







============条件关键的使用===
on是用于链接查询。
where用于一般性的查询;from后面都可以用;如果from是在连接查询语句后面,则是对连接查询的结果做条件判断;
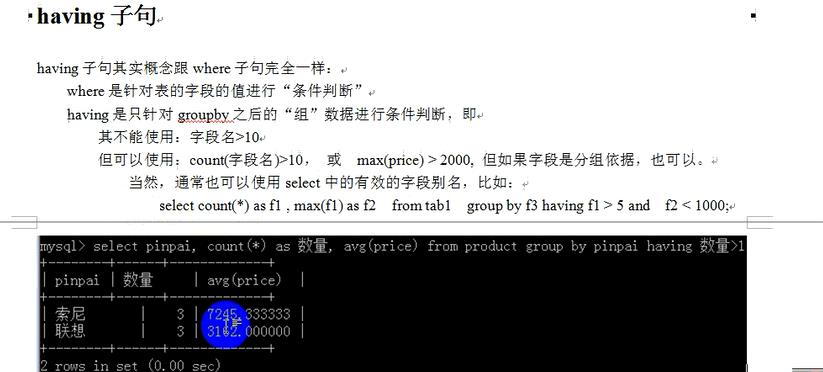
having用于group by 后面限定条件;
复制表---------------第二种方法可能会丢失一些数据
-

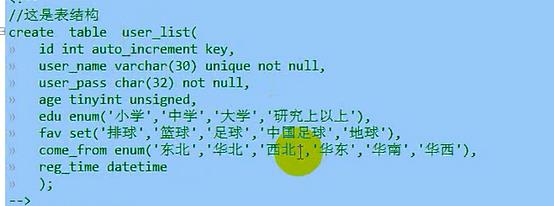
auto_increment必须作用在有索引的字段上;
====================数据库操作-----------DML--------
插入-----------------

insert into 表名1(字段名1,字段名2,。。。。。) values(值a1,值a2........), (值b1,值b2,.....),..............;
inset into 表名1(字段名1,字段名2,。。。。。) select 字段名1,字段名2,。。。。from 表名2;
insert into 表名1 set 字段名1=值1,字段名2=值2,。。。。;
inset into 表名1 select * from 表名2 where语句 ;------表1的字段如果是表2的所有字段,则表1的字段可以省略;


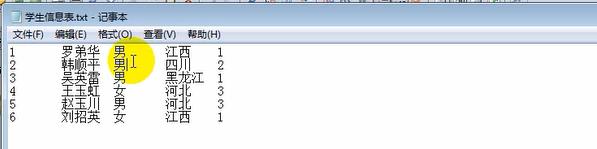


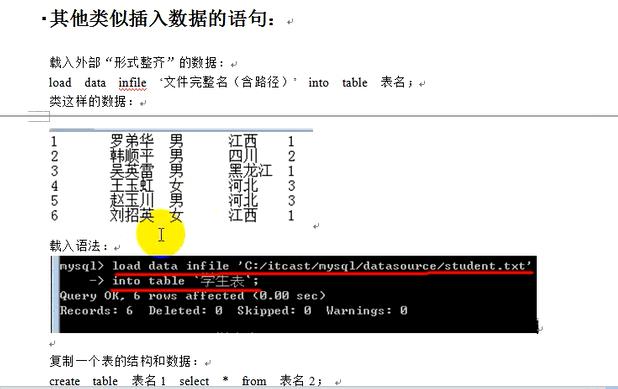
吧txt'中的数据(形式整齐的数据)载入到数据库中,如果表名是汉字要用单引号引起来,但是汉字可能出错,最好不用汉字,注意字符编码问题,注意BOM;---------
load data infile 'TXT文件的路径' into table 表名;
-----------------------------删除表-----------------------
drop table if exists 表名;
-----------------------------删除数据-----------------------------------------

delete from表名 [where 条件] [order 排序][limit 限定];
delete from 表名;------------如果不加where条件,就删除表里的所有数据;
------------------假删除-----------------------------------------


truncate [table]表名;
truncate----会把原始的表结构完全跟初始的一样,全部索引,全部约束,全部属性都跟原始的一样,可以理解为重置该表为初始状态;delete的话,会继续在删除之前的基础上自增长;
----------------------------------修改数据------------------------

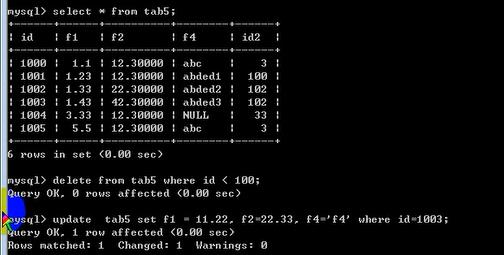
字段的值可以是表达式,或者直接值,或者函数;如果是直接值,字段的值中的数字不加引号,字符串和时间要加引号;
update 表名 set 字段名1=值1,字段名2=值2,。。。[where 条件] [order 排序][limit 限定];
-------------------------------------数据查询--DQL-------------------------------
数据查询包括:基本查询,连接查询,子查询,联合查询;

select [all | distinct ] 字段或者表达式列表 [from 子句][group by 子句][having 子句][order by 字句][limit 子句];
无数据源的select语句:
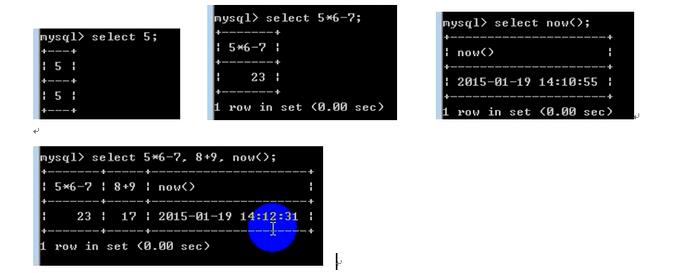
上面的字段在php中没法使用,添加别名后就可以使用 了;


============对字段和直接值(或者函数返回值)同时取出;
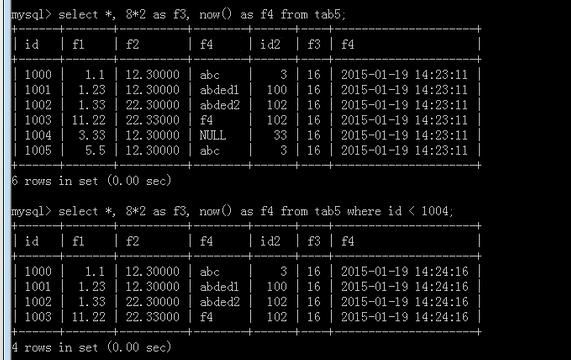
可以用:表名 . 字段名 表示那个表的字段
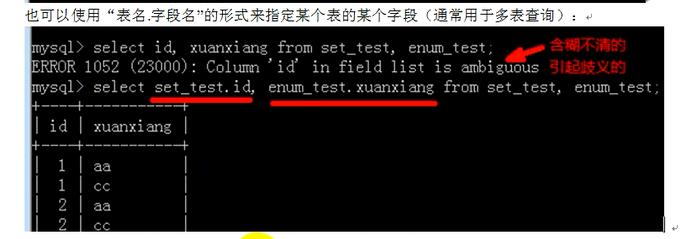
===============基本查询===================
基本查询中:from,where,group,having,order,limit;这些都是在他前一步的结果基础上再设定条件。


=============是否允许出现重复行(完全相同的数据行)=============

===================from子句=====================

======================where子句===========================

where和from可以省略,但是如果有where,必须有from,如果有from,可以没有where;

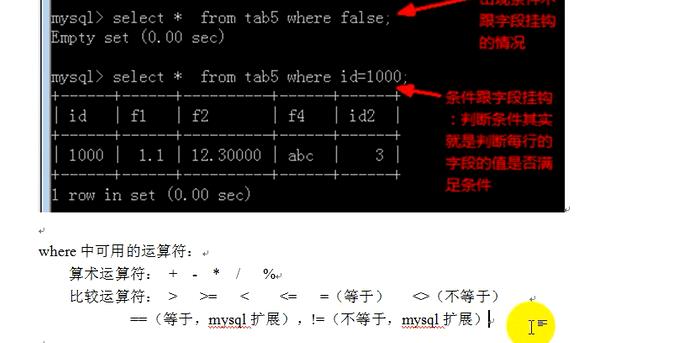
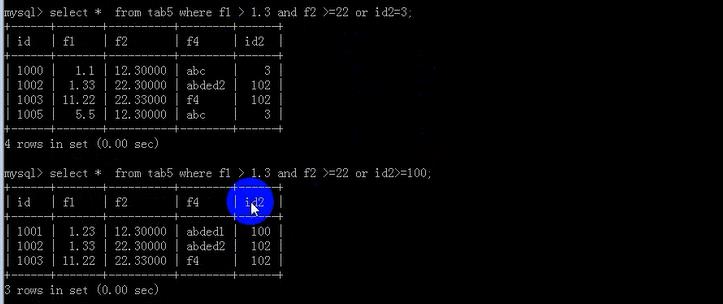
逻辑运算符:and ( 与) or(或) not (非)


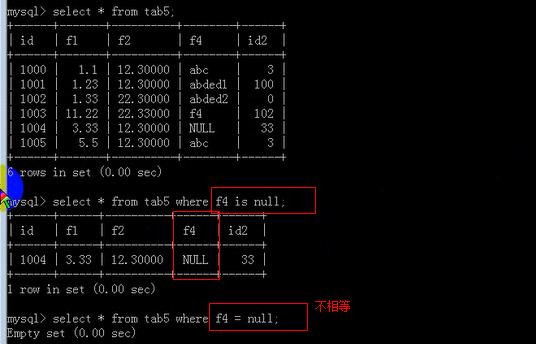
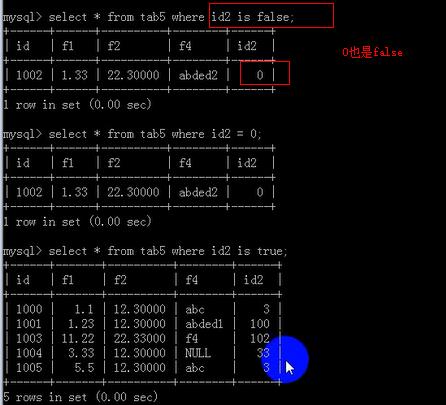
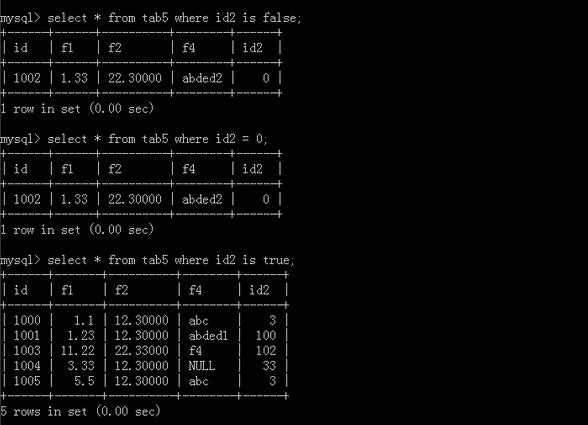
空值需要用is运算符,等号是不行的;

值可以是直接值,也可以是select语句;

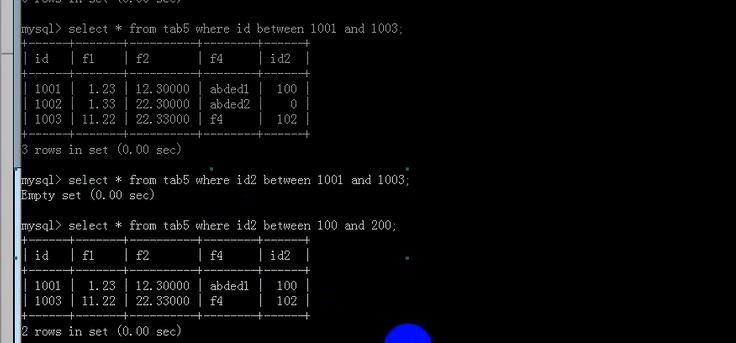
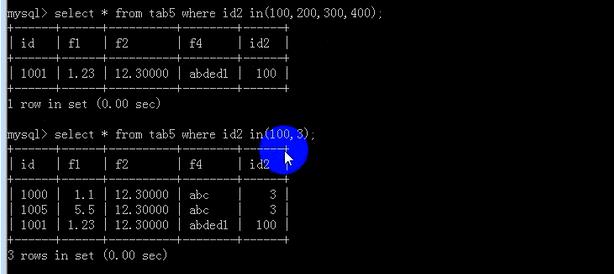
id2 in(100,200,300,400)表示id2是100或者,200或者,300或者,400时为真;

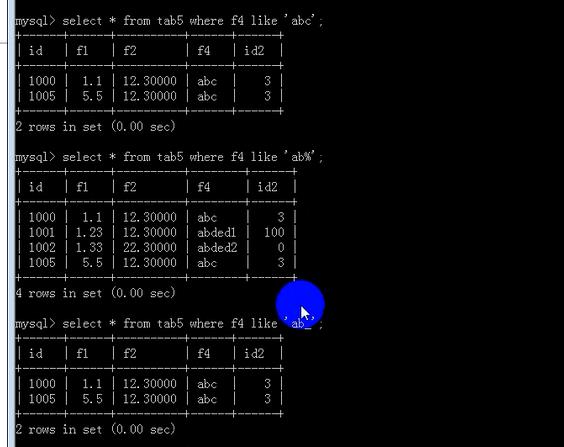


=======================groupby========================
group by 字段1 排序方式 1 ,字段2 排序方式2,。。。。。;

组内成员个数,最大值,最小值,平均值,总和值,以及分组的依据字段;
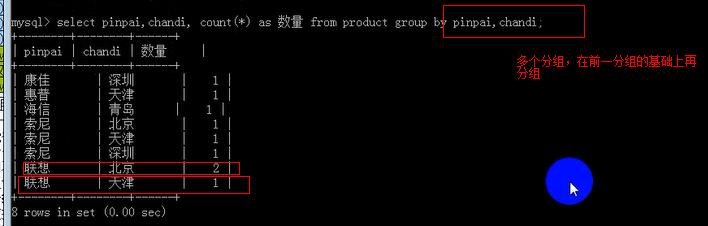
------------如果是对两个字段分组,就是先对第一个进行分组,再在组内对第二个字段进行分组;

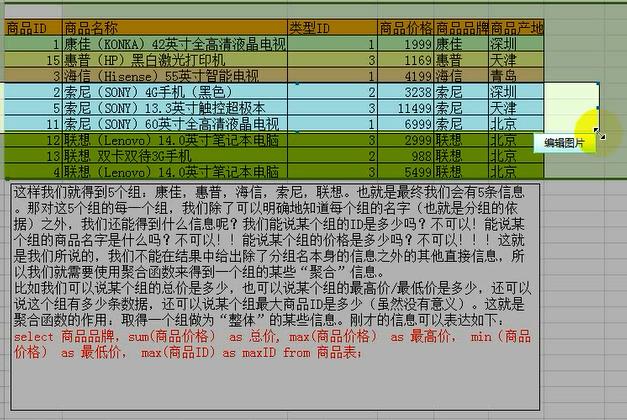
count(*)表示的是每一组的个数。
按照pinpai分组;


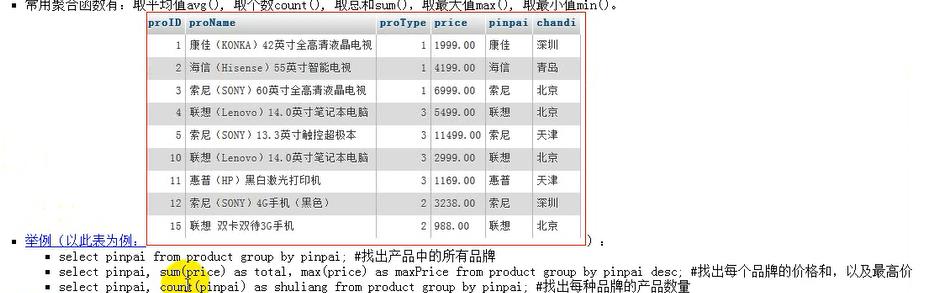
默认是升序:
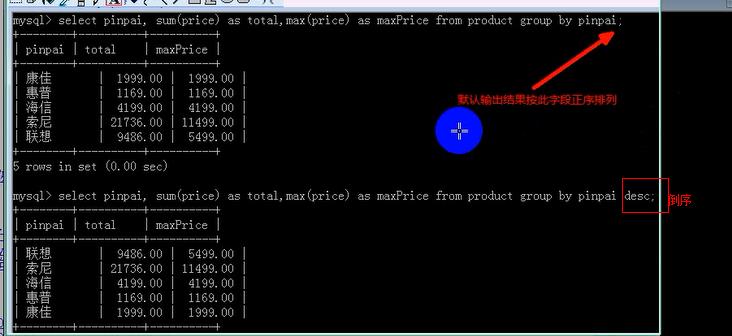
如果是两个或两个字段分组,相当于对前一个分组结果再进行分组;
==========================having字句==========================


======================order by字句======================
order by 排序字段 排序方式;


=================================limit子句=========================

--------------------------连接查询-------------------------------------
交叉连接,内连接,外链接:(左外连接,右外连接,全连接)
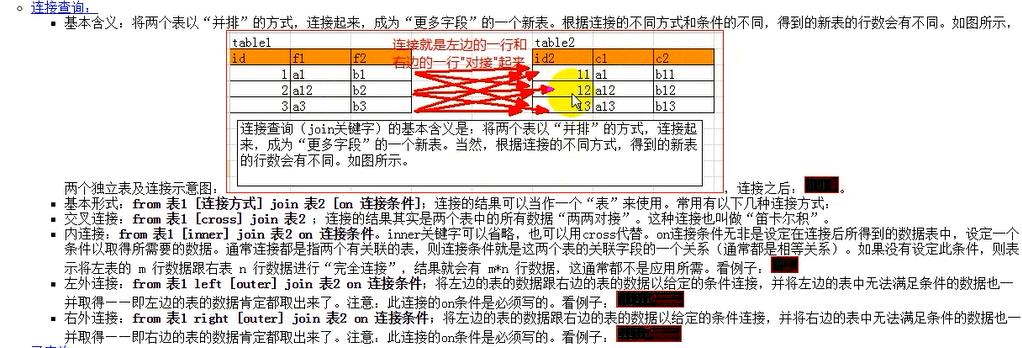
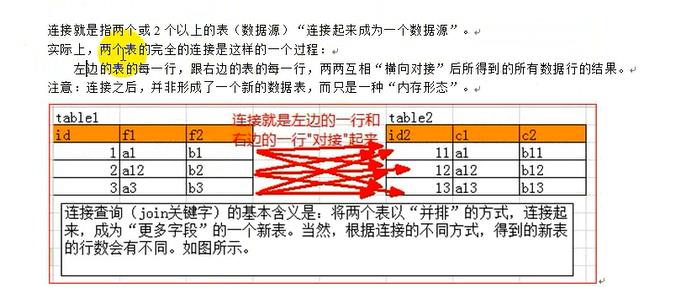
================交叉连接==============

交叉连接:就是不设定任何条件的链接结果,也叫笛卡尔积;
from 表1 [cross] join 表2;---没有on 条件;cross可以省略,也可以用inner代替,
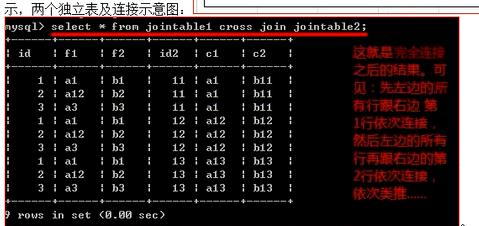
===========内连接===========
from 表1 [inner] join 表2 on 条件;---------------有on 条件;

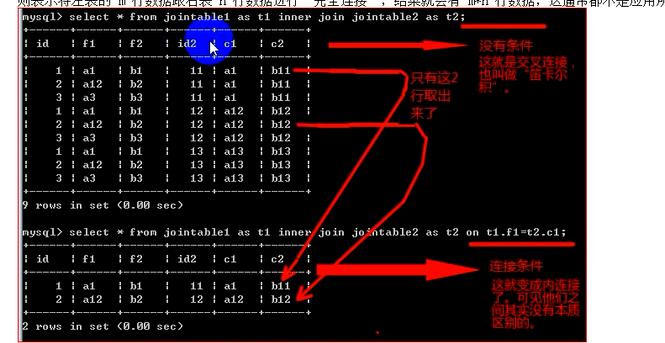
交叉连接通常无意义,内连接是有意义的;
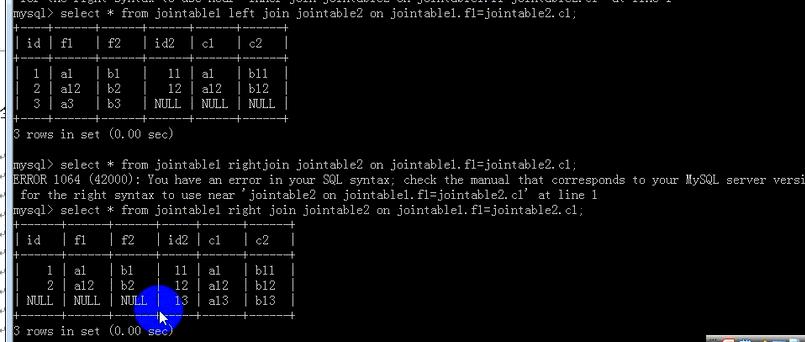
==============左外连接================
from 表1 left [outer] join 表2 on 链接条件;-----------在内链接结果的基础上,加上左边表中不符合链接条件的数据,对应左边不符合链接条件的数据行的右边表的字段的位置自动补为null值;


==============右外连接================
from 表1 right [outer] join 表2 on 链接条件;-----------在内链接结果的基础上,加上右边表中不符合链接条件的数据,对应右边不符合链接条件的数据行的左边表的字段的位置自动补为null值;

==================全外连接==============*mysql本身不支持全外连接。**
from 表1 full [outer] join 表2 on 链接条件;---------在左右链接的合集(消除重复项)-也就是-在内链接结果的基础上,加上左边表中不符合链接条件的数据,对应左边不符合链接条件的数据行的右边表的字段的位置自动补为null值;加上右边表中不符合链接条件的数据,对应右边不符合链接条件的数据行的左边表的字段的位置自动补为null值。

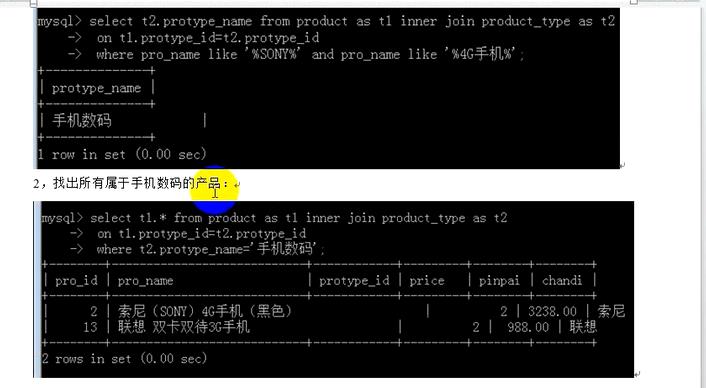
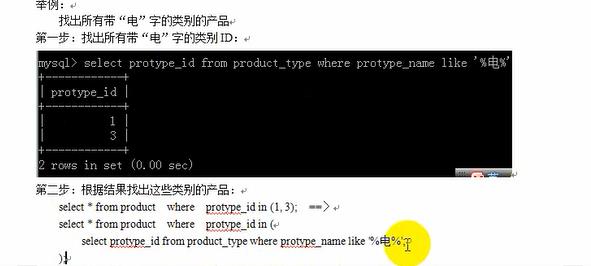
=====================子查询======================




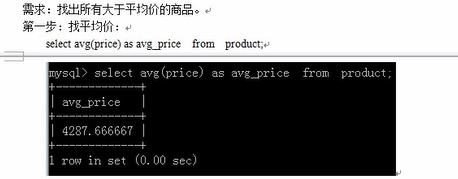

-----------in子查询------------

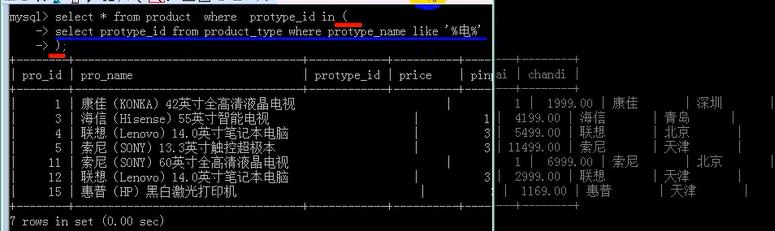
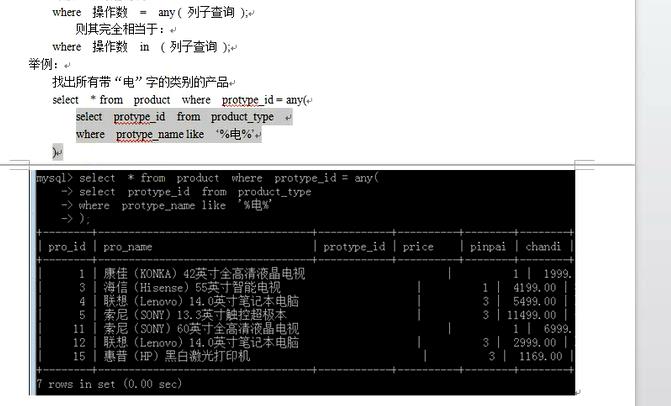
--------------any子查询----------------

= any和in是一个意思;
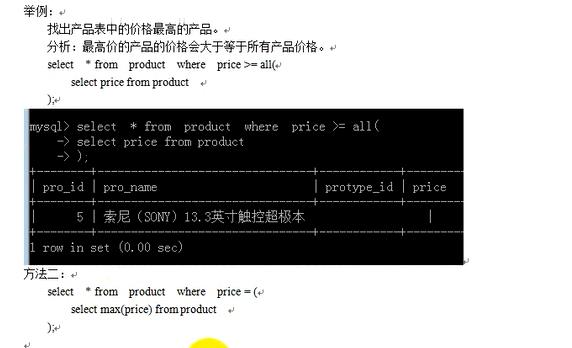
-----------all子查询-------------

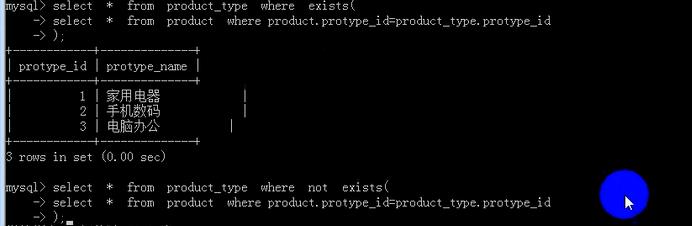
----------some子查询----------exists 或者not exist子查询-------

exist子查询只判断查询的结果,只要数据的行数大于等于1,就是true,并且把exists中的子查询的结果作为上一级查询的结果。否则为false。
--------------------------

exists 或者not exist子查询,如果涉及两个或以上的表,内部会自动进行连接,而且过程还很复杂。不明确。
==============================联合查询================

联合查询的两个查询结果的字段数要相等;


联合查询的两个表的字段数必须相等(类型可以不等,内部会自动转换),查询的结果字段,以第一个表的字段为准,可能会出现两个一模一样的行。但联合查询会默认消除重复的行。要想不消除重复的行,必须写成:select 语句1 union all select语句2;这里的默认项和普通的默认选项相反,要注意。















 2134
2134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









