







 本文介绍了如何使用Python的urllib2和正则表达式抓取ZOL桌面壁纸网站的所有壁纸类型,并通过多线程加速下载。通过分析HTML代码,提取类型集合URL和名称,然后利用已有的函数下载每个类型集合的壁纸,同时解决了线程中的假死问题。
本文介绍了如何使用Python的urllib2和正则表达式抓取ZOL桌面壁纸网站的所有壁纸类型,并通过多线程加速下载。通过分析HTML代码,提取类型集合URL和名称,然后利用已有的函数下载每个类型集合的壁纸,同时解决了线程中的假死问题。
前篇回顾:获得一个类型集合页面中所有集合中的图片
本篇目标:获取整个网站所有类型集合的壁纸图片
使用urllib2,正则表达式,threading等高效下载网站’http://desk.zol.com.cn‘中壁纸图片。
使用urllib2获取url = ‘http://desk.zol.com.cn‘中HTML代码,从HTML中使用正则表达式截取我们所需要的内容。
建立函数def getImgTotal(url, filePath):
首先,获取HTML。
代码如下:
115 def getImgTotal(url, filePath):
116 if not os.path.exists(filePath):
117 os.makedirs(urlPath)
118 if not filePath.endswith('/'):
119 filePath += '/'
120
121 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
122 headers = {
'User-Agent' : user_agent}
123
124 request = urllib2.Request(url, headers=headers)
125 content = urllib2.urlopen(request).read().decode('GBK')
126
127 f = open('url.txt', 'w')
128 f.write(content.encode('utf-8'))
129 f.close()
130
131 print content
132部分结果截图:
我们要获取的部分为图片类型分类如下图:
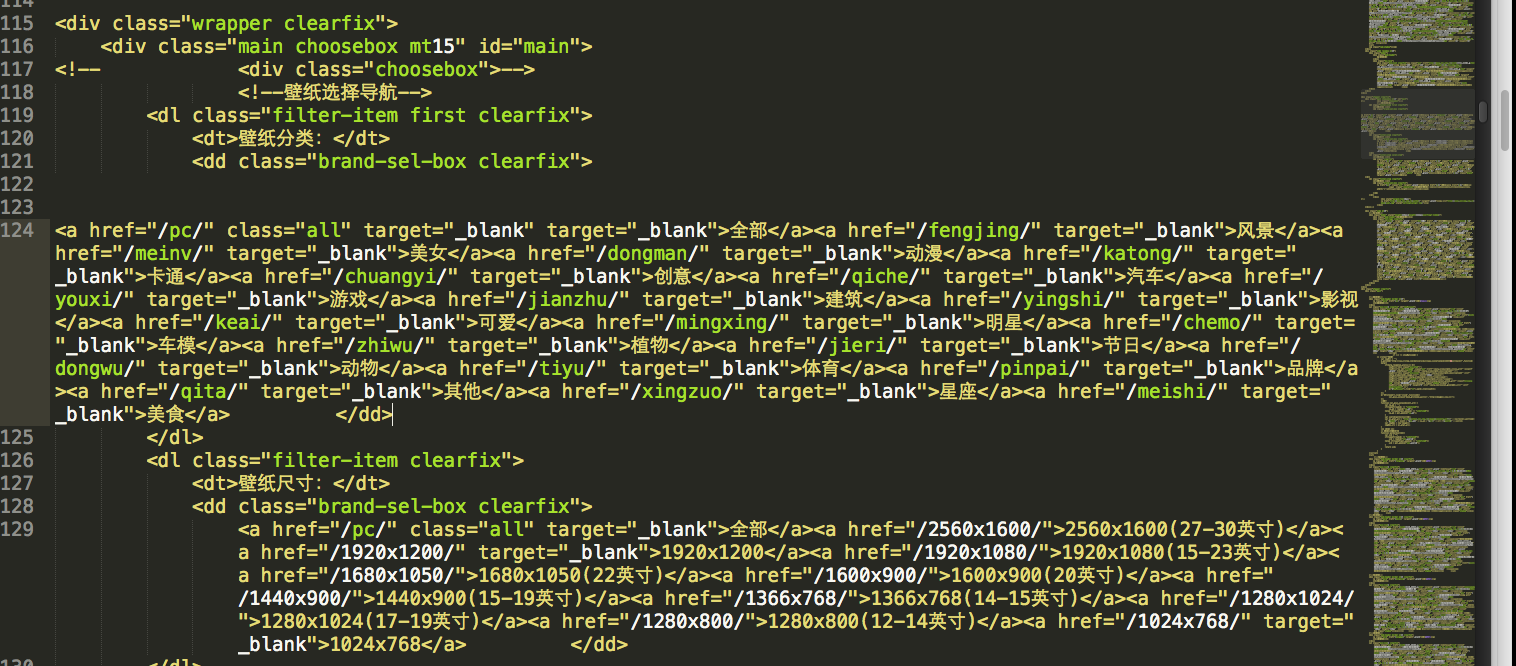
从中要获取类型集合的url和类型集合的名称。
使用正则表达式截取如下:
‘
115 def getImgTotal(url, filePath):
116 if not os.path.exists(filePath):
117 os.makedirs(urlPath)
118 if not filePath.endswith('/'):
119 filePath += '/'
120
121 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









