







本文已经过时了,请查看最新小白爬虫第一弹之抓取妹子图 | 静觅
Code Change World!
本修改为在原基础上的一次学习与优化,毕竟刚开始学习,故代码中注释有所保留,方便以后回顾与学习语法。
请先了解原来能实现的目标,在此不再赘述,原文地址Python爬虫实战四之抓取淘宝MM照片,感谢作者的代码与思路。
本修改详情
- 代码改写为python3.5运行,因为3.5版本语法与模块有所变更
- 增加cookie验证解决跳转
- 无法保存图片能够容错而不是停止运行
- 其他细节修改
流程修改为:
加上cookie与伪装浏览器后先保存所有详情页,因为cookie有过期时间,而保存所有图片太耗时,故先保存详情页面下来,再提取网址获取图片。也可以将提取出来的地址保存为文件再导入获取图片,另一个思路而已,皆可行。
代码部分:
spider.py#!/usr/bin/python
# -*- coding:utf-8 -*-
import urllib.request
import re
import tool
import os
import http.cookiejar
#抓取MM
class Spider:
#页面初始化
def __init__(self):
self.siteURL = 'https://mm.taobao.com/json/request_top_list.htm'
self.tool = tool.Tool()
#获取索引页面的内容
def getPage(self,pageIndex):
url = self.siteURL + "?page=" + str(pageIndex)
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
return response.read().decode('gbk')
#获取索引界面所有MM的信息,list格式
def getContents(self,pageIndex):
page = self.getPage(pageIndex)
pattern = re.compile('<div class="list-item".*?pic-word.*?<a href="(.*?)".*?<img src="(.*?)".*?<a class="lady-name.*?>(.*?)</a>.*?<strong>(.*?)</strong>.*?<span>(.*?)</span>',re.S)
items = re.findall(pattern,page)
contents = []
for item in items:
contents.append([item[0],item[1],item[2],item[3],item[4]])
return contents
#获取MM个人详情页面
def getDetailPage(self,infoURL):
def makeMyOpener(head = {
'accept-encoding':'deflate, sdch',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
#此处填写浏览器发送的cookie数据,开发者模式可捕获
#'cookie':'',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36'
}):
cookie = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
oper = makeMyOpener()
uop = oper.open(infoURL)
data = uop.read().decode('gbk')
return data
# response = urllib.request.urlopen(infoURL)
# return response.read().decode('gbk')
#获取个人文字简介
def getBrief(self,page):
pattern = re.compile('<div class="mm-aixiu-content".*?>(.*?)<!--',re.S)
result = re.search(pattern,page)
#print(result.group())
return self.tool.replace(result.group(1))
#获取页面所有图片
def getAllImg(self,page):
pattern = re.compile('<div class="mm-aixiu-content".*?>(.*?)<!--',re.S)
#个人信息页面所有代码
content = re.search(pattern,page)
#从代码中提取图片
patternImg = re.compile('<img.*?src="(.*?)"',re.S)
images = re.findall(patternImg,content.group(1))
return images
#保存多张写真图片
def saveImgs(self,images,name):
number = 1
print (u"发现",name,u"共有",len(images),u"张照片")
for imageURL in images:
splitPath = imageURL.split('.')
splitPath=splitPath
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = "jpg"
fileName = name + "/" + str(number) + "." + fTail
imageURL='https:'+imageURL
self.saveImg(imageURL,fileName)
number += 1
# 保存头像
def saveIcon(self,iconURL,name):
splitPath = iconURL.split('.')
fTail = splitPath.pop()
fileName = name + "/icon." + fTail
self.saveImg(iconURL,fileName)
#保存个人简介
def saveBrief(self,content,name):
fileName = name + "/" + name + ".txt"
f = open(fileName,"w+")
print (u"正在保存信息为",fileName)
f.write(content.decode('utf-8'))
#保存图片地址页到各文件夹中
def saveToLocal(self,Li,name):
fileName = name + "/" +"urlPage.txt"
print (u"正在保存图片地址页:",fileName)
#f.write(content.decode('utf-8'))
# pre=pre.replace("[","")
# pre=pre.replace("]","")+"\n"
#print (pre)
f = open(fileName,"w")
f.write(Li)
f.close()
#追加方式写入当前爬行的名字,后续调用
content=name+" "
with open('url.txt', 'a') as url:
url.write(content)
url.close()
print (name+u"追加完成!\n")
#传入图片地址,文件名,保存单张图片
def saveImg(self,imageURL,fileName):
try:
u = urllib.request.urlopen(imageURL)
data = u.read()
f = open(fileName, 'wb')
f.write(data)
print (u"正在保存的一张图片为",fileName)
f.close()
except urllib.request.URLError as e:
print (e.reason)
#创建新目录
def mkdir(self,path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists=os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
print (u"新建了名字叫做",path,u'的文件夹')
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print (u"名为",path,'的文件夹已经创建成功')
return False
#将一页淘宝MM的信息保存起来
def savePageInfo(self,pageIndex):
#获取第一页淘宝MM列表
contents = self.getContents(pageIndex)
for item in contents:
#item[0]个人详情URL,item[1]头像URL,item[2]姓名,item[3]年龄,item[4]居住地
print (u"发现一位名字叫",item[2],u"年龄",item[3],u",她在",item[4])
print (u"正在保存",item[2],"的信息")
print (u"个人详情地址是","https:"+str(item[0]))
#个人详情页面的URL
detailURL = "http:"+str(item[0])
#得到个人详情页面代码
detailPage = self.getDetailPage(detailURL)
#获取个人简介
brief = self.getBrief(detailPage)
#获取所有图片列表
images = self.getAllImg(detailPage)
self.mkdir(item[2])
#保存个人简介
self.saveBrief(brief.encode('utf-8'),item[2])
#保存图片地址页到本地
self.saveToLocal(detailPage,item[2])
#保存头像
self.saveIcon("https:"+str(item[1]),item[2])
#删除旧名单(如果有)
def deleteOldTxt(self):
filename = 'url.txt'
if os.path.exists(filename):
os.remove(filename)
print("\n发现旧名单,已删除\n采集开始\n")
#传入起止页码,获取MM页面保存
def savePagesInfo(self,start,end):
for i in range(start,end+1):
print (u"正在寻找第",i,u"个地方")
self.savePageInfo(i)
#保存图片
#self.saveImgs(images,item[2])
#读取名字list
def openNameList(self):
with open("url.txt","r") as f:
for line in f:
line=line.strip()
# line.split(",")
# result.append(line)
#result.append(line.split(","))
#\s匹配空格与tab,\s+表示至少一个
result=re.split(r'\s+',line)
return result
#逐个调取文件夹下页面中地址来保存
def saveAll(self):
i=spider.openNameList()
for name in i:
print ("当前正在保存的是"+name+"的图片")
filepath=name+"/urlPage.txt"
with open(filepath,"r") as urlContent:
urlContent=urlContent.read()
images=spider.getAllImg(urlContent)
spider.saveImgs(images,name)
#传入起止页码即可,在此传入了6,10,表示抓取第6到10页的MM
spider = Spider()
spider.deleteOldTxt()
spider.savePagesInfo(6,10)
print("\n第一步保存信息完成,输入y保存所有图片,其他信息退出:")
a=input()
if a=='y':
spider.saveAll()
else:
passtool.py#!/usr/bin/python
#-*- coding:utf-8 -*-
import re
#处理页面标签类
class Tool:
#去除img标签,1-7位空格,
removeImg = re.compile(r'<img.*?>| {1,7}| ')
#删除超链接标签
removeAddr = re.compile(r'<a.*?>|</a>')
#把换行的标签换为\n
replaceLine = re.compile(r'<tr>|<div>|</div>|</p>')
#将表格制表<td>替换为\t
replaceTD= re.compile(r'<td>')
#将换行符或双换行符替换为\n
replaceBR = re.compile(r'<br><br>|<br>')
#将其余标签剔除r
removeExtraTag = re.compile(r'<.*?>')
#将多行空行删除
removeNoneLine = re.compile(r'\n+')
#删除
removeSpace=re.compile(r' ')
def replace(self,x):
x = re.sub(self.removeImg,"",x)
x = re.sub(self.removeAddr,"",x)
x = re.sub(self.replaceLine,"\n",x)
x = re.sub(self.replaceTD,"\t",x)
x = re.sub(self.replaceBR,"\n",x)
x = re.sub(self.removeExtraTag,"",x)
x = re.sub(self.removeNoneLine,"\n",x)
x = re.sub(self.removeSpace,"",x)
#strip()将前后多余内容删除
return x.strip()
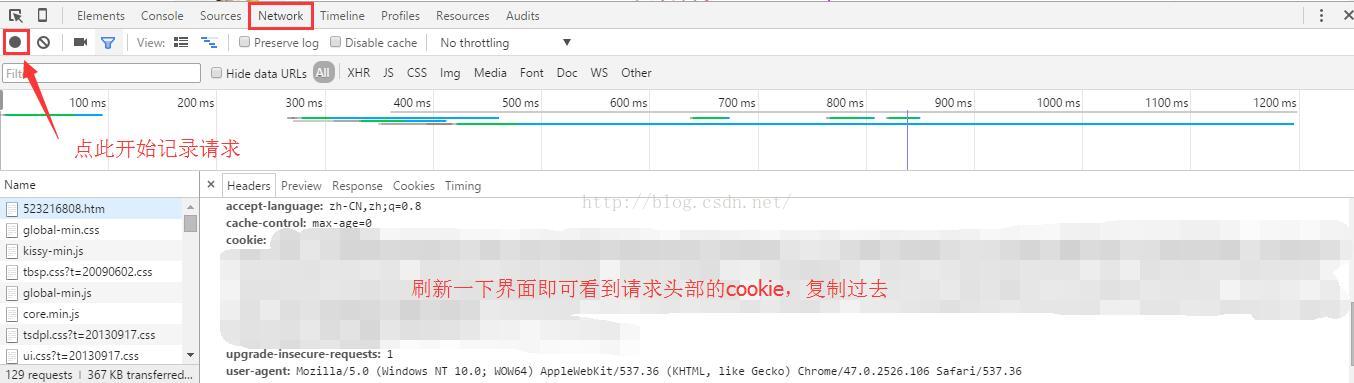
cookie获取方式:
注意只取cookie部分复制,把#去掉
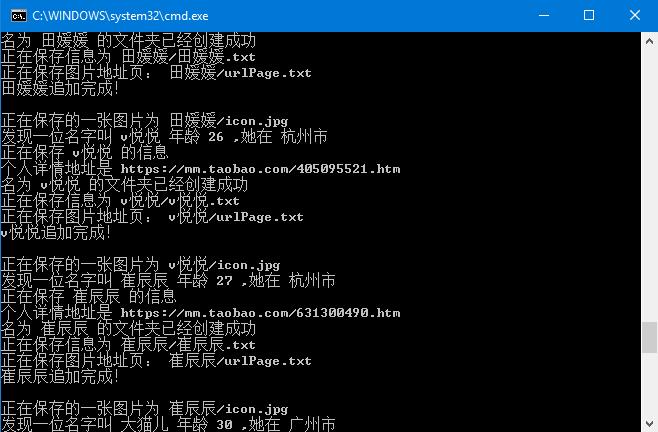
实现效果:
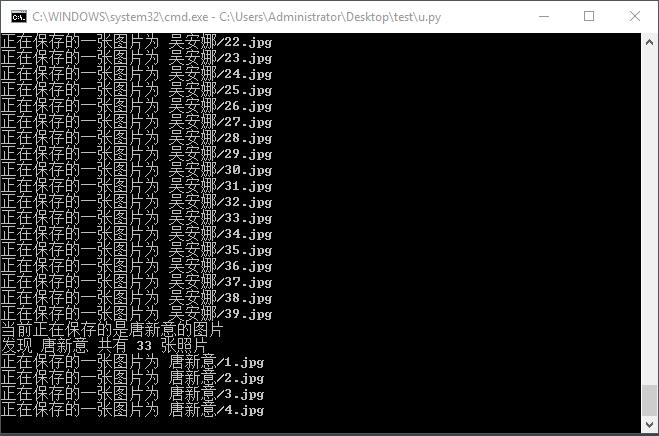
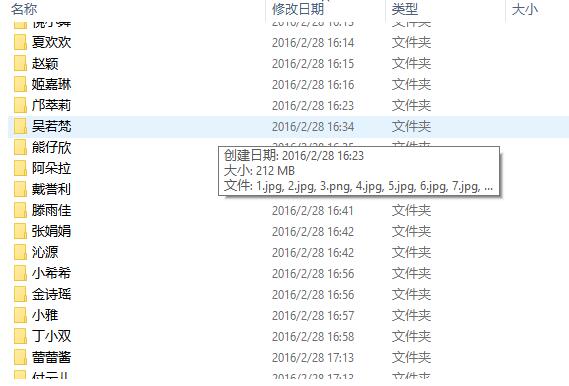
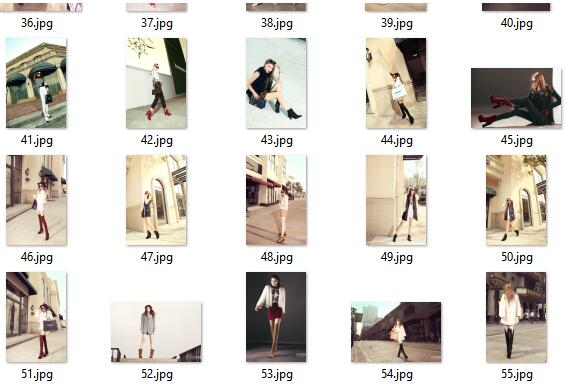
总结:
思路很重要,与大家一起学习。小生刚出道,大神勿喷。
欢迎大家探讨。
2016-3-2














 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









