









一、准备工作
1、安装Linux、JDK、关闭防火墙、配置主机名
这部分上面已经介绍过来,这里就不在赘述。
2、安装Hadoop
解压:tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
设置Hadoop的环境变量:vi ~/.bash_profile
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
生效环境变量:source ~/.bash_profile
3.Hadoop的目录结构

三种安装模式:本地模式、伪分布模式、全分布模式(至少要三台机器)
二、本地模式:一台
特点:没有HDFS、只能测试MapReduce程序
MapReduce处理的是本地Linux的文件数据
配置Hadoop的Java环境
vi hadoop-env.sh
25 export JAVA_HOME=/root/training/jdk1.8.0_144
测试MapReduce程序:
1、创建目录 mkdir ~/input
2、运行
例子:cd /root/training/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount ~/input/data.txt ~/output
三、伪分布模式:一台机器
特点:是在单机上,模拟一个分布式的环境, 具备Hadoop的功能
HDFS:NameNode + DataNode + SecondaryNameNode
Yarn : ResourceManager + NodeManager
hadoop伪分布的配置文件配置:
hdfs-site.xml
原则:一般数据块的冗余度跟数据节点(DataNode)的个数一致;最大不超过3
<!--表示数据块的冗余度,默认:3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
先不设置
<!--是否开启HDFS的权限检查,默认为true-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
core-site.xml
<!--配置NameNode地址,9000是RPC通信端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property>
<!--HDFS数据保存在Linux的哪个目录,默认值是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
mapred-site.xml 默认没有 cp mapred-site.xml.template mapred-site.xml
<!--MR运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<!--Yarn的主节点RM的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property>
<!--MapReduce运行方式:shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置完成后格式化HDFS:(NameNode)
hdfs namenode -format
格式化成功的日志:
Storage directory /root/training/hadoop-2.7.3/tmp/dfs/name has been successfully formatted.
启动停止Hadoop的环境
start-all.sh
stop-all.sh
访问:通过web界面
HDFS:http://192.168.160.111:50070
Yarn: http://192.168.160.111:8080
运行例子:
/root/training/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /output/0407
四、全分布模式
特点:正式的分布式环境,用于生产,做好规划
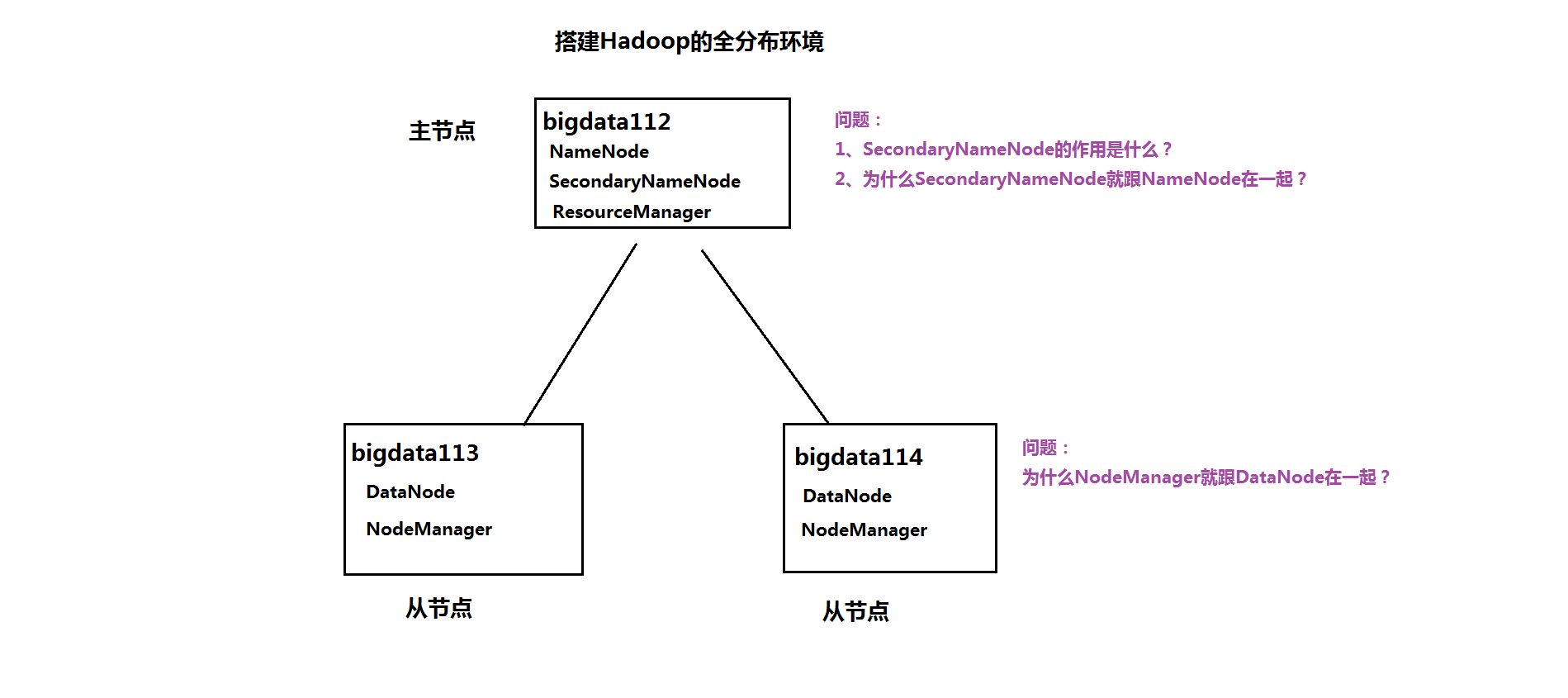
1、准备工作
(*)关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
(*)安装JDK
(*)配置主机名 vi /etc/hosts
192.168.157.112 bigdata112
192.168.157.113 bigdata113
192.168.157.114 bigdata114
(*)配置免密码登录:两两之间的免密码登录
原理:
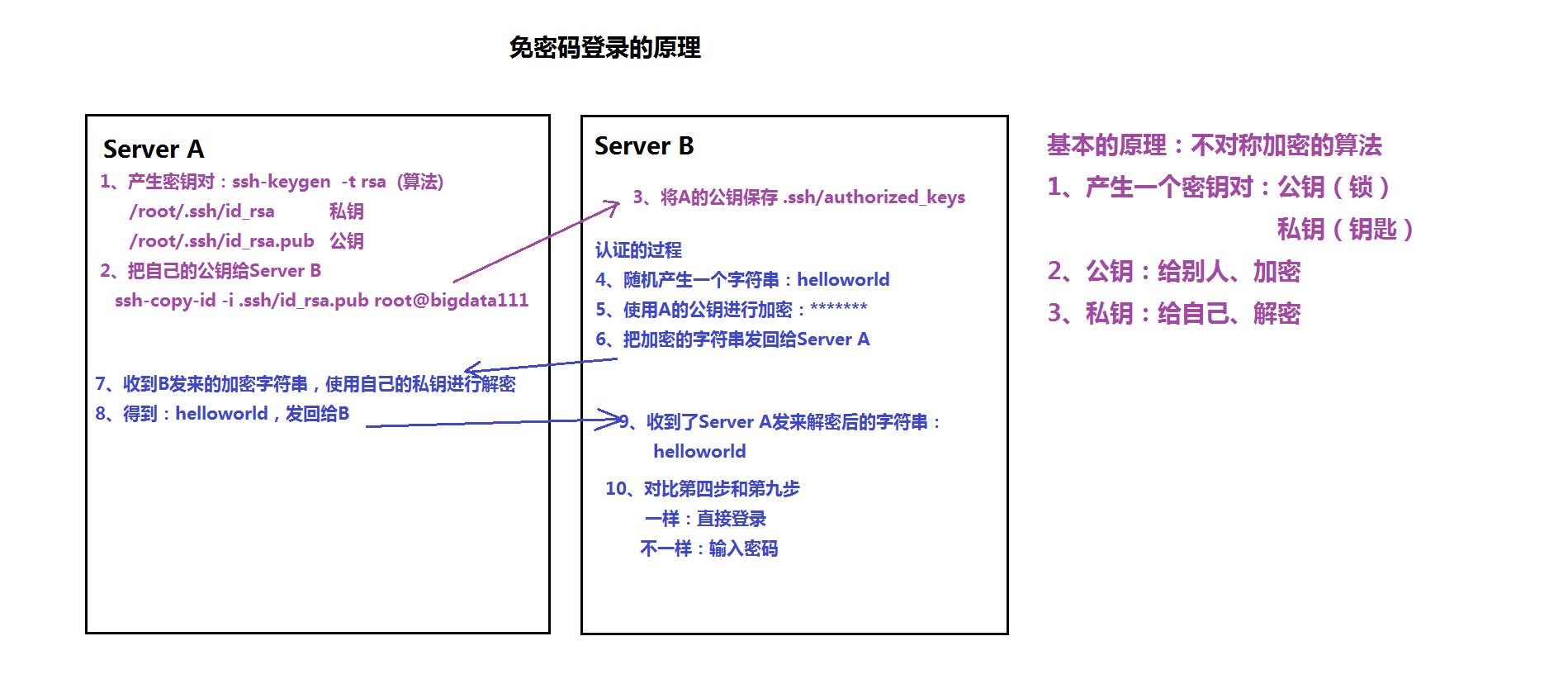
ssh-keygen -t rsa
(2) 每台机器把自己的公钥给别人
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata112
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata113
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata114
(*)保证每台机器的时间同步
如果时间不一样,执行MapReduce程序的时候可能存在问题
2、在主节点上(bigdata112)安装
(1)解压设置环境变量
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
设置:112 113 114
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
(2) 修改配置文件
hadoop-env.sh JAVA_HOME /root/training/jdk1.8.0_144
hdfs-site.xml
<!--表示数据块的冗余度,默认:3-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
core-site.xml
<!--配置NameNode地址,9000是RPC通信端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata112:9000</value>
</property>
<!--HDFS数据保存在Linux的哪个目录,默认值是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
mapred-site.xml 默认没有 cp mapred-site.xml.template mapred-site.xml
<!--MR运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<!--Yarn的主节点RM的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata112</value>
</property>
<!--MapReduce运行方式:shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
slaves
bigdata113
bigdata114
(3) 格式化NameNode: hdfs namenode -format
(4) 把主节点上配置好的hadoop复制到从节点上
scp -r hadoop-2.7.3/ root@bigdata113:/root/training
scp -r hadoop-2.7.3/ root@bigdata114:/root/training
(5) 在主节点上启动 start-all.sh















 1684
1684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









