





近期发现一个对说话人脸视频中嘴型进行编辑生成的论文,该论文不同于基于单张图片进行语音驱动的方法,适合于改变视频中嘴部区域,而其它区域保存不变,适合视频配音等任务。论文中在嘴型对齐方面有较大改善,在视频清晰度方面与MuseTalk方法相当,结合一些后处理方案比如Real-ESRGAN等方法,可以达到很好的视觉清晰度和良好的音频嘴型对齐效果。
项目主页:JoyGen: Audio-Driven 3D Depth-Aware Talking-Face Video Editing
github代码:GitHub - JOY-MM/JoyGen: talking-face video editing
摘要
近年来,尽管说话人脸视频生成技术取得了显著进展,但在音频驱动的唇部动作生成中,精确的音频与嘴型同步以及高质量的视觉效果仍然是亟待解决的关键问题。为此,论文提出了一种新颖的两阶段框架——JoyGen,用于生成高质量的说话人脸视频。该框架包括音频驱动的唇部动作生成和视觉外观合成两个主要步骤。
在第一阶段,JoyGen 利用3D重建模型和音频驱动的动作生成模型,分别预测基于3D可变形模型(3DMM)的身份系数和表情系数。第二阶段,通过结合音频特征与面部深度图,我们为面部生成过程提供了全面的音频嘴型同步监督信号,以增强音频与视觉信息的匹配。
此外,论文还构建了一个包含130小时高质量中文说话人脸视频的数据集,用于支持模型训练。JoyGen 在公开的HDTF数据集和精心整理的自有数据集上进行了训练,实验结果表明,该方法在音频嘴型同步和视觉质量方面均取得了优异的表现。
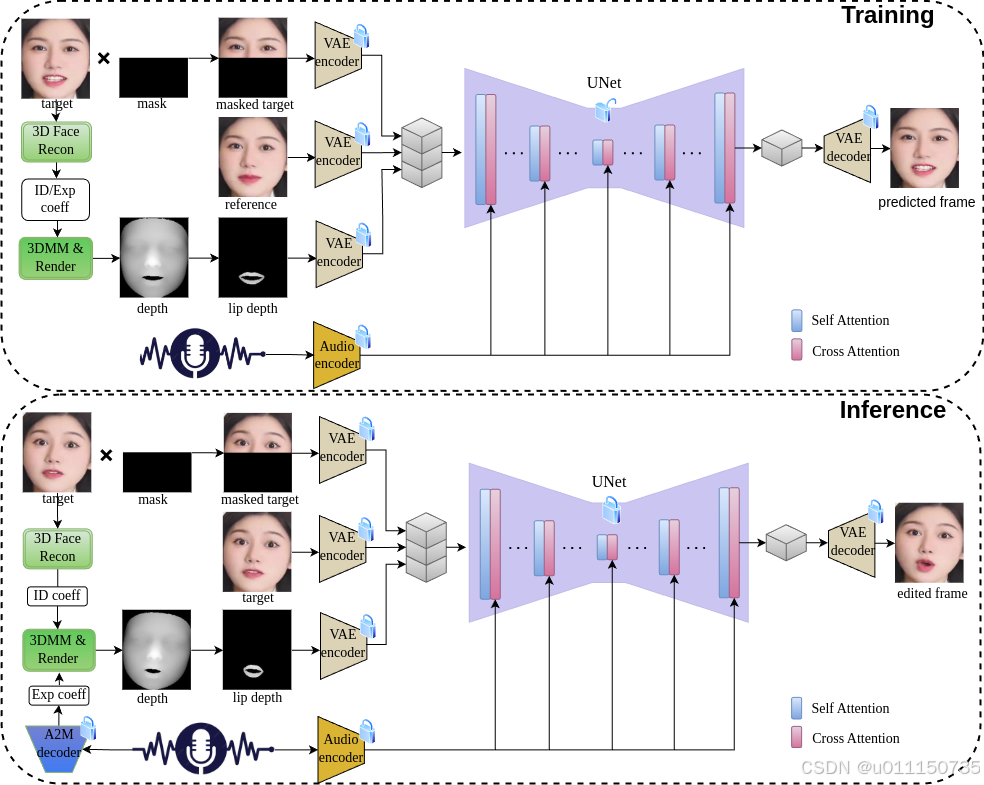
图 1
方法
整体流程图如图1所示,其中上半部分为训练过程的工作流程,下半部分为推理过程的工作流程。
三维可变形人脸模型
V.Blanz与T.Vetter在2003年提出了三维可变形模型简称3DMM,并用PCA表示三维人脸结构,公式如下:
其中表示3D人脸的平均形状,
分别表示三维人脸的身份正交基和表情正交基。系数
分别表示控制三维人脸的身份系数和表情系数。
音频到嘴型运动映射
论文采用了一种流增强变分自编码器,该方法能够高效且准确地学习音频到面部动作的映射关系。由于3D可变形模型(3DMM)中的面部网格是由身份系数和表情系数决定的,因此在重建同一人物的3D面部网格时,其身份系数保持不变,故而3D面部网格的重建过程仅依赖于表情系数。
面部深度图
单张人脸图像的身份系数和表情系数可以通过3DMM拟合方法获得,也可以通过神经网络直接预测。论文采用了 Deep3DFaceRecon 提出的方法,从单张图像中预测3DMM模型的身份系数和表情系数。在数据预处理阶段,利用预测得到的表情系数和身份系数生成对应的3D面部网格,并通过Nvdiffrast渲染过程得到面部深度图。在推理阶段,使用由Real3DPortrait训练的A2M模型预测的表情系数替代原始表情系数,从而生成相应的面部深度图,具体流程可以参考图1所示的推理阶段工作流程。
编辑说话人脸视频
论文采用了一种与MuseTalk的类似UNet架构。与传统的扩散模型从随机噪声开始生成不同,该论文是基于当前视频帧(其中嘴部区域已被遮挡)进行预测,旨在生成与给定音频对齐的唇部动作。此策略有效简化了传统扩散模型中对整个面部信息进行预测的复杂性。同时,通过引入额外的参考图像作为输入,提供了可靠的面部上下文信息,从而提升了目标面部信息生成的准确性。
基于人类直觉,音频信号与说话者面部动作(特别是头部姿态变化和眨眼)的相关性通常较弱。本研究重点关注音频信号与唇部动作之间的直接关系。为了更准确地建模音频驱动的嘴部区域动态,我们引入了嘴部区域的深度信息,以强化音频信号与嘴部发声运动之间的对齐关系。
在这一阶段,采用单步预测的 UNet 方法,其输入包括被遮挡嘴部区域的目标帧、距离目标T帧帧之外的随机参考帧
、目标帧的唇部区域深度图
以及音频信号
。在使用 VAE 对图像数据进行编码后,生成的特征分别标记为
、
和
,而音频信号则通过 Whisper 编码为
。随后,将三个图像特征沿着 VAE 特征通道维度拼接,构成 UNet 结构的输入。而频特征则是通过交叉注意力机制与图像特征进行交互。
数据集
目前,大多数公开可用的说话人脸数据集主要集中于英语场景。为推动中文场景中的应用,论文构建了一个高清中文说话人脸数据集。为确保数据集的高质量,论文实施了严格的人工筛选和审查流程。视频来源于B站和抖音平台,并已调整到可用的最高分辨率。筛选标准包括:(1) 每个账号仅选择一个视频,以保证数据的多样性;(2) 每个视频中仅包含一个可见人脸;(3) 音频与说话者身份一致;(4) 嘴部区域或牙齿清晰可见;(5) 音频为中文且无显著背景音乐或噪声干扰。最终,数据集包含约1.1k个视频,视频时长从46秒至52分钟不等,总时长约为130小时。并对数据集进行了全面的统计分析,涵盖视频时长、帧率、性别分布及人脸尺寸等特征,如下图所示。
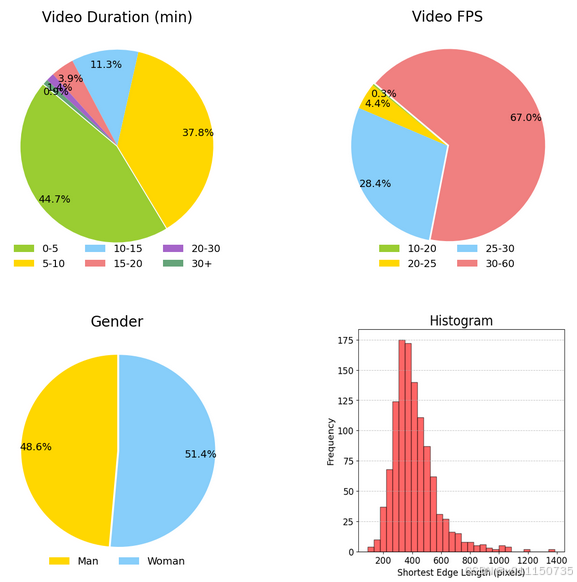
图 2
训练细节
损失函数:由于潜在空间的分辨率相对较低,难以有效捕捉面部细节信息,因此论文在潜在空间和图像空间中均采用L1损失函数进行优化。具体而言,L1损失用于度量真实帧与预测帧的VAE编码特征之间的距离,以及计算两者在归一化图像空间中的L1距离。
深度信息选择:论文采用Deep3DFaceRecon方法,从视频帧中预测身份系数和表情系数。由于只对人脸下半部分进行预测,面部深度图中仅保留嘴部区域的深度信息,其余区域的深度值设置为零。嘴部区域的定义基于Mediapipe提供的80个关键点。在实际应用中,音频驱动的3D人脸网格有时可能会出现嘴部区域与真实面部的不对齐情况。为了在推理过程中改进嘴部深度信息与原始面部图像之间的空间对齐,在训练时对嘴部区域的深度信息引入了随机位移扰动,以减小音频驱动唇部运动生成过程中的对齐误差。此外,将嘴部深度图序列作为强监督信号来增强训练效果。在训练过程中,50%的情况下随机忽略深度信息,从而促使模型更多地依赖音频特征,提升音频信号与嘴部运动之间关系的学习效果。
实验
数据预处理
实验中使用的训练集包括开源的HDTF数据集和整理的数据集。在数据预处理过程中,首先对视频进行分段,仅保留包含单张人脸的片段,剔除无脸或多人脸的部分。随后,使用MTCNN检测器提取五个面部关键点,作为深度3D重建模型的输入,以预测3DMM系数。最后,使用DWPose提取面部边界框,用于裁剪面部区域和对应深度图。对于较长的视频,以每秒25帧的速率提取帧,并随机选择10,000帧,以确保模型的泛化能力。
实验设置
实现细节: 模型从零开始训练,使用8块NVIDIA H800 GPU,耗时一天完成训练。所有输入图像均调整为256x256的分辨率。Batchsize大小设置为128,梯度累计步长为1。优化器采用Adam,学习率为 1e-5。
评价指标:由于缺乏真实的说话人脸视频作为对比,论文使用FID评估生成视频的视觉质量。为了评估唇部运动与音频的同步性,使用Wav2Lip中提出的LSE-C和LSE-D指标。根据Wav2Lip中描述的无配对评估设置,从不同视频中分别选择一个视频片段和一个音频片段进行合成。对于HDTF数据集和收集的数据集,分别生成约500和900对音视频,每对音视频的时长约为10秒。
基线模型:在定量对比实验中,选择了几个开源实现作为比较,包括Wav2Lip和MuseTalk。修改了Wav2Lip中的数据集加载代码,先重新训练唇部同步专家模型,然后训练生成模型。为了获得更好的结果,参考了MuseTalk,重新实现了生成说话人脸视频的训练代码。对上述两个数据集进行了对比实验。
实验结果
定量结果
HDTF数据集上的比较 表1展示了HDTF数据集上的定量评估结果,表明提出的DeepTalkFace方法在所有指标上均优于其他方法。此外,图3中显示了每种方法的LSE-D和LSE-C分数的分布曲线,进一步证明了JoyGen的卓越性能。
在论文收集的数据集上比较 进一步在收集的数据集上评估了所提出的JoyGen方法和其他方法。如表2所示,JoyGen的FID得分最低,为3.19,表明与现有方法相比,在视觉质量上有显著改善。此外,JoyGen方法在唇音同步上表现出色,LSE-D和LSE-C得分与该数据集的真实值非常接近。图4中展示了每种方法的LSE-D和LSE-C分数分布曲线,进一步证明了JoyGen在同步性能方面的优越性。
|
表 1 |
表2 |
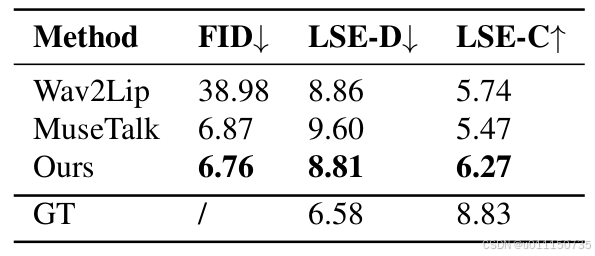
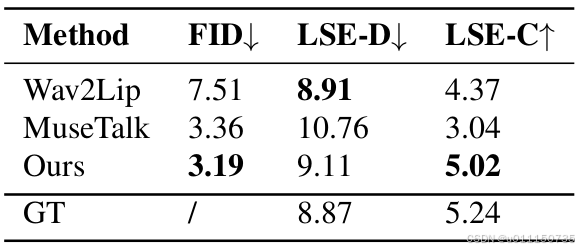
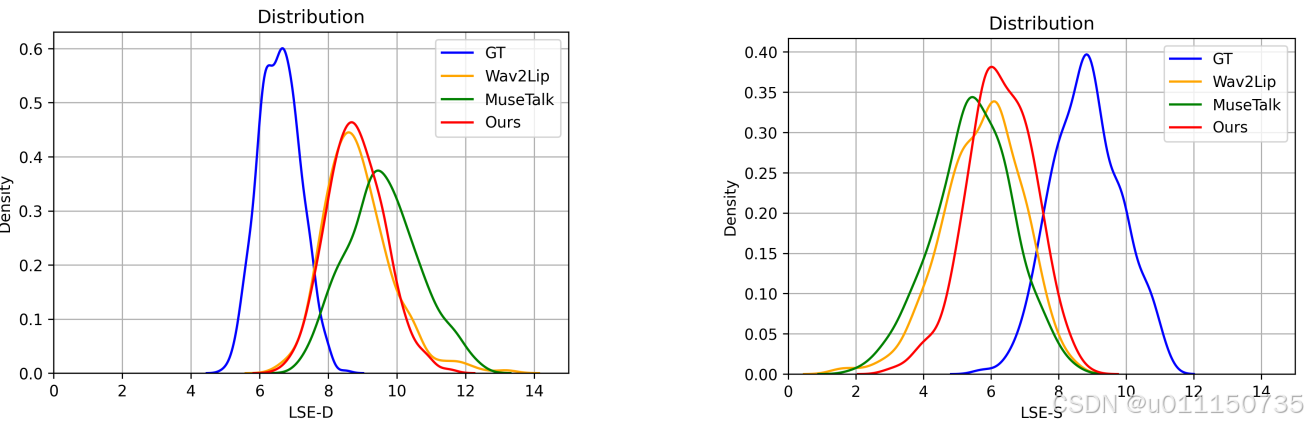
图 3
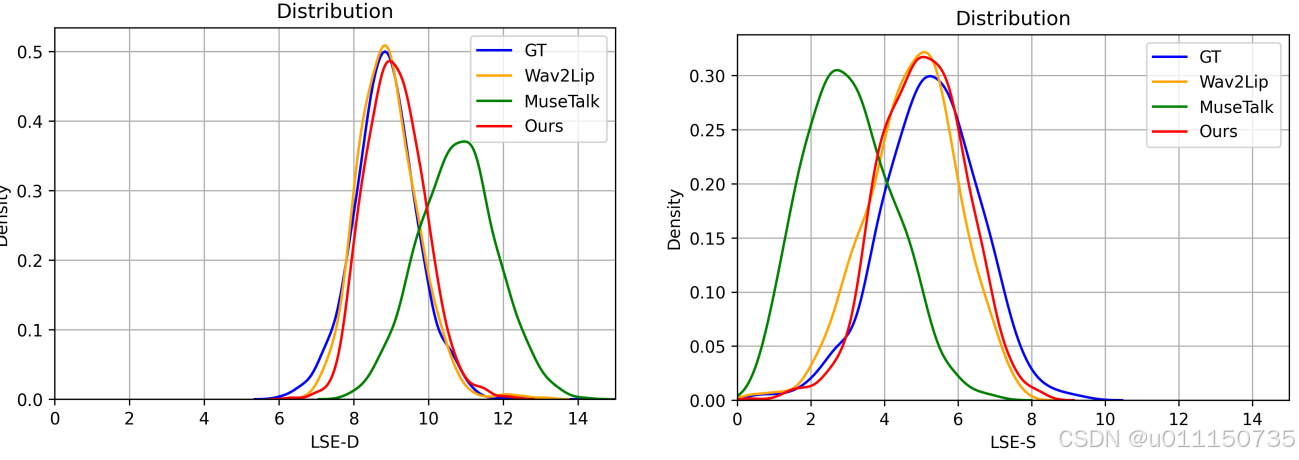
图 4
定性结果
为了更直观地评估唇形同步和视觉质量,论文进行了几种方法的直观比较分析。图5展示了每个生成视频中的唇部动态以及参考驱动视频。每一列包含视频中的六个连续帧。JoyGen方法在视频质量和唇部运动精确度上表现更优。在左侧的驱动视频中,嘴唇从张开到闭合再到张开;而在右侧,它从闭合到张开。只有JoyGen方法保持了与驱动视频一致的唇形对齐。尽管基于Wav2Lip的视频在LSE-D和LSE-C得分上更好,但Wav2Lip往往会生成模糊的嘴部区域。
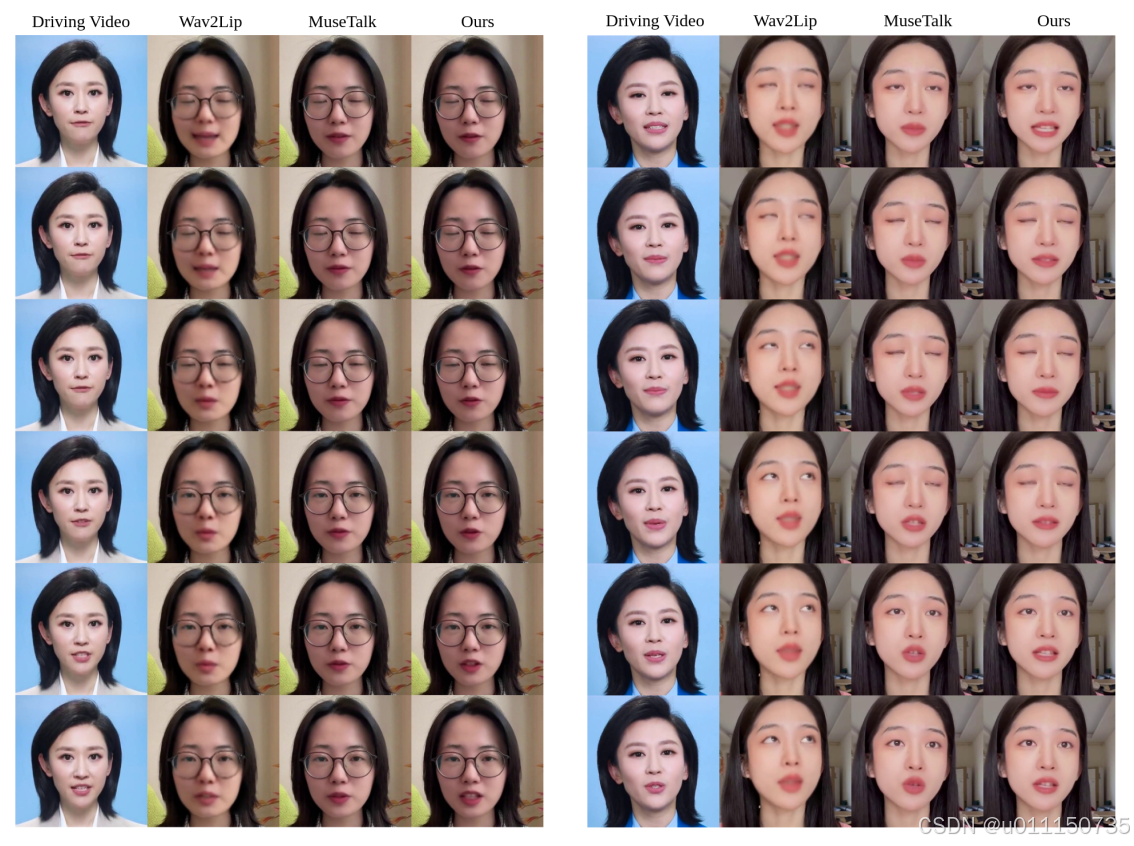
图 5


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









