







 这篇博客介绍了吴恩达的深度学习课程中的神经网络基础和梯度下降法。讨论了二分类问题、特征与标签、logistic回归、sigmoid函数、损失函数、梯度下降优化以及向量化的重要性。通过一个简单的例子展示了如何计算导数和更新参数,同时强调了在实际应用中向量化能有效提升计算效率。
这篇博客介绍了吴恩达的深度学习课程中的神经网络基础和梯度下降法。讨论了二分类问题、特征与标签、logistic回归、sigmoid函数、损失函数、梯度下降优化以及向量化的重要性。通过一个简单的例子展示了如何计算导数和更新参数,同时强调了在实际应用中向量化能有效提升计算效率。
01.神经网络和深度学习
第二周 神经网络基础
先说明最简单的二分类,即可以把结果分为0和1两类,或者说是否两种的分类情况。
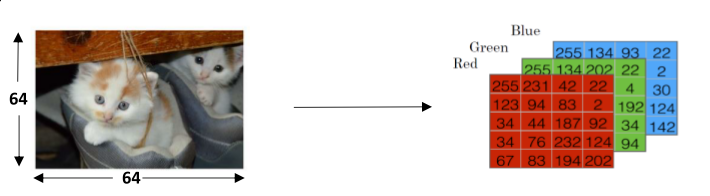
比如说判定图片中是否有猫,标记为有(1)或者无(0)。
特征则是图片中像素点RGB三色的深度,对应于64x64像素的图像,特征量为64x64x3= 12288。
为了操作解释方便,我们会把特征进行排列,重组成纵列。
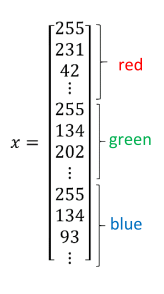
一个特征对应一个标签,最后组成数据对(x,y)
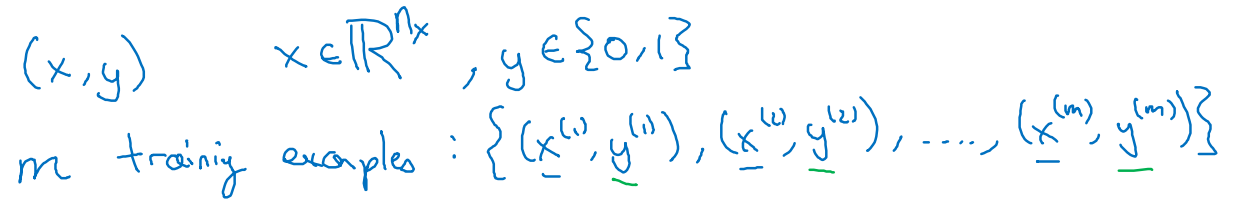
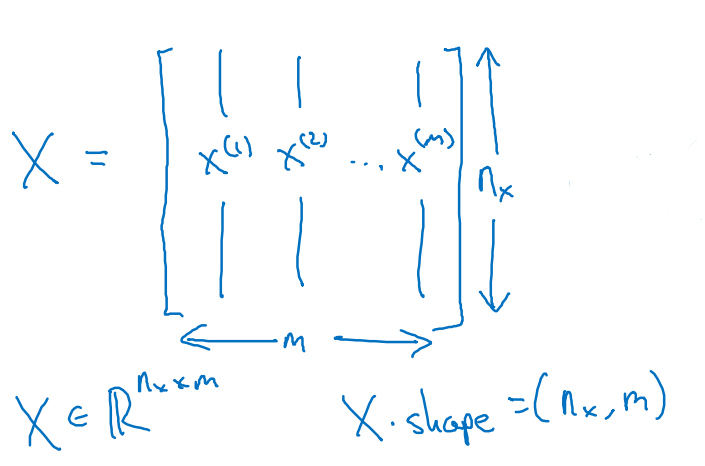
m个数据组合后把特征和标签组合成X和Y
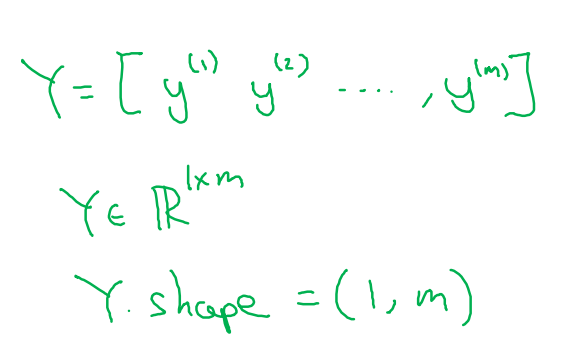
logistic regression,监督学习的一种,输出为0或者1.
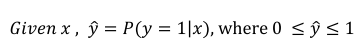
在已知x的情况下,求y的概论,其中x为上面说明的特征,y为标签。
我们这里定义为一般公式,引入参数w和b
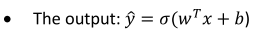
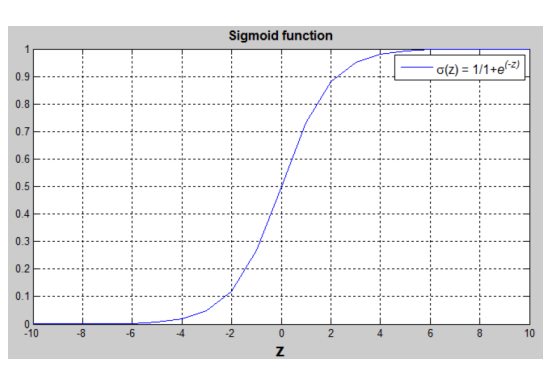
单纯的w*x+b类似于一元线性方程,无法得到一个[0,1]范围内的数值,还需要用到sigmoid function(这点在后面会优化,因为sigmoid中间有一段缓慢变化区,不利于函数收敛)
为了训练参数w和b,我们需要定义一个cost function来判断怎样的参数才是合适的。
cost function是在当前训练集下的,而loss(error) function是指针对某个样本的。cost function 是loss function的平均。
对loss function,我们希望我们计算出来的y^与真实的y无限接近。
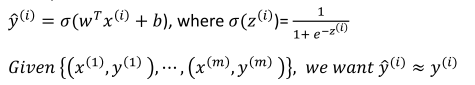
xi是指某个特定的样本,其会对于到不同的y。
在基本概念中,如果我们要两个量接近,会让两者之差为0.
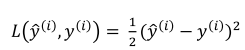
但上式这种形式中利用梯度下降法时会产生多个局部最优解,无法得到全局最优解。
y^ 可以理解为在给定训练样本x的情况下y等于1的概率,这样可以得到下列公式
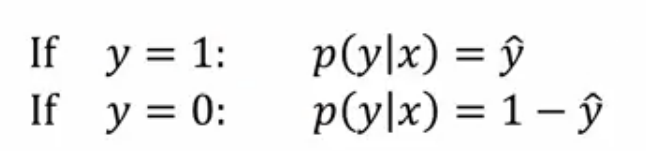
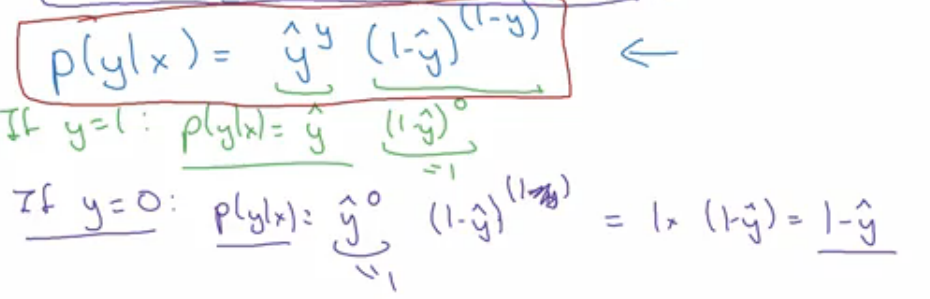
P(y|x)就是我们希望求解出结果的概率,越大越好。log为单调函数,在公式两边加上log后
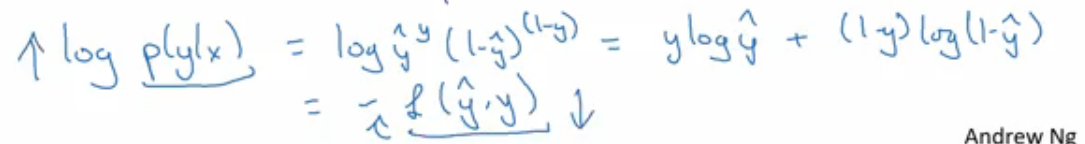
可以看到loss function的雏形,P越大,L就要越小。
在logistic regression中使用的loss function是
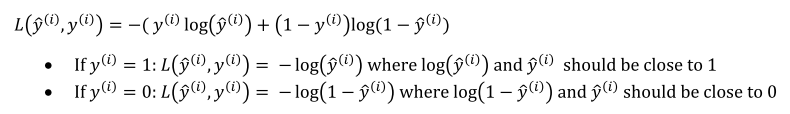
其中L越小越好,log是单调函数,故实现了y== 1时y^也需要趋近于1(最大即为1)
y==0时,y^也需要趋近于0(最小即为0),使得1-y^更可能大。
cost function 是不同训练样本下loss function的集合,在无特殊偏重的情况下(样本特征平均分布,无离散点)求平均即可
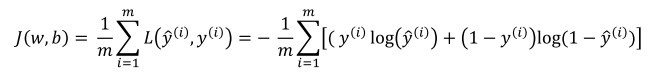
从概率的角度出发,可以这样理解
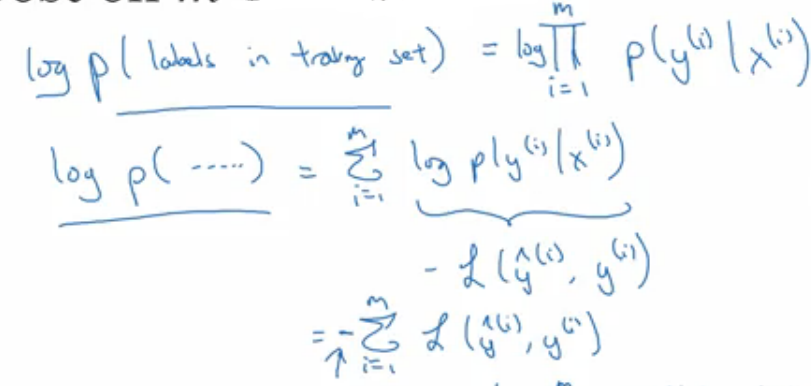
相互独立事件的和概率等于各概率的乘积,加上log后变化为求和。
有了J(w,b)后我们就可以拿来评估得到的参数w,b效果如何,下面就进入到梯度下降法,如何利用J来逐步迭代实现(w,b)的变化
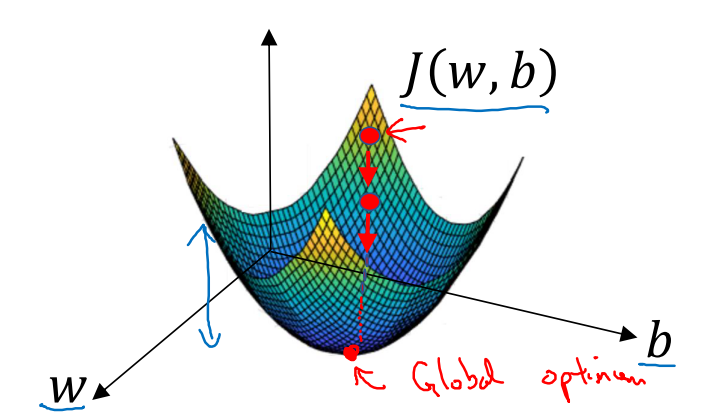
学习过程中,参数变化:
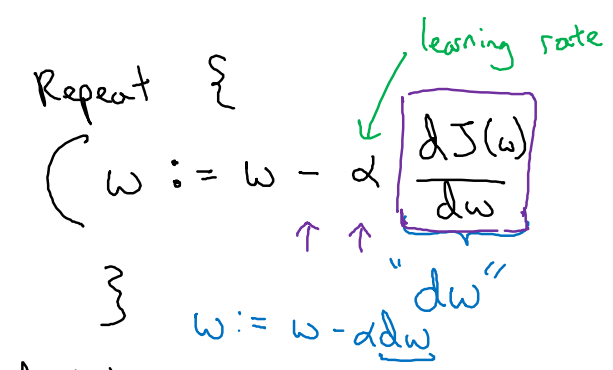
dw是J对w的导数,α是学习速率,代表收敛速度。越大收敛越快,但也越容易收敛困难。
在梯度下降的过程中,就是按照dw来逐步更新w.
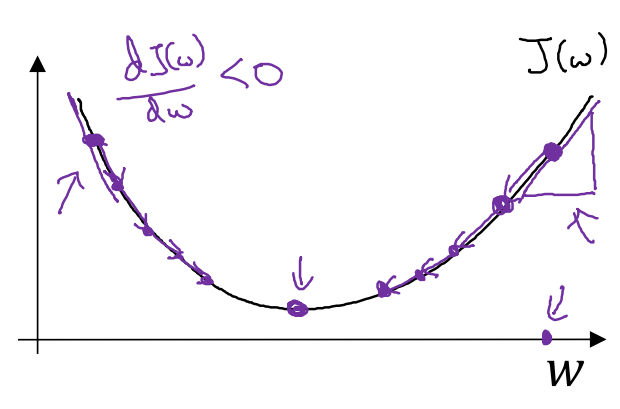
阿尔法是大于0,如果w在最优解右边,dw为正数,按照公式,w减少。
当w在最优解左边,dw为负数,按照公式,w增加。
越接近最优解,dw绝对值越小,变化越小。梯度下降法就是按照J的梯度来调整参数。
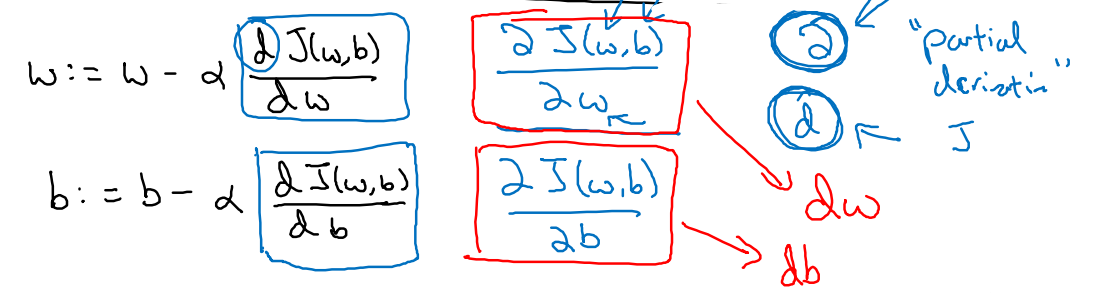
w,b两个参数都是按照此方法进行调整。dw,db可以理解为导数,用函数理解就是在特定点上的曲线斜率,再专业一些可以叫偏微分。
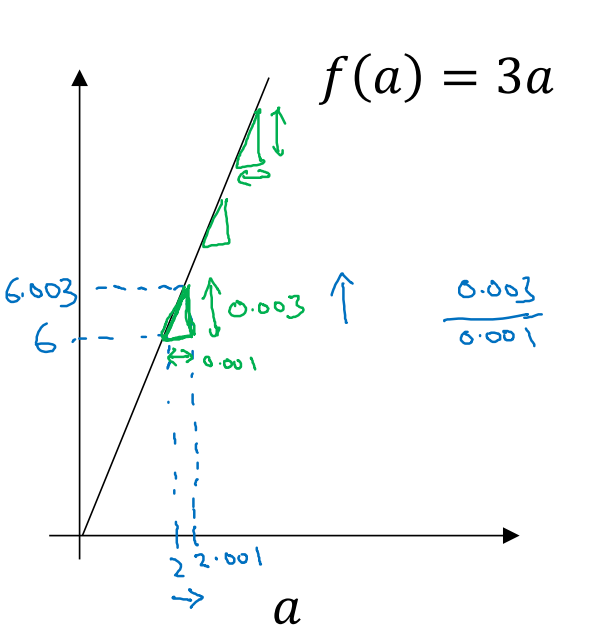
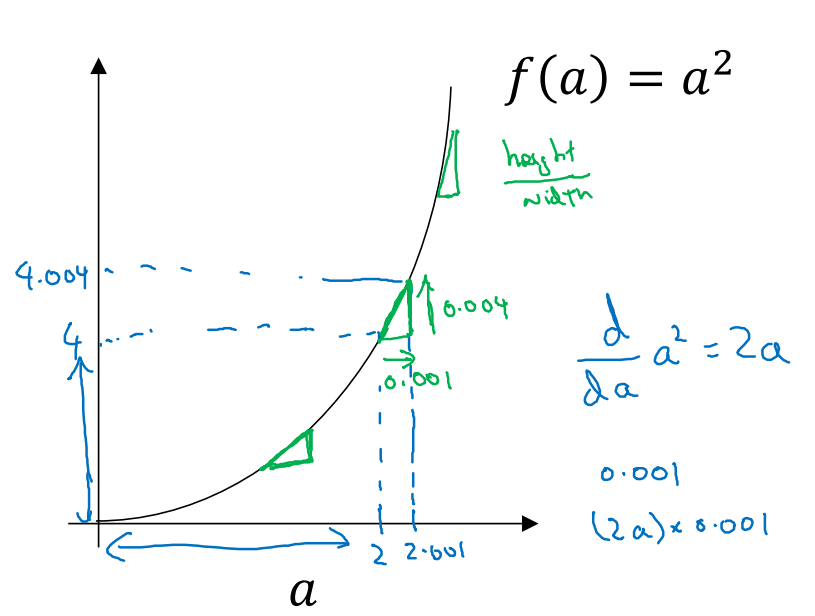
Computation Graph是神经网络计算中步骤说明(我的个人理解),先通过预设的w,b公式,用训练集计算出当前(w,b)下的输出值,再计算当前的dw,db,代入更新w,b。重复这种前向传播和反向传播的运算。
用个简单的公式J(a,b,c) = 3(a+bc)来说明,用公式细分为三部分:u = bc, v = a + u , J = 3v
在计算导数时把导数逆向一层层传递下去的,也是computation graph的核心思想。
dJ/da = dJ/dv*dv/da , dJ/db = dJ/dv*dv/du*du/db, dJ/db = dJ/dv*dv/du*du/dc
在logistic regression上利用梯度下降法,下面事例只用2维特征说明,
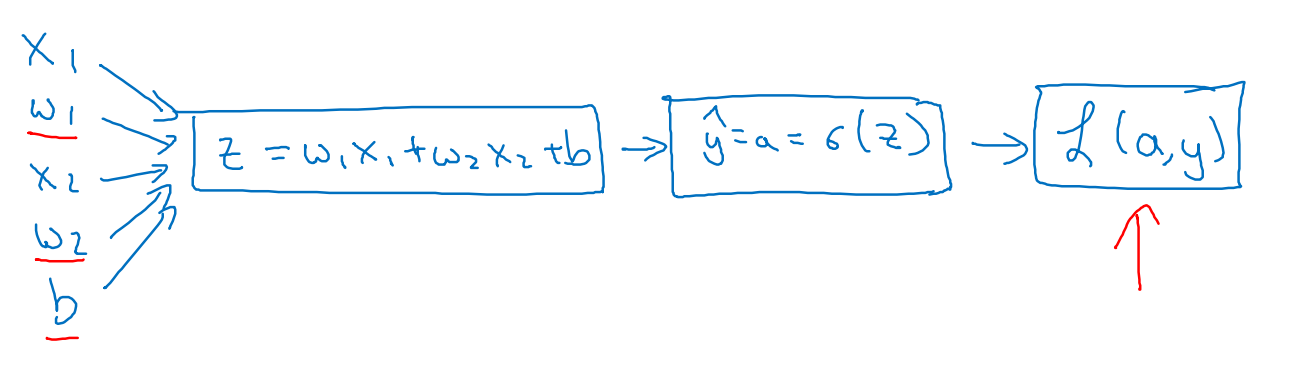
回忆公式
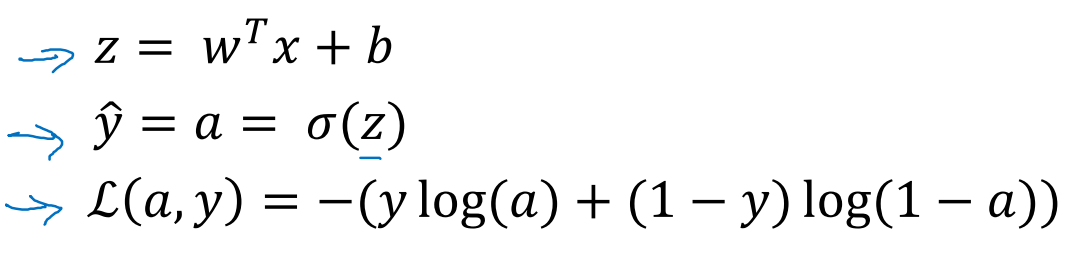
求解每一步的导数
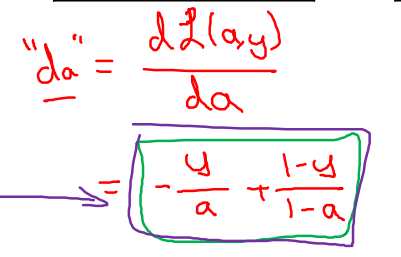
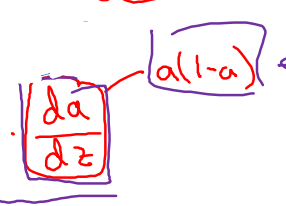
dL/dz = dL/da*da/dz = a-y
dz/dw1 = x1, dz/dw2 = x2, dz/db = 1

上式利用到了训练集的特征{x1,x2...},所以在一个多训练样本m的情况下,
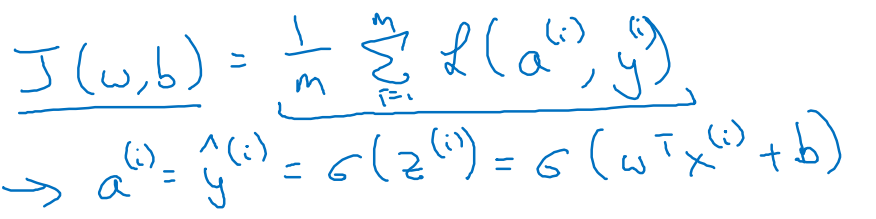
dw1也不仅是dLi/dw1,而是下式这种平均形式
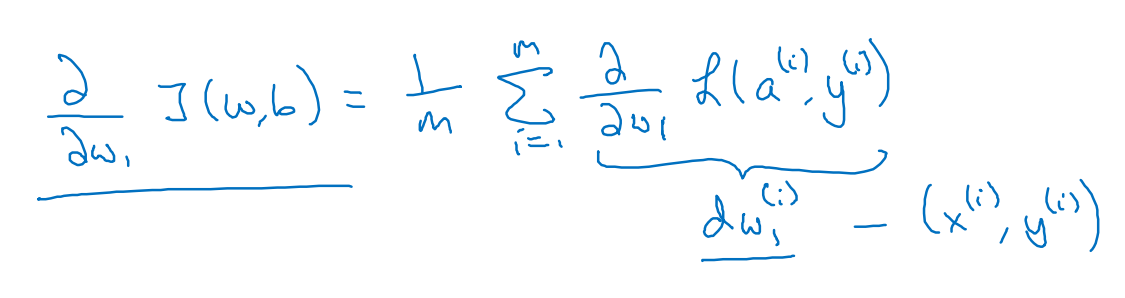
也就是把所有{xi,yi}对应的dw1求解出来后再进行平均。用伪代码表示为
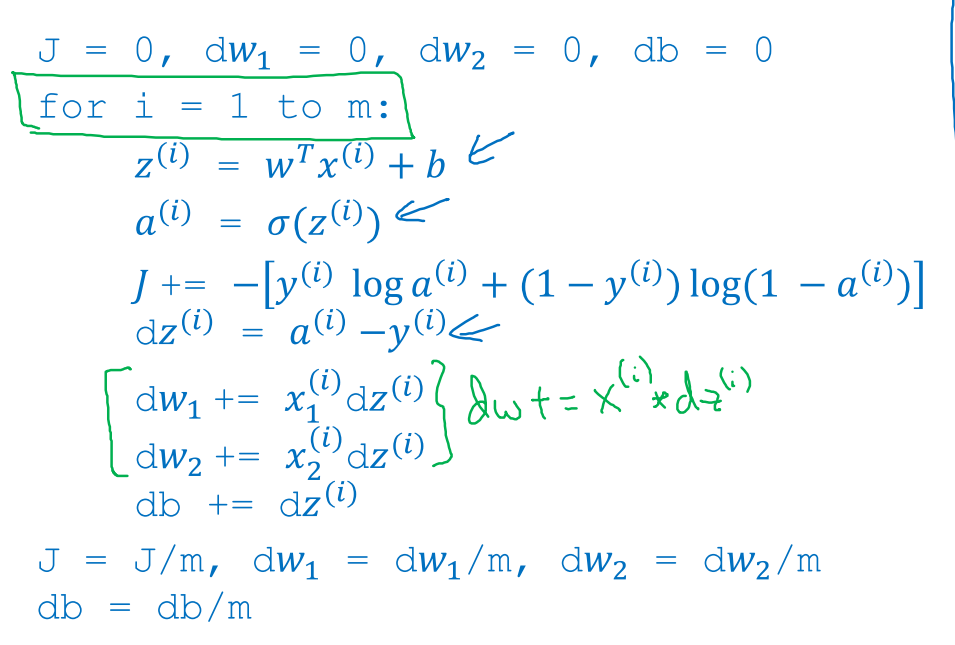
有两个循环,外层循环是循环不同的训练样本1 to m,里面循环是循环不同的模型参数1 to n+1,n对应特征维度。
两层循环结束后再除以m平均。
Vectorization,向量化,是机器学习中重要的一环,也就是减少显式的for循环,以此减少运算时间。
这有些像MATLAB中是把数据定义为矩阵,矩阵的加减乘除有特殊的内置函数处理,不需要我们自己写for循环来做基础运算。
教程中是说用python或者numpy的.dot(x,y)来执行向量运算。
再底层就是计算机的并行运算,这部分可以不做深究。
套用在logistic regression里面,正向计算和反向传递都可以向量化,
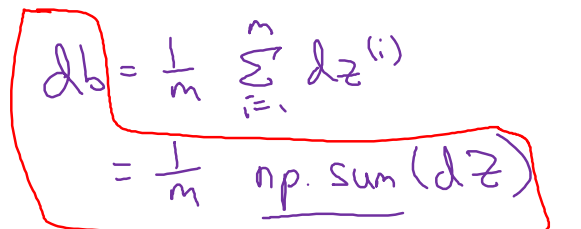
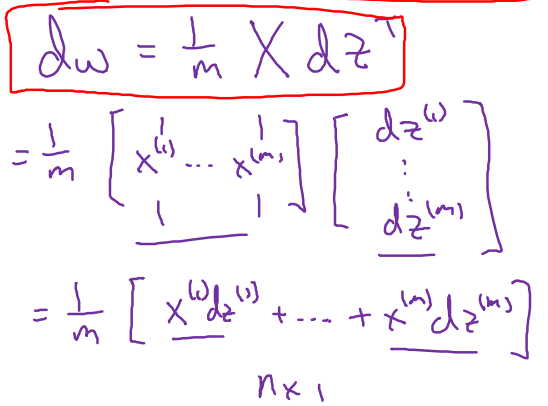
求解过程经过向量化后:
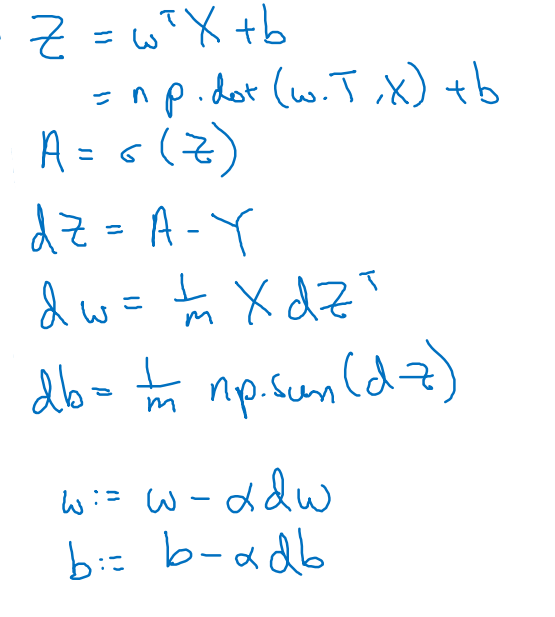
我理解的向量化,就是用向量运算的思路思路来代替单纯的数值运算。这确实很有用,在我以前的代码中经常是大段多嵌套的for循环,算法的执行效率惨不忍睹。
python里面的广播boardcasting等于是向量之间或者向量和数据之间运算时,会按照最大的维度进行扩展,然后再执行逐个元素的运算,比较像MATLAB里面的.*/.+这类操作。
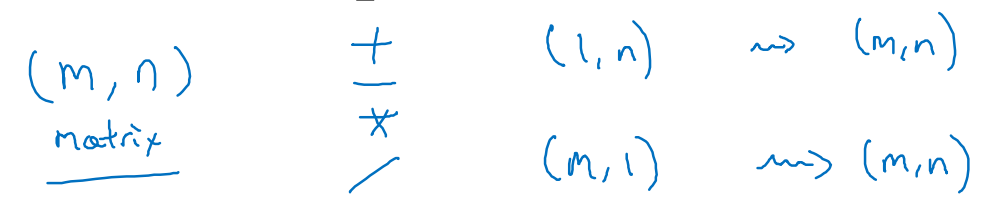
在函数运算前进行reshape()是一种保证,保证其行列数量是按照我们期望的进行排列
另外还需要注意生成向量时的操作,不用生成为rank 1 array,这既不是行向量,也不是列向量。
错误做法:
仅管可以通过reshape改变过来,但也不推荐使用。
正确的做法是生成时表明行列2个数值。

必要时也可以加上如下语句进行保证确认















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









