







前言
Android开发中,base64编码还是比较常用的,用归用,其原理还是有必要理解的。
Android中使用base64编码:
private void base64Test() {
String baseStr = "ab中国。";
byte[] bytes = baseStr.getBytes();
//默认编码
System.out.println("DEFAULT :" + ByteUtil.bytes2Str(Base64.encode(bytes, Base64.DEFAULT)));
//末尾少填充符=
System.out.println("NO_PADDING:" + ByteUtil.bytes2Str(Base64.encode(bytes, Base64.NO_PADDING)));
//每组(76个字符一组)少了换行符\n
System.out.println("NO_WRAP :" + ByteUtil.bytes2Str(Base64.encode(bytes, Base64.NO_WRAP)));
//Windows操作系统采用两个字符来进行换行,即CRLF
System.out.println("CRLF :" + ByteUtil.bytes2Str(Base64.encode(bytes, Base64.CRLF)));
//编码字符的'+', '/'替换成了'-', '_'编码,适用于url编码
System.out.println("URL_SAFE :" + ByteUtil.bytes2Str(Base64.encode(bytes, Base64.URL_SAFE)));
System.out.println("NO_CLOSE :" + ByteUtil.bytes2Str(Base64.encode(bytes, Base64.NO_CLOSE)));
}
注意:Unix/Linux/Mac OS X操作系统采用单个字符LF来进行换行
- CR:Carriage Return,对应ASCII中转义字符\r,表示回车
- LF:Linefeed,对应ASCII中转义字符\n,表示换行
- CRLF:Carriage Return & Linefeed,\r\n,表示回车并换行
上述输出:
DEFAULT :YWLkuK3lm73jgII=
NO_PADDING:YWLkuK3lm73jgII
NO_WRAP :YWLkuK3lm73jgII=
CRLF :YWLkuK3lm73jgII=
URL_SAFE :YWLkuK3lm73jgII=
NO_CLOSE :YWLkuK3lm73jgII=
实际使用Base64.DEFAULT,Base64.NO_WRAP居多,上面五种编码规则是一样的,只不过输出的时候是为了适配不同业务场景。本次以Base64.NO_WRAP说明编码原理,理解字符ab中国。如何经过base64编码后输出YWLkuK3lm73jgII=
base64编码规则
- 把3个字节变成4个字节。
- 每76个字符加一个换行符。
- 最后的结束符也要处理。
简单就是说:
Base64编码使用了ASCII编码中64个可打印的字符(大写字母A-Z,小写字母a-z,数字0~9以及"+","/")将任意字节数据进行编码。Base64编码将串起来的二进制以6位进行分割.所以分切之前的二进制位数应该是24的倍数(即6,8的最小公倍数)。如果不足24位,则在编码后数据后面添加"=",一个"="想当于6个二进制位.数据量是原先的4/3倍。
上面分割的每6位二进制字符为一组,每一组转成是十进制值(码值),然后根据下面的Base64编码表的码值找到对应的字符(编码后的实际字符),最后将字符拼接起来就是最终的编码字符。
Base64编码表
码值 字符
0 A 8 I 16 Q 24 Y 32 g 40 o 48 w 56 4
1 B 9 J 17 R 25 Z 33 h 41 p 49 x 57 5
2 C 10 K 18 S 26 a 34 i 42 q 50 y 58 6
3 D 11 L 19 T 27 b 35 j 43 r 51 z 59 7
4 E 12 M 20 U 28 c 36 k 44 s 52 0 60 8
5 F 13 N 21 V 29 d 37 l 45 t 53 1 61 9
6 G 14 O 22 W 30 e 38 m 46 u 54 2 62 +
7 H 15 P 23 X 31 f 39 n 47 v 55 3 63 /
示例说明base64编码过程
上面说了其编码规则,下面通过demo理解其实现过程。看图:
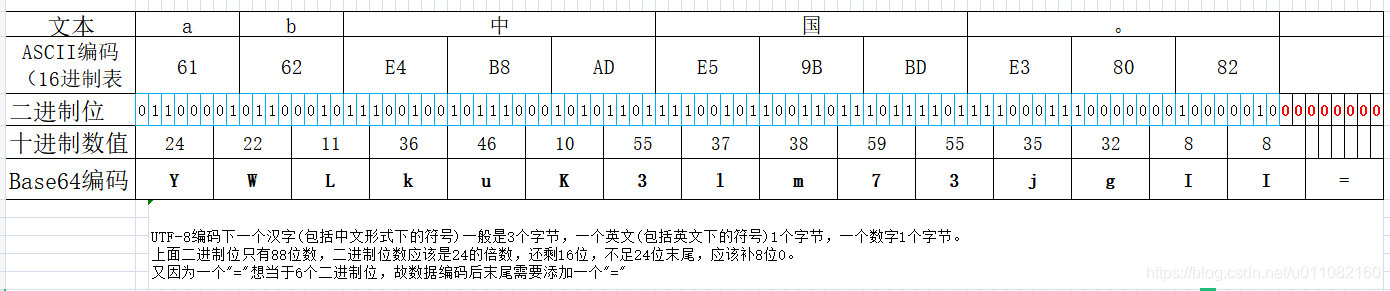
对应的代码
public static void main(String[] args) {
byte[] strBytes = new byte[0];
try {
//UTF-8编码下一个汉字(包括中文形式下的符号)一般是3个字节,一个英文(包括英文下的符号)1个字节,一个数字1个字节
//不同字符编码规则,base64输出结果也不同
strBytes = "ab中国。".getBytes("UTF-8");
} catch (Exception e) {
e.printStackTrace();
}
if(strBytes == null){
return;
}
//示例仅处理中英文,其它语言不处理
//将字符字节数组,转成二进制字符串
String s = Base64TestUtils.byteArrToBinStr(strBytes);
System.out.println(s);
System.out.println();
int length = s.length();
for (int i = 0; i < length; i += 6) {
int end;
if (i + 6 > length) {
end = length;
} else {
end = i + 6;
}
String substring = s.substring(i, end);
//每6位一组
if (substring.length() == 6) {
System.out.println(substring + "," + Integer.parseInt(substring, 2));
} else {
//不足6位,低位补0,凑够6位
substring = Base64TestUtils.binaryFillZero(substring, 6,false);
System.out.println(substring + "," + Integer.parseInt(substring, 2));
//计算不需要补的等于号符号数,一个=等于6个二进制位
int fillZeroNum = length % 24 == 0 ? 0 : 24 - length % 24;
//等于号个数
int equalCharNum = fillZeroNum % 6 == 0 ? 0 : fillZeroNum / 6;
System.out.println("需要补等于号个数equalCharNum:" + equalCharNum);
}
}
}
/**
* byte数组转换为二进制字符串
**/
public static String byteArrToBinStr(byte[] strBytes) {
StringBuilder sb = new StringBuilder();
for (byte c : strBytes) {
String binary;
if (c >= 0 && c < 128) {//ASCII码,取值范围是0~127
binary = binaryFillZero(Integer.toBinaryString(c), 8);
} else {//汉字之类
//取低8位
binary = Integer.toBinaryString(c & 0xff);
}
sb.append(binary);
}
return sb.toString();
}
public static String binaryFillZero(String binaryString, int bitNum) {
return binaryFillZero(binaryString, bitNum, true);
}
/**
* 对二进制位高位或低位补0
*
* @param binaryString 二进制字符串
* @param bitNum 二进制位数
* @param prefix true前补0
* @return
*/
public static String binaryFillZero(String binaryString, int bitNum, boolean prefix) {
/* if (bitNum % 8 > 0) {
throw new IllegalArgumentException("不支持的bitNum:" + bitNum);
}*/
StringBuffer sb = new StringBuffer();
if (binaryString.length() < bitNum) {
for (int i = 0; i < bitNum - binaryString.length(); i++) {
sb.append(0);
}
}
if (prefix) {//高位补0
sb.append(binaryString);
} else {//低位补0
sb.insert(0,binaryString);
}
return sb.toString();
}
小结
上面主要说了base64编码的原理,解码原理是其逆向过程。如有不足,请指出修正。














 937
937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









