






学习计算机视觉,深度学习快一年了,第一次写博客,想记录自己学习的过程,深度学习作目标检测的模型已经有很多,包括RCNN, Fast RCNN, YOLO, SSD等,本次实验室利用Fast RCNN做目标检测,数据集是采集的大疆四旋翼无人机,后面会继续对其他模型进行训练,先给出实验检测的效果。


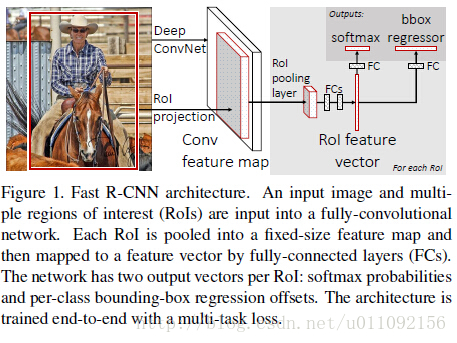
一. Fast RCNN模型特点
- 去除了R-CNN中冗余的特征提取,将整张图像输入神经网络进行一次特征提取:用ROI pooling层取代最后一个max pooling层,同时引入bbox 回归层,提取相应的建议proposal特征。
- Fast RCNN网络末尾采用的是并行的两个连接层,cls score层和bbox score层,可同时输出分类结果和回归结果,第一次实现了end -to -end的多任务训练。
- 下面给出Fast RCNN的网络结构
二. Fast RCNN模型下载 - 从GitHub上下载fast_rcnn的python代码,https://github.com/rbgirshick/fast-rcnn
- 由于我是在自己笔记本上(windows下)跑的,因此需要首先利用vs生成pycaffe库,windows版本的caffe没有编译roi pooling layer库,需要在libcaffe.vcxproj中手动添加。
- 生成cython_bbox.pyd和cython_nms.pyd库
用文本编辑器打开 fast_rcnn_root/lib/utils/nms.pyx,将第25行的np.int_t修改为np.intp_t
用文本编辑器打开 fast_rcnn_root/lib/setup.py,将第18行和第23行的 “-Wno-cpp”,’’-Wno-unused-function’'指令删除,只留下空的中括号[ ]即可。
打开cmd,定位至fast_rcnn_root_lib,执行python setup.py install
如果提示Unable to find vcvarsall.bat 的话,执行下列指令:
SET VS90COMNTOOLS=%VS110COMNTOOLS%
setup.py安装完成后,到python_root/Lib/site-package/utils中可以找到两个文件
cython_bbox.pyd和cython_nms.pyd,把这两个文件复制到fast_rcnn_root/lib/utils中 - 要是想运行fast_rcnn自带的model,需要下载相应的训练好的caffemodel,具体方法参见文件夹中的README.md或其他人的博客。
三. 准备训练数据
1.我的训练数据文件夹如下图所示
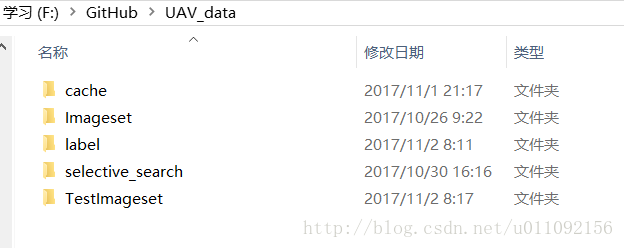
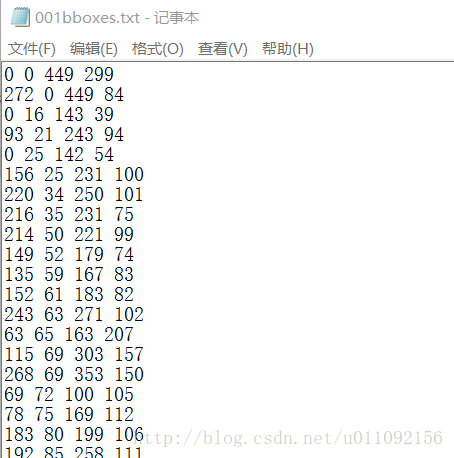
其中label/label.txt里面为Imageset中对应的图片信息,包括roi的bbox位置以及图片名字和所属类别(bird,UAV,plane)三类,每个bbox对应一行,如果一个训练图片中有多个roi,那么此处就有多行,如第5、6行所示

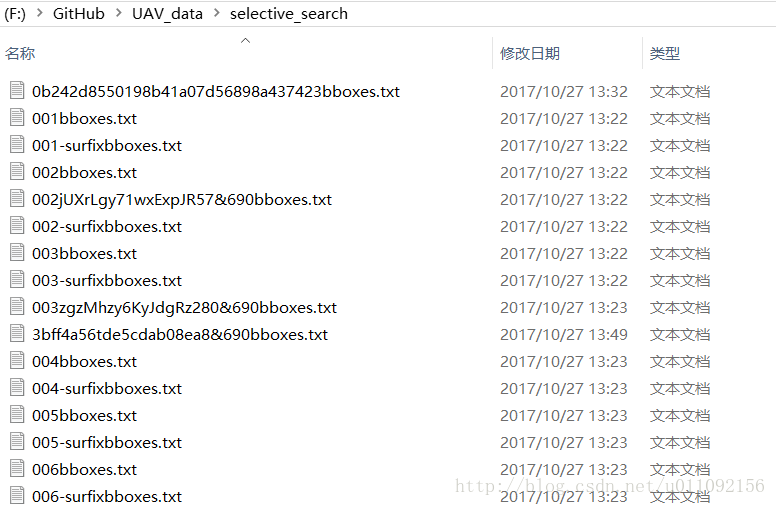
2.selective search为每张训练图片提取建议框,我是用c++写的,提取出来的每张图片的bboxes 直接写入了txt文本框中,首先给出bboxes的格式,分别对应【xmin, ymin, xmax, ymax】
3.然后给出利用label.txt读取图片信息,生成bboxes的代码:
vector<string> read_imagepath(string label_path, string image_rootpath){
vector<string> filepath_array;
ifstream fin(label_path.c_str());
string line;
getline(fin, line);
string previous_line;
while (getline(fin, line)){
string filepath = image_rootpath;
int end = line.find_last_of(' ');
int begin = line.substr(0, end - 1).find_last_of(' ');
string current_line = line.substr(begin + 1, end - begin);
if (current_line != previous_line){
filepath.append(current_line);
filepath_array.push_back(filepath);
}
previous_line = current_line;
}
fin.close(); //关闭文件
return filepath_array;
}
float sigma = 0.8; //高斯滤波
float k = 100; //控制合并后的区域大小
int min_size = 40; //用于后处理参数,当区域内像素个数小于min_size时,选择与其差异最小的C合并
string filepath = "F:\\GitHub\\UAV_data\\label\\label4.txt";
string imagepath = "F:\\GitHub\\UAV_data\\Imageset\\";
vector<string> filepath_array = read_imagepath(filepath, imagepath);
for (int i = 0; i < filepath_array.size(); i++){
int end = filepath_array[i].find(".");
int begin = filepath_array[i].find_last_of("\\");
string boundingboxname = filepath_array[i].substr(begin + 1, end - begin - 1);
string bboxesname = string("BoundingBoxes\\") + boundingboxname+string("bboxes.txt");
Mat img = imread(filepath_array[i]);
image<rgb>* imginput = matToImage(img); //将矩阵转成image类
int region_nums;
//得到选择搜索区域的包围框的边界信息,左上和右下顶点xy值
int* BB = generate_bounding_boxes(imginput, sigma, k, min_size, ®ion_nums);
FILE* f;
f = fopen(bboxesname.c_str(), "w");
for (int i = 0; i < region_nums; i++){
fprintf(f, "%d %d %d %d \n", BB[4 * i + 0], BB[4 * i + 1], BB[4 * i + 2], BB[4 * i + 3]);
}
fclose(f);
4.通过ss的提取,生成了每张图片的建议框信息,放在selective_search文件夹中
数据分享链接链接:https://pan.baidu.com/s/1AIRjXBuC-S7FAhnhJLJuQA
提取码:bovx


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









