







Elasticsearch 是一个实时的分布式存储、搜索、分析的引擎。
我们平时使用的数据库也能做到实时 存储 搜索 分析,那么为什么要使用ElasticSearch呢?
相比于数据库,Elasticsearch的强大之处就是可以模糊查询。但是我们平时使用的数据库也可以模糊查询,比如说:
select * from table where name like '%Java%'是吧,这样也可以满足我们的需求,但是我们要知道的是,这类查询是不走索引的,不走索引意味着,只要数据量很大(1亿条),查询肯定会是秒级别的。
而且,即便给我们从数据库根据模糊匹配查出相应的记录了,那往往会返回大量的数据给我们,往往我们需要的数据量并没有这么多,可能50条记录就足够了。
还有一个就是:用户输入的内容往往并没有这么的精确,比如我从Google输入ElastcSeach(打错字),但是Google还是能估算我想输入的是Elasticsearch。
而Elasticsearch是专门做搜索的,就是为了解决上面所讲的问题而生的,换句话说:
- Elasticsearch对模糊搜索非常擅长(搜索速度很快)
- 从Elasticsearch搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
- 没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
下面我们就来学学为什么Elasticsearch可以做到上面的几点。
Elasticsearch的数据结构
通常,我们根据“完整的条件”查找一条记录叫做正向索引;我们一本书的章节目录就是正向索引,通过章节名称就找到对应的页码。为什么Elasticsearch为什么可以实现快速的“模糊匹配”/“相关性查询”,实际上是你写入数据到Elasticsearch的时候会进行分词。
比如说下面是一本书的目录:
| 母猪的产后护理 | 1 |
| 上兵伐谋 | 12 |
| 母猪的喂养 | 45 |
| 下兵伐战 | 89 |
其中,出现了两次“母猪”这个词,我们可以根据这些词找到对应的目录,同样,ElasticSearch也是这样做的 "母猪" - > 1,45
这就代表着,“母猪”这个词一定出现在第一页和第四十五页,这种根据某个词(不完整的条件)再查找对应的记录叫做倒排索引。
世界上有这么多的语言,那Elasticsearch怎么切分这些词呢?,Elasticsearch内置了一些分词器
- Standard Analyzer 。按词切分,将词小写
- Simple Analyzer。按非字母过滤(符号被过滤掉),将词小写
- WhitespaceAnalyzer。按照空格切分,不转小写
- ....等等等
Elasticsearch是老外写的,内置的分词器都是英文类的,而我们用户搜索的时候往往搜的是中文,现在中文分词器用得最多的就是IK。
我们输入一段文字,Elasticsearch会根据分词器对我们的那段文字进行分词,这些分词汇总起来我们叫做Term Dictionary(术语词典),而我们需要通过分词找到对应的记录。在Term Dictionary中的词由于是非常非常多的,所以我们会为其进行排序,等要查找的时候就可以通过二分来查,不需要遍历整个Term Dictionary,由于Term Dictionary的词实在太多了,不可能把Term Dictionary所有的词都放在内存中,于是Elasticsearch还抽了一层叫做Term Index,这层只存储 部分 词的前缀,Term Index会存在内存中(检索会特别快)
ElasticSearch术语对比
| ElasticSearch集群 | 关系型数据库 |
| 索引(index) | 数据库 |
| 类型(type) | 表 |
| 文档 | 行 |
| 字段 | 列 |
一个Elasticsearch集群会有多个Elasticsearch节点,所谓的节点就是运行着Elasticsearch进程的机器。在众多节点中有一个Master Node 主要负责维护索引元数据,负责切换主分片和副本分片,如果主节点挂了,会选举出一个新的主节点。
分片是什么?
Elasticsearch最外层的是索引(相当于数据库),一个索引(index)的数据可以分发到不同的Node上进行存储,这个操作就叫分片。
为什么要分片?
1.如果一个Index的数据量太大,只有一个分片,那只会在一个节点上存储,随着数据量的增长,一个节点未必能把一个Index存储下来。
2.多个分片,在写入或查询的时候就可以并行操作(从各个节点中读写数据,提高吞吐量)
现在问题来了,如果某个节点挂了,那部分数据就丢了吗?显然Elasticsearch也会想到这个问题,所以分片会有主分片和副本分片之分(为了实现高可用)数据写入的时候是写到主分片,副本分片会复制主分片的数据,读取的时候主分片和副本分片都可以读。如果某个节点挂了,前面所提高的Master Node就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据就不会丢。
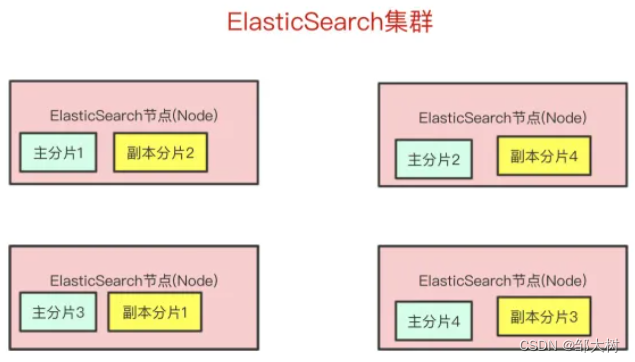
集群上的每个节点都是coordinating node(协调节点),协调节点表明这个节点可以做路由。比如节点1接收到了请求,但发现这个请求的数据应该是由节点2处理(因为主分片在节点2上),所以会把请求转发到节点2上。(通过hash算法计算)
[
索引是什么:索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。索引是针对表而建立的,它是由数据页面以外的索引页面组成的,每个索引页面中的行都会含有逻辑指针,以便加速检索物理数据。
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
]
参考资料:ElasticSearch在项目中具体怎么用? - Java3y的回答 - 知乎 https://www.zhihu.com/question/469207536/answer/2290001606

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











