










前言
前文所述,要理解隐马尔可夫首先需要梳理几个步骤:
1. 如何理解概念
2. 什么叫转移概率矩阵和生成概率矩阵
3. 模型公式
5. 公式的求解过程
6. python代码串接
五、公式的求解过程
上一篇中,我们提到HMM可以解决的三个经典问题,我们现在就看下问题一
评估可观测序列概率。即给定模型
λ
=
(
A
,
B
,
η
)
\lambda = (A, B,\eta)
λ=(A,B,η)和观测序列
𝑂
=
𝑜
1
,
𝑜
2
,
.
.
.
𝑜
𝑇
𝑂={𝑜_{1},𝑜_{2},...𝑜_{𝑇}}
O=o1,o2,...oT,计算在模型𝜆下可观测序列𝑂出现的概率𝑃(𝑂|𝜆), 如上述例子的骰子,如投3次,可观测的点数序列1,6,3 的概率是多少?
5.1 例举法
求上述问题的时,我们可以暴力求解,如下
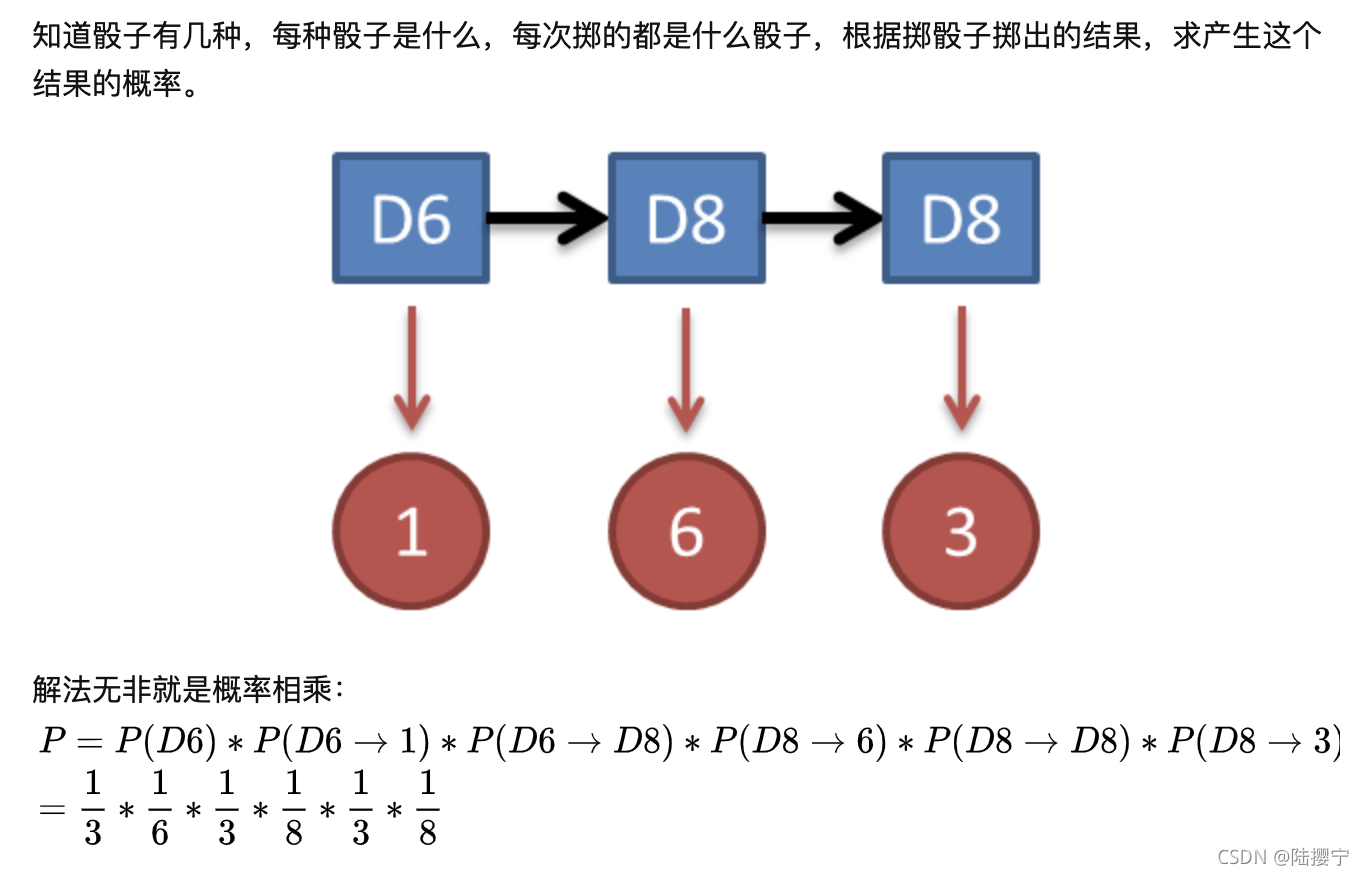
上图只是我们在例句当骰子的不可观测序列为D6->D8->D8的情况,还有其他的不可观测序列,就不一一列出来了,下面是用公式的形式展示出来。
我们可以列举出所有可能出现的长度为𝑇的不可观测序列
𝐼
=
𝑖
1
,
𝑖
2
,
.
.
.
,
𝑖
𝑇
𝐼={𝑖_{1},𝑖_{2},...,𝑖_{𝑇}}
I=i1,i2,...,iT,分布求出这些不可观测序列与可观测序列
𝑂
=
𝑜
1
,
𝑜
2
,
.
.
.
𝑜
𝑇
𝑂={𝑜_{1},𝑜_{2},...𝑜_{𝑇}}
O=o1,o2,...oT的联合概率分布𝑃(𝑂,𝐼|𝜆),这样我们就可以很容易的求出边缘分布𝑃(𝑂|𝜆)了,公式如下:
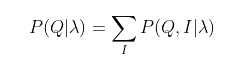
其中, 联合分布可以拆分成下面个式子:
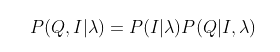
其中, 由于任意一个不可观测序列
𝐼
=
𝑖
1
,
𝑖
2
,
.
.
.
,
𝑖
𝑇
𝐼={𝑖_{1},𝑖_{2},...,𝑖_{𝑇}}
I=i1,i2,...,iT出现的概率是:
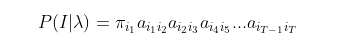
然后,我们先固定一个不可观测序列
𝐼
=
𝑖
1
,
𝑖
2
,
.
.
.
,
𝑖
𝑇
𝐼={𝑖_{1},𝑖_{2},...,𝑖_{𝑇}}
I=i1,i2,...,iT下,求可观测序列
𝑂
=
𝑜
1
,
𝑜
2
,
.
.
.
𝑜
𝑇
𝑂={𝑜_{1},𝑜_{2},...𝑜_{𝑇}}
O=o1,o2,...oT出现的概率:
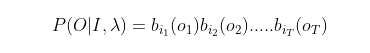
所以,综上所述,我们得到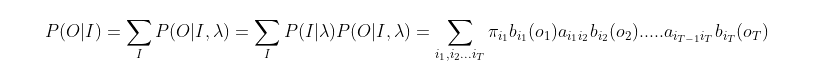
上面公式就是我们把所有的组合都相乘起来,那么可观测状态就有
𝑁
𝑇
𝑁^{𝑇}
NT种组合方式,我们得到的算法的时间复杂度是
𝑂
(
𝑇
𝑁
𝑇
)
𝑂(𝑇𝑁^{𝑇})
O(TNT)阶的。对于一些不可观测状态数极少的模型,我们可以用这种求解法来得到观测序列出现的概率,但是如果不可观测状态多,则上述算法太耗时了,所以我们还需要找到另一种方法解题。
5.2 前向后向算法
前向后向算法是前向算法和后向算法的统称,这两个算法都可以用来求HMM观测序列的概率
5.2.1 前向算法
概念:前向算法本质上属于动态规划的算法,也就是我们要通过找到局部状态递推的公式,这样一步步的从子问题的最优解拓展到整个问题的最优解。
那么在前向算法中,通过定义“前向概率”来定义动态规划的这个局部状态(时刻t之前)。什么是前向概率呢, 其实定义很简单:定义时刻 𝑡 时不可观测状态为
𝑞
k
,
k
∈
N
𝑞_{k}, k\in N
qk,k∈N, 观测状态的序列为
O
t
=
𝑜
1
,
𝑜
2
,
.
.
.
𝑜
𝑡
O_t=𝑜_1,𝑜_2,...𝑜_𝑡
Ot=o1,o2,...ot的概率为前向概率。记为:
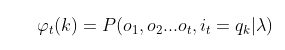
既然是动态规划,我们就要递推了,现在我们假设我们已经找到了在时刻𝑡时各个不可观测状态的前向概率(也就是说上面公式只表达了不可观测状态为
𝑞
k
𝑞_{k}
qk的前向概率),现在我们需要递推出时刻𝑡+1时各个不可观测状态的前向概率。
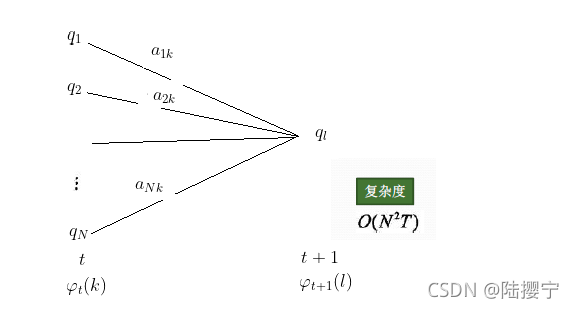
上图
1)我们可以基于时刻𝑡时各个(N个)不可观测状态的前向概率
φ
t
(
k
)
\varphi_t(k)
φt(k),再乘以对应的不可观测的状态转移概率
a
k
l
a_{kl}
akl,即:
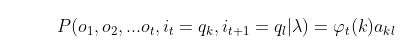
就是在时刻 𝑡 可观测到
O
t
=
𝑜
1
,
𝑜
2
,
.
.
.
𝑜
𝑡
O_t=𝑜_1,𝑜_2,...𝑜_𝑡
Ot=o1,o2,...ot,其中
i
t
=
𝑞
k
,
k
∈
N
i_t=𝑞_k, k\in N
it=qk,k∈N;
i
𝑡
+
1
=
q
l
,
l
∈
N
i_{𝑡+1}=q_l , l\in N
it+1=ql,l∈N 的概率,(只把时刻t的不可观测的
q
k
q_k
qk都考虑了)
2)如果想将下面所有的线对应的概率求和,即:
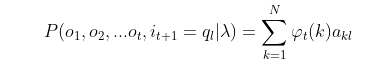
就是在时刻𝑡可观测到 O t = 𝑜 1 , 𝑜 2 , . . . 𝑜 𝑡 O_t=𝑜_1,𝑜_2,...𝑜_𝑡 Ot=o1,o2,...ot,其中 i 𝑡 + 1 = q l , l ∈ N i_{𝑡+1}=q_{l}, l\in N it+1=ql,l∈N 的概率,(都把时刻t的各个不可观测的 q N q_N qN都考虑了)
3)继续一步,由于可观测状态
o
t
+
1
o_{t+1}
ot+1只依赖于𝑡+1时刻不可观测状态
q
l
q_{l}
ql, 这样
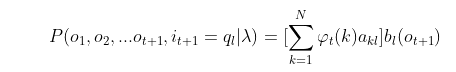
就是在在时刻𝑡+1可观测到
O
t
+
1
=
𝑜
1
,
𝑜
2
,
.
.
.
𝑜
𝑡
+
1
O_{t+1}={𝑜_1,𝑜_2,...𝑜_{𝑡+1}}
Ot+1=o1,o2,...ot+1,其中
i
𝑡
+
1
=
q
l
i_{𝑡+1}=q_{l}
it+1=ql
而这个概率,恰恰就是时刻𝑡+1对应的不可观测状态
l
l
l的前向概率(看上面定义前向概率的公式),这样我们得到了前向概率的递推关系式如下:
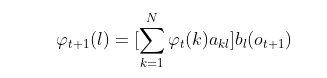
我们的动态规划从时刻1开始,到时刻𝑇结束,由于
φ
T
(
K
)
\varphi_{T}(K)
φT(K)表示在时刻𝑇观测序列为
O
T
=
𝑜
1
,
𝑜
2
,
.
.
.
𝑜
T
O_T=𝑜_1,𝑜_2,...𝑜_T
OT=o1,o2,...oT,并且时刻𝑇不可观测状态
q
K
q_K
qK的概率,我们只要将所有不可观测状态对应的概率相加,即:
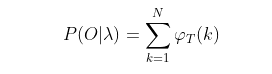
就得到了在时刻𝑇观测序列为
O
T
=
𝑜
1
,
𝑜
2
,
.
.
.
𝑜
T
O_T=𝑜_1,𝑜_2,...𝑜_T
OT=o1,o2,...oT的概率。
下面总结下前向算法。
输入: HMM模型𝜆=(𝐴,𝐵,Π),观测序列
O
T
=
(
𝑜
1
,
𝑜
2
,
.
.
.
𝑜
T
)
O_T=(𝑜_1,𝑜_2,...𝑜_T)
OT=(o1,o2,...oT)
输出: 观测序列概率𝑃(𝑂|𝜆)
- 计算时刻1的各个隐藏状态前向概率:
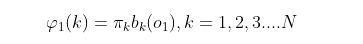
- 递推时刻2,3,…𝑇时刻的前向概率:
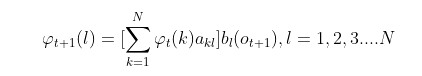
- 计算最终结果:
从递推公式可以看出,我们的算法时间复杂度是𝑂(𝑇𝑁2),比暴力解法的时间复杂度𝑂(𝑇𝑁𝑇)少了几个数量级。
(有个实际例子请看参考资料3. HMM前向算法求解实例)
5.2.1 后向算法
后向算法和前向算法非常类似,都是用的动态规划,唯一的区别是选择的局部状态不同,后向算法用的是“后向概率”,那么后向概率是如何定义的? 定义时刻t时不可观测状态为
q
k
q_k
qk, 从时刻t+1到最后时刻T的观测状态的序列为
o
t
+
1
,
o
t
+
2
,
.
.
.
o
T
o_{t+1},o_{t+2},...o_{T}
ot+1,ot+2,...oT的概率为后向概率。记为:
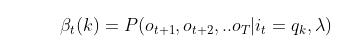
后向概率的动态规划递推公式和前向概率是相反的。现在我们假设我们已经找到了在时刻t+1时各个不可观测状态的后向概率
β
t
+
1
(
l
)
\beta_{t+1}(l)
βt+1(l),现在我们需要递推出时刻t时各个不可观测状态的后向概率。
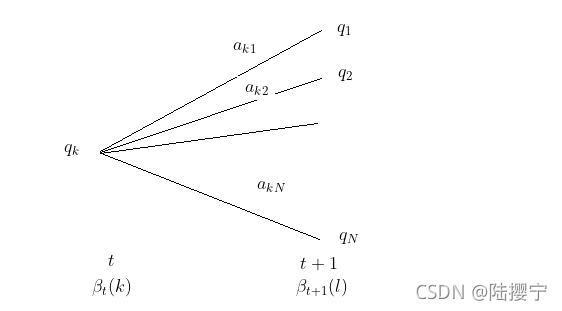
上图
1)我们可以计算出观测状态的序列为
o
t
+
2
,
o
t
+
3
,
.
.
.
o
T
o_{t+2},o_{t+3},...o_T
ot+2,ot+3,...oT, t时隐藏状态为
q
k
q_k
qk, 时刻t+1隐藏状态为
q
l
q_l
ql的概率:
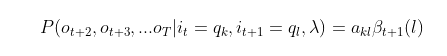
2)接着可以得到观测状态的序列为
o
t
+
1
,
o
t
+
2
,
.
.
.
o
T
o_{t+1},o_{t+2},...o_T
ot+1,ot+2,...oT, t时隐藏状态为
q
k
q_k
qk, 时刻t+1隐藏状态为
q
l
q_l
ql的概率:
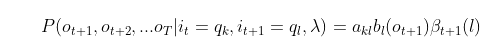
3)把下面所有线对应的概率加起来,我们可以得到观测状态的序列为
o
t
+
1
,
o
t
+
2
,
.
.
.
o
T
o_{t+1},o_{t+2},...o_T
ot+1,ot+2,...oT, t时隐藏状态为
q
k
q_k
qk的概率为
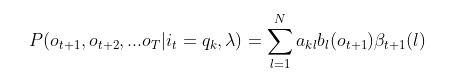
这个概率即为时刻t的后向概率 ,这样我们得到了后向概率的递推关系式如下:
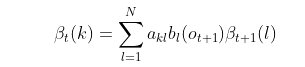
现在我们总结下后向算法的流程,注意下和前向算法的相同点和不同点:
输入: HMM模型λ=(A,B,Π),观测序列O=(o1,o2,…oT)
输出: 观测序列概率P(O|λ)
- 初始化时刻T的各个隐藏状态后向概率:
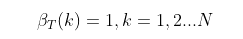
- 递推时刻T−1,T−2,…1时刻的后向概率:
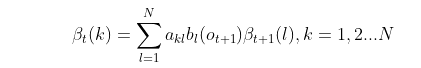
- 计算最终结果:
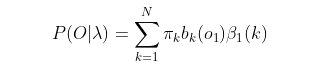
此时我们的算法时间复杂度仍然是O(TN2)。















 6061
6061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









