







堆排序(Heap Sort)方法由 J. Willioms 在1964年提出。堆排序只需要一个记录大小的而辅助存储空间,每个待排序的记录仅仅占用一个记录大小的存储空间。
堆的定义
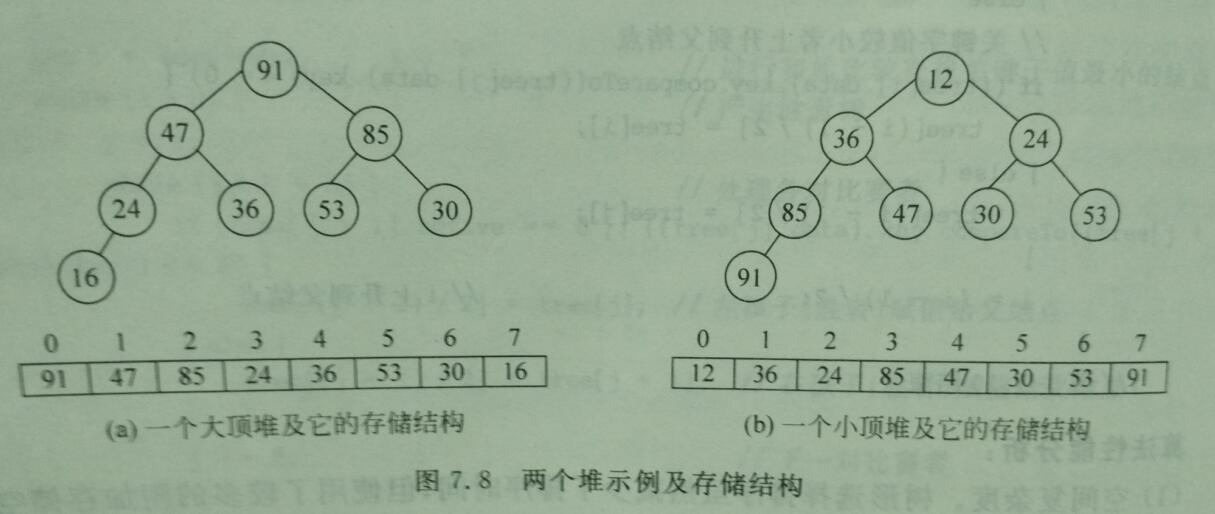
假设n个记录关键字的序列当且仅当满足公式时,称为堆。堆包括小顶堆和大顶堆。堆可以用二叉树来描述。
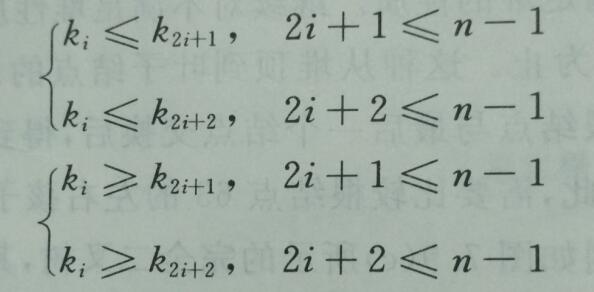
基本思想
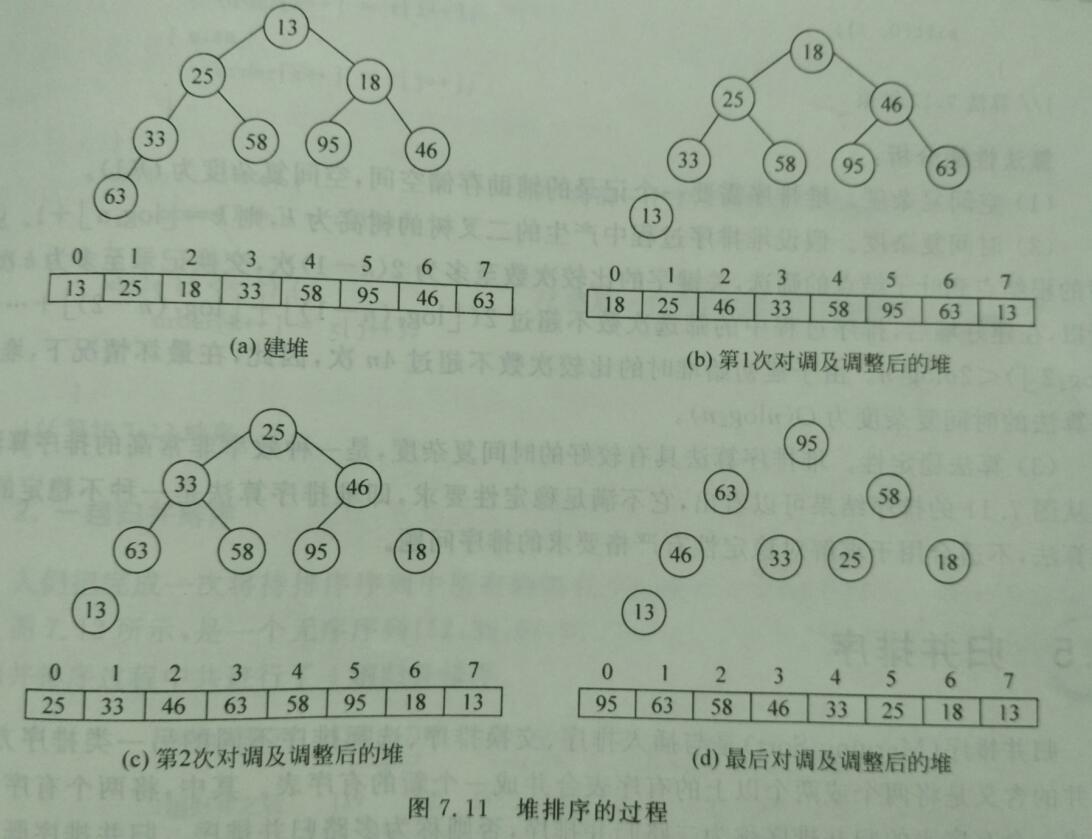
以小顶堆为例。首先将n条记录按照关键字值的大小建成初始堆,将对顶元素r[0]与r[n-1]交换(或者输出);然后,将剩下的r[0]..r[n-2]序列调整成堆,再将r[0]与r[n-2]交换,又将剩下的r[0]..r[n-3]序列调整成堆,如此反复。
主要步骤
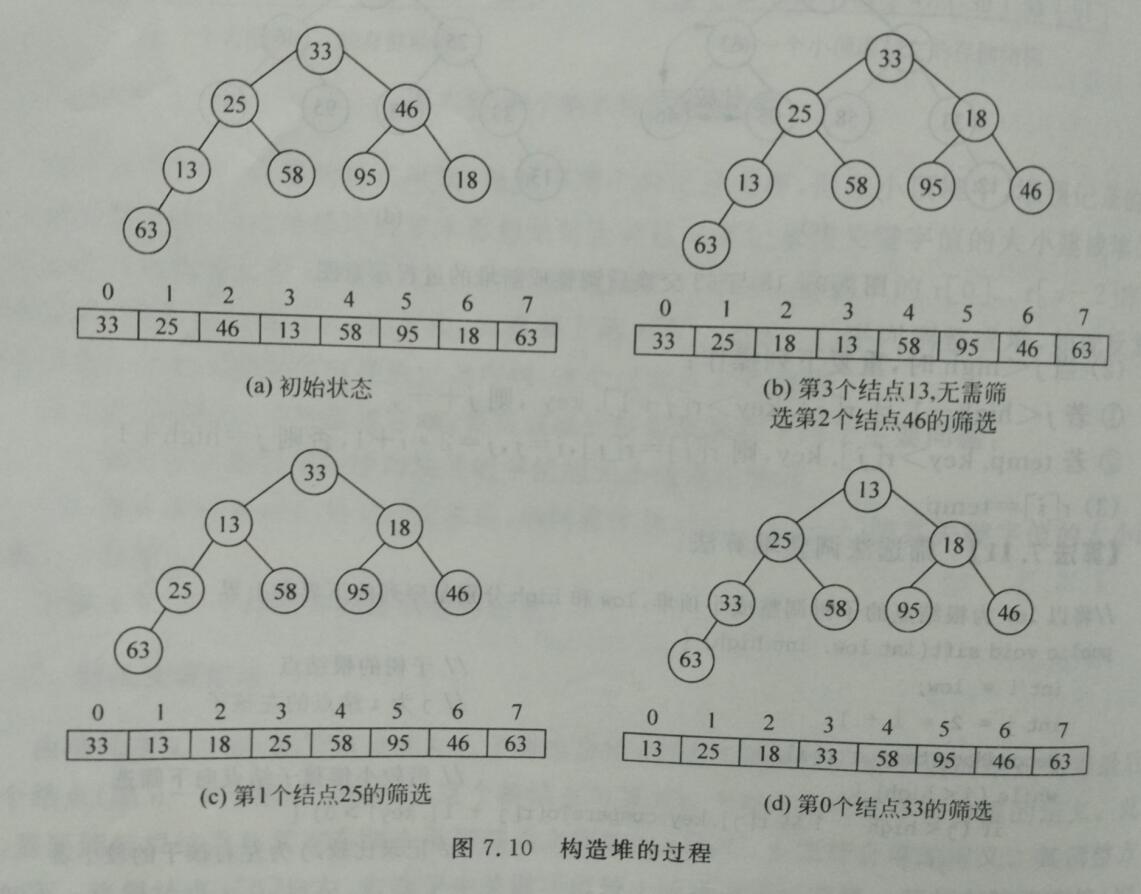
1、构建初始堆
因为完全二叉树的最后一个非叶子节点的编号(即数组下标)是(n/2)- 1(其中n/2向下取整),所以调整只需要从编号(n/2)- 1个节点开始。
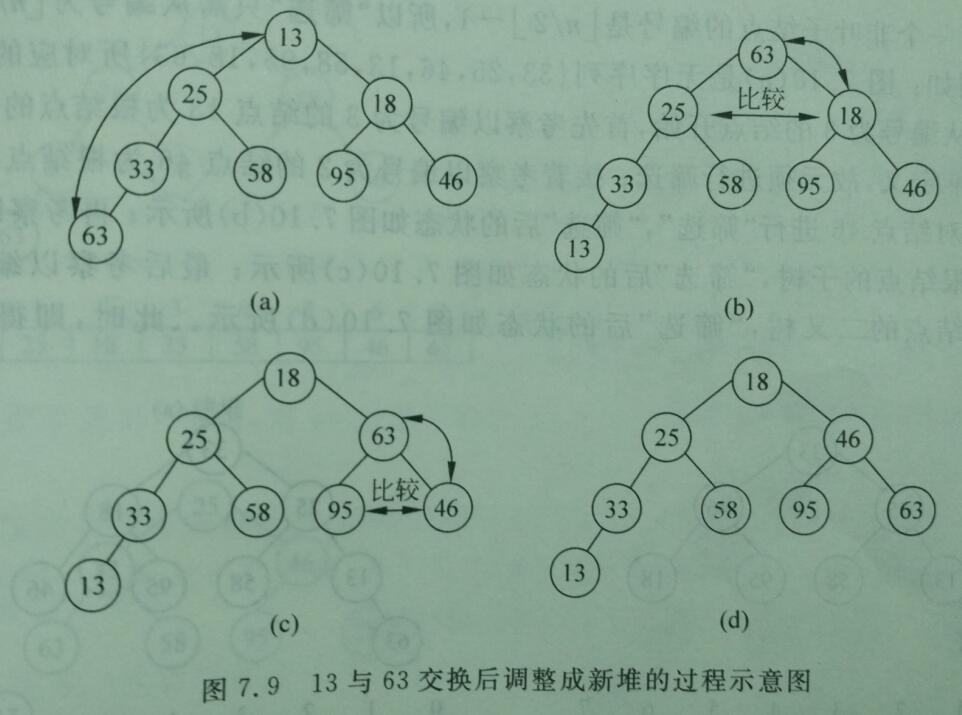
2、调整堆
3、堆排序
性能分析
空间复杂度:堆排序需要一个记录的辅助存储空间用于交换,空间复杂度为 O(1) 。
时间复杂度:最好最坏和平均都是 O(nlogn) 。
算法稳定性:不稳定。
java实现代码:
/**
* 堆排序:max堆 O(nlogn)
* @param arr
*/
public static <T extends Comparable<T>> void heapSort(T[] arr) {
// 对数组建堆(max堆)
// 因为完全二叉树的最后一个非叶子节点的编号(即数组下标)是(n/2)- 1(其中n/2向下取整)
// 所以调整只需要从编号(n/2)- 1个节点开始。
for (int i = arr.length/2; i >= 0; i--) {
percDown(arr, i, arr.length);
}
// 删除堆中的最大值
for (int i = arr.length - 1; i > 0; i--) {
swap(arr, 0, i); // 堆顶最大元素交换到最后
percDown(arr, 0, i); // 重新调整堆
}
}
/**
* 获取第i节点的左儿子节点
* @param i
* @return
*/
public static int leftChild(int i) {
return 2 * i + 1;
}
/**
* 从第i个节点位置开始下滤
* @param arr 数组堆(max堆)
* @param i 开始下滤的位置
* @param n 堆的大小
*/
public static <T extends Comparable<T>> void percDown(T[] arr, int i, int n) {
int child;
T tmp;
for (tmp = arr[i]; leftChild(i) < n; i = child) {
child = leftChild(i);
// max堆中取较大者, min堆中取较小者
if (child != n - 1 && arr[child].compareTo(arr[child + 1]) < 0) {
child++;
}
// max堆中若父母节点值较小,则下滤,子孩子上移
// min堆中若父母节点值较大,则下滤,子孩子上移
if (tmp.compareTo(arr[child]) < 0) {
arr[i] = arr[child];
} else {
break; // 退出循环
}
}
arr[i] = tmp; // 当前子树原来的根节点调整后的位置
}
/**
* 交换
* @param t1
* @param t2
*/
public static <T extends Comparable<T>> void swap(T[] arr, int i, int j) {
T tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}参考:
1. 刘小晶,数据结构——Java语言描述(第2版),清华大学出版社
2. MARK A W, 数据结构与算法分析: Java 语言描述,机械工业出版社















 5301
5301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









