









线性回归:
优点:结果易于理解,计算上不复杂
缺点:对非线性的数据拟合不好
适用数据类型:数值型和标称型
设X为数据集,xi为每一行所包含的特征的值,yi为每一行xi的结果,如图:
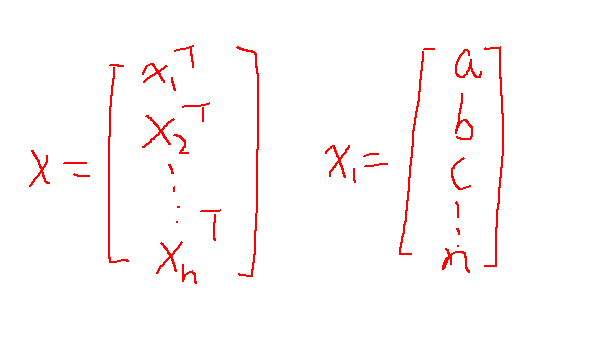
其中xiT表示为xi的转置,abc。。。n表示xi所包含的特征值。
设Yi表示用回归系数的向量wi预测出来的y值,如图:
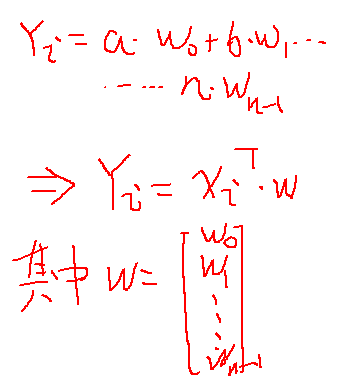
有大量的训练集X,也会出现大量的回归系数W,但我们只取一个最好的w,也就是与真实值得误差最小的一个,
于是我们可以累计一个系数w预测的所有值与真实值的差的平方,也即平方误差(抵消正差值与负差值)。
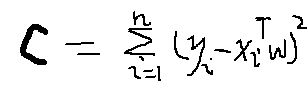
但是怎么取出误差最小的一个呢?利用求导的知识就可以。
在吴恩达老师的视频里下面式子的解释直接就跳过了,结合《机器学习实战》里的解释,我又推导了下,
大致应该是这样的。如果有错,欢迎指正。
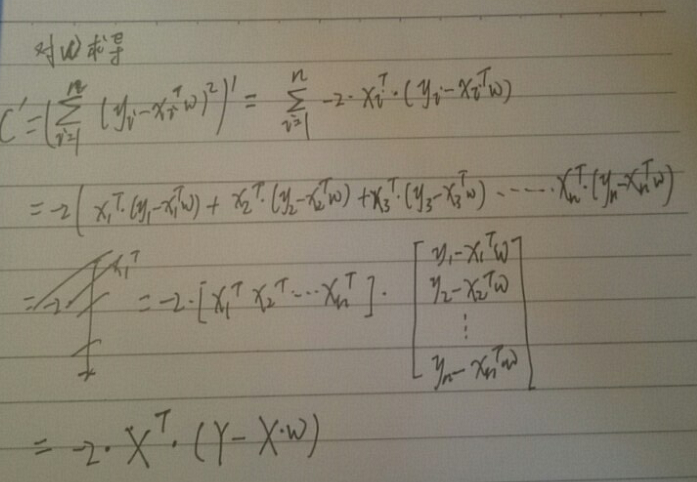
于是令最后的结果等于0,可以的得到最优w的估计值:
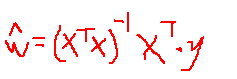
于是便可以利用这个回归系数w画出回归曲线。
使用python3.6实现标准回归函数:
def standRegres(xArr,yArr):
xMat = np.mat(xArr); yMat = np.mat(yArr).T
xTx = xMat.T*xMat
if np.linalg.det(xTx) == 0.0:
print("This matrix is singular, cannot do inverse")
return
ws = xTx.I*(xMat.T*yMat)
return ws高斯核,加权线性回归。。下次再看。。再更新















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









