块。一般来说方法使用全局变量并没有什么必要性,但也有几种情况比较合适:一种情况是方法可以使用被引入的函数和模块;通常来说类包含的方法都是它定义在自己的全局作用域中的,下一章我们会看到为什么一个方法引用自己的类。每个变量都是一个对象,所以他们也是一种类,他被作为object.__class__。
9.5 Inheritance
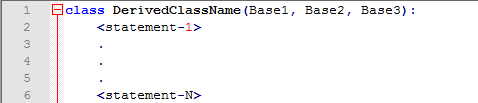
当然,既然叫做类肯定就是支持继承的,要不都对不起这个名字。衍生类的语法一般是这样的:
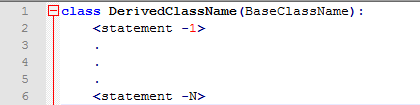
BaseClassName必须在定义衍生类的定义作用域中(比如说我们做一个继承自list的衍生类,因为list本身定义在了解释器的全局变量中,所以直接在解释器中定义这个衍生类就可以了)。在基类名字那个部分可以写任意的表达式,这是很有用的比如基类在别的模块中:

当一个衍生类被创建之后,python会记住他的基类,这是为了使用类的特性而这么规定的。当引用一个类的属性时,在当前类中没有找到就会去他的基类中寻找,这种查找方式是递归的,就是说如果基类中也没有就会去基类的父类中寻找(前提是他有父类)。
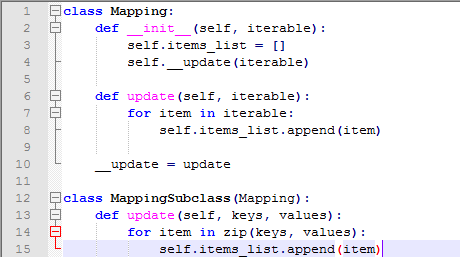
衍生类的实例没有什么特别,和一般的类是一样的。方法引用是这样的:首先寻找一致的属性,如果有必要再去基类中寻找,如果找到有效的方法就会返回一个函数对象。衍生类可以重写基类的方法,因为方法在调用同对象中其他方法时是没有优先权的,所以一个基类中的方法在调用基类中的另一个方法时有可能会调用到衍生类的方法。
一个重构的方法事实上想要扩展新的功能,而不是简单的取代基类方法的名字。调用基类方法很简单:直接写BaseClassName.MethodName(self, arguments)。这有时候对用户来说也是有用的。注意BaseClassName一定要是可访问的,就是他的作用域一定能被访问到。
python有两个内建的函数用来参与继承相关的工作:
- 使用isinstance(obj, instance)来检查instance是不是obj类的实例。如果是就会返回True,不是就返回False。每个实例的__class__属性都包含这个实例属于哪个模块哪个类型。
- 使用issubclass(subclass, baseclass)来检查subclass是不是baseclass的子类。是就返回True,不是就返回False。
9.5.1 Multiple Inheritance
9.6 Private Variables
9.7 Odds and Ends
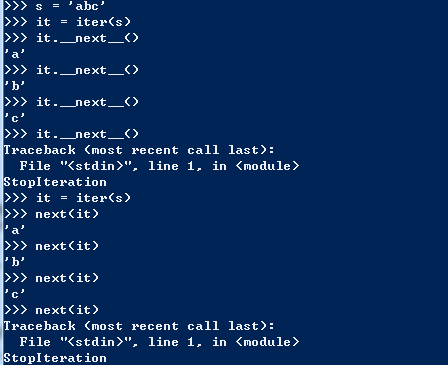
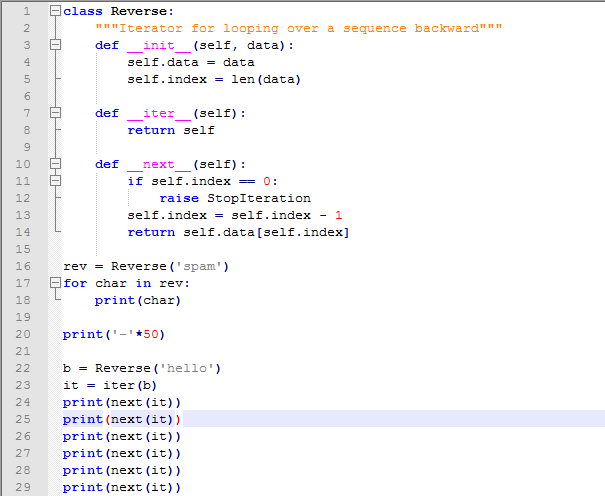
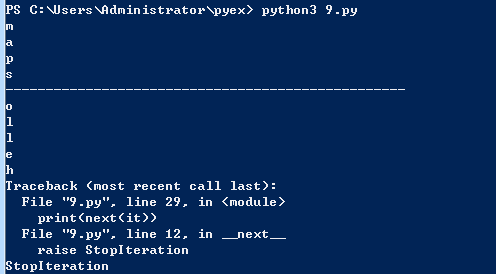
9.8 Iterators
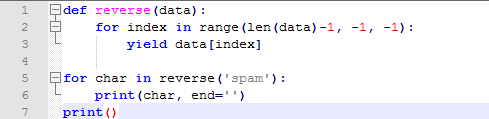
9.9 Generators
9.10 Generator Expressions
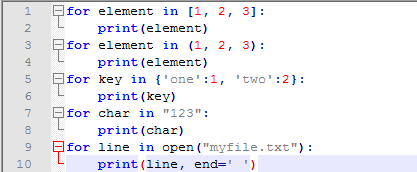
一些简单发生器可以使用表达式的方法来编写,就好比以前我们看到的列表推导式那样不过这次我们不使用方括号而是圆括号。表达式中发生器直接被函数使用,虽然发生器表达式更加精简,但是功能和多样性都不如正常的发生器协议,但是他比同样功能的列表推导式在内存使用上更加友善: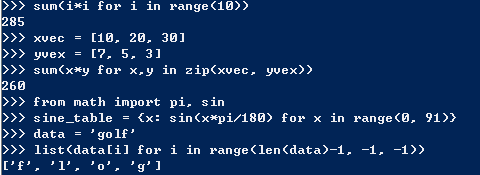


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









