







Scala语言基础
1. Scala词法
Scala 程序使用的字符集是 Unicode 的基本多文种平面字符集; 下面定义了 Scala 词法的两种模式:Scala 模式与 XML 模式。 如果没有特别说明,以下对 Scala 符号的描述均指 Scala 模式,常量字符‘c’指 ASCII 段\u0000-\u007F。
在 Scala 模式中,十六进制 Unicode 转义字符会被对应的 Unicode 字符替换。
UnicodeEscape ::= \{\\}u{u} hexDigit hexDigit hexDigit hexDigit
hexDigit ::= ‘0’......’9’ ‘A’......’F’ a’......’f’
符号由下面几类字符构成(括号中是 Unicode 通用类别):
1. 空白字符: \u0020 | \u0009 | \u000D | \u000A
2. 字母:包括小写 (Ll),大写 (Lu),词首字母大写 (Lt),其他 (Lo),数字 (Nl),以及\u0024 ‟$‟ 和 \u005F „_‟,这两个字母归类为大写字母
3. 数字: ‘0’.........‘9’
4. 括号: ‘()’ | ‘[]’ | ‘{}’。
5. 分隔符: ‘.’ ’;’ ‘,’
6. 算符字符:由所有的没有包括在以上分类中的可打印 ASCII 字符\u0020 - \u007F,数学符号(Sm)以及其他符号(So)构成
2.Scala基本语法
区分大小写 :
Scala和Java一样是大小写敏感的,比如Person和person就是一样的。
类名 :
对于所有的类名的第一个字母要大写。如果需要使用几个单词来构成一个类的名称,每个单词的第一个字母要大写。
示例:class MyFirstScalaClass
方法名称 :
所有的方法名称的第一个字母用小写。
如果若干单词被用于构成方法的名称,则每个单词的第一个字母应大写。
示例:def myMethodName()
程序文件名 :
程序文件的名称应该与对象名称完全匹配。
保存文件时,应该保存它使用的对象名称(记住Scala是区分大小写),并追加".scala"为文件扩展名。 (如果文件名和对象名称不匹配,程序将无法编译)。
示例: 假设"HelloWorld"是对象的名称。那么该文件应保存为'HelloWorld.scala"
def main(args: Array[String]) :
Scala程序从main()方法开始处理,这是每一个Scala程序的强制程序入口部分。
3.Scala标识符
Scala有三种方法可以构造一个标识符。第一,首字符是字母,后续字符是任意字母和数字。 这种标识符还可后接下划线‟_‟,然后是任意字母和数字。第二,首字符是算符字符,后 续字符是任意算符字符。这两种形式是普通标识符。最后,标识符可以是由反引号‟`‟括 起来的任意字符串(宿主系统可能会对字符串和合法性有些限制)。这种标识符可以由除了 反引号的任意字符构成。
字符数字使用字母或是下划线开头,后面可以接字母或是数字,符号"$"在 Scala 中也看作为字母。然而以"$"开头的标识符为保留的 Scala 编译器产生的标志符使用,应用程序应该避免使用"$"开始的标识符,以免造成冲突。
Scala 的命名规则和 Java 类似,首字符小写,比如 toString。类名的首字符还是使用大写。此外也应该避免使用以下划线结尾的标志符以避免冲突。符号标志符包含一个或多个符号,如+,:,? 等。
Scala 内部实现时会使用转义的标志符,比如:-> 使用 $colon$minus$greater 来表示这个符号。因此如果你需要在 Java 代码中访问:->方法,你需要使用 Scala 的内部名称 $colon$minus$greater。
混合标志符由字符数字标志符后面跟着一个或多个符号组成,比如 unary_+ 为 Scala 对+方法的内部实现时的名称。字面量标志符为使用"定义的字符串,比如 `x` `yield`。
你可以在"之间使用任何有效的 Scala 标志符,Scala 将它们解释为一个 Scala 标志符,一个典型的使用为 Thread 的 yield 方法, 在 Scala 中你不能使用 Thread.yield()是因为 yield 为 Scala 中的关键字, 你必须使用 Thread.`yield`()来使用这个方法。
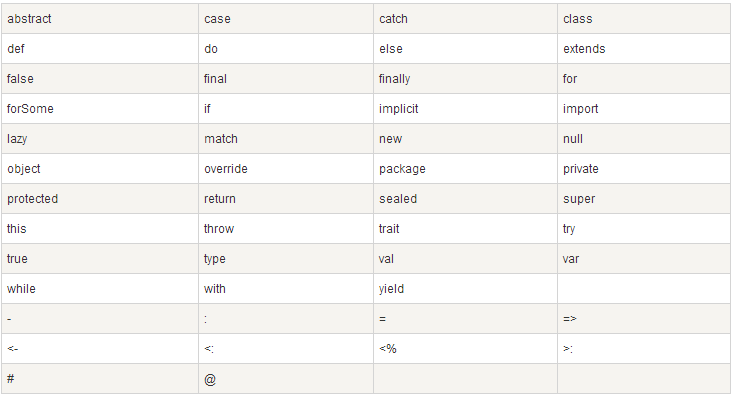
4.Scala关键字
以下是Scala中的关键字,注意不可以使用关键字命名变量。
5.Scala注释
Scala的注释和Java类似:有单行注释、多行注释和文档注释
示例:
单行注释:
// var lines = Source.fromURL("http://www.baidu.com").getLines()多行注释:
/*
object exam1 {
def main(args: Array[String]): Unit = {
var lines = Source.fromURL("http://www.baidu.com").getLines()
lines.foreach(println)
}
}
*/文档注释示例:
/**
* Created by Chen on 2016/3/22.
* 业务:获取www.baidu.com网页源码
*/
6.空行和空格
一行中只有空格或者带有注释,Scala 会认为其是空行,会忽略它。标记可以被空格或者注释来分割。
7.换行符
Scala 是一个基于行的语言。分号和换行均可作为语句的结束。如果一行里写多个语句那么分号是需要的。如果换行满足以下三 个条件则会被认为是一个特殊符号‟nl‟:
1. 换行之前的符号是一个语句的结束
2. 换行之后的符号是一个语句的开始
3. 符号处在一个允许多语句的区域中 可以作为语句结束的符号是:常量,标识符,保留字以及以下的分隔符:

可以作为语句开始的符号是除了以下分隔符及保留字之外的所有 Scala 符号:

符号 case 只有在 class 或者 object 符号之前才可以作为语句开始。
多行语句许可的条件:
1. 整个 Scala 源文件中,除了换行被禁止的嵌套区域
2. 在匹配的{与}之间,除了换行被禁止的嵌套区域
多行语句在以下区域被禁止:
1. 在匹配的(与)之间,除了换行被允许的嵌套区域。
2. 在匹配的[与]之间,除了换行被允许的嵌套区域。
3. 在 case 符号以及与其匹配的=>符号之间,除了换行被允许的嵌套区域。
4. XML 模式下的区域。
注意在 XML 中大括号{..}被转义,字符串并不是符号。因此当换行被允许时不要关 闭区域。
一般地,即使连续的两个非换行符号中有多行,也只会插入一个 nl 符号。然而,如 果两个符号被至少一个空行(行中没有可打印字符)分隔开,那么两个符号中就会插入两个 nl 符号。
Scala 语法允许可选的 nl 符号,但分号不在此列。这样在某些位置 换行并不会结束一个表达式或语句。这些位置如下所列:
以下位置允许多个换行符号(换了分号是不行地):
- -在条件表达式或 while 循环的条件及下一个表达式间
- -For 循环中计数器及下一个表达式间
- -类型定义或声明中,在开始的 type 关键字之后 以下位置允许单个换行:
- -在一个是当前语句或表达式的合法继续的大括号”{”前
- -如果下行的第一个符号是一个表达式的开始,本行的中缀算符之后
- -在一个参数子句前
- -在一个标注之后
示例1 : 以下是跨两行的四个合法语句。两行间的换行符号并未作为语句结束。
if(x > 0) x
= x – 1
while(x > 0) x
= x / 2
for(x <- 1 to 10)
println(x)
type
IntList = List[Int]
示例2 : 以下代码定义了一个匿名类
加一个换行后,同样的代码就成了一个对象创建和一个局部代码块
new Iterator[Int]
{
private var x = 0
def hasNext = true
def next = { x += 1; x }
}
示例3 : 以下代码定义了一个表达式:
x < 0 || x > 10
加一个换行后就成了两个表达式:
x < 0 ||
x > 10
示例4 : 以下代码定义了一个单一的柯里化的函数:
def func(x: Int)
(y: Int) = x + y
加一个换行后,同样的代码就成了一个抽象函数和一个非法语句
def func(x: Int)
<span style="white-space:pre"> </span>(y: Int) = x + y示例5 : 以下代码是一个加了标注的定义:
@serializable
protected class Data{...}
加一个换行后,同样的代码就成了一个属性标记和一个单独的语句(实际上是非法的)
@serializable
protected class Data{...}
8.Scala包
定义包
Scala 使用 package 关键字定义包,在Scala将代码定义到某个包中有两种方式:
第一种方法:
package com.idoshare.scala第二种方法:
package com.idoshare{
class Test{
}
}
9.引用
Scala 使用 import 关键字引用包。
例如:
import scala.io.Source
import scala.xml.XML
import scala.xml.parsing.ConstructingParserimport语句可以出现在任何地方,而不是只能在文件顶部。import的效果从开始延伸到语句块的结束。这可以大幅减少名称冲突的可能性。
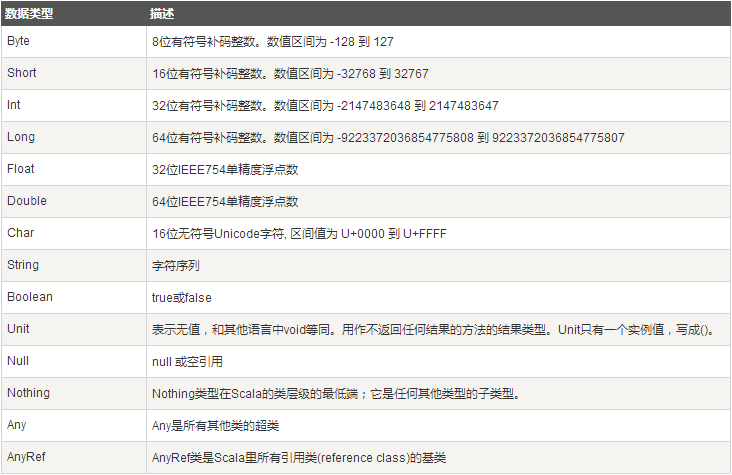
10.Scala数据类型
Scala 与 Java有着相同的数据类型,下表列出了 Scala 支持的数据类型:
11.Scala基础字面量
整型字面量
整型字面值通常表示 Int 型,或者后面加上 L 或 l 表示 Long 型。Int 的值的范围是-231 到 231-1 间的整数,包含边界值。Long 的值的范围是-263 到 263-1 间的整数,包含 边界值。整型字面值的值超出以上范围就会导致编译错误。
如果一个字面值在表达式中期望的类型 pt是 Byte, Short 或者 Char 中的 一个,并且整数的值符合该类型的值的范围,那么这个数值就会被转为 pt 类型,这个字 面值的类型也是 pt。数值范围如下所示:
- Byte -27 到 27-1
- Short -215 到 215-1
- Char 0 到 216-1
示例 : 以下是一些整型字面值:
0 21 0xFFFFFFFF 0777L
浮点型字面量
如果浮点数字面值的后缀是 F 或者 f,那么这个字面值的类型是 Float,否则就是 Double。Float 类型包括所有 IEEE 754 32 位单精度二进制浮点数值,Double 类型 包括所有 IEEE 754 64 位双精度二进制浮点数值。
如果程序中浮点数字面值后面跟一个字母开头的符号,那么这两者之间应当至少有一 个空白字符。
示例 : 以下是一些浮点型字面值:
0.0 1e30f 3.14159f 1.0e-100 .1
布尔型字面量
布尔型字面值 true 和 false 是 Boolean 类型的成员
符号字面量
符号字面量被写成: '<标识符> ,这里 <标识符> 可以是任何字母或数字的标识(注意:不能以数字开头)。这种字面量被映射成预定义类scala.Person的实例。
如: 符号字面量 'x 是表达式 scala.Person("x") 的简写,符号字面量定义如下:
package scalafinal case class Person private (name: String) {
override def toString: String = "'" + name
}字符字面量
字符型字面值就是单引号括起来的单个字符。字符可以是可打印 unicode 字符或者 由一个转义序列描述的 unicode 字符。
示例 :以下是一些字符型字面值:
'a' '\u0041' '\n' '\t'注意’\u000A‘不是一个合法的字符常数,因为在处理字面值前已经完成了 Unicode 转换,而 Unicode 字符\u000A(换行)不是一个可打印字符。可以使用转义序列’\n‘或 八进制转义’\12‘来表示一个换行字符。
字符串字面量
字符串字面值是由双引号括起来的字符序列。字符必须是可打印 unicode 字符或者 转义序列。如果一个字符串字面值包括双引号,那么这个双引号必须用转义字 符,比如:\”。字符串字面值的值是类 String 的一个实例。
示例 : 以下是一些字符串字面值
"Hello,\nWorld!"
"This string contains a \" character."
多行字符串字面值
多行字符串字面值是由三个双引号括起来的字符序列”””...”””。字符序列是除了三 个双引号之外的任意字符序列。字符不一定必须是可打印的;换行或者其他控制字符也是 可以的。Unicode 转义序列也可以,不过转义序列不会被解析。
示例 : 以下是一个多行字符串字面值:
"""the present string
spans three
lines."""以上语句会产生如下字符串:
the present string
spans three
lines.Scala 库里包括一个工具方法 stripMargin,可以用来去掉多行字符串行首的空格。stripMargin默认以'|'字符作为连接符。
表达式:
"""the present string
|spans three
|lines.""".stripMargin值为:
the present string
spans three
lines.
stripMargin 方法定义在类 scala.runtime.RichString。由于有预定义的从 String 到 RichString 的隐式转换,因此这个方法可以应用到所有的字符串。
Null 值
空值是 scala.Null 类型。
Scala.Null和scala.Nothing是用统一的方式处理Scala面向对象类型系统的某些"边界情况"的特殊类型。
Null类是null引用对象的类型,它是每个引用类(继承自AnyRef的类)的子类。Null不兼容值类型。
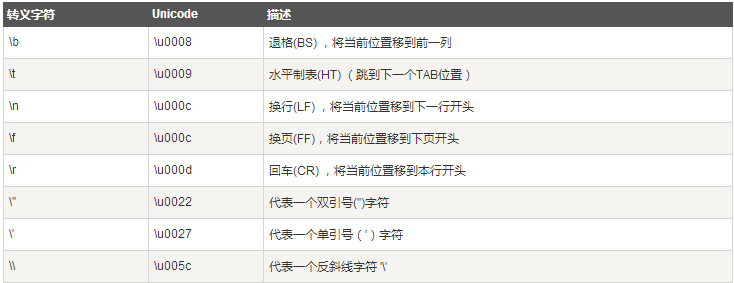
Scala转义字符
下表列出了常见的转义字符:
0 到 255 间的 Unicode 字符可以用一个八进制转义序列来表示,即反斜线‟\‟后跟 最多三个八进制。
在字符或字符串中,反斜线和后面的字符序列不能构成一个合法的转义序列将会导致 编译错误。
以下实例演示了一些转义字符的使用:
object Test {
def main(args: Array[String]) {
println("Hello\tWorld\n\n" );
}
}
12.值类型
Scala 中的每个值都有一个以下格式的类型:
单例类型
单例类型具有 p.type 的形式,p 是一个路径,指向一个期望与 scala.AnyRef 一 致的值。类型指一组为 null 的或由 p 表示的值。
一个稳定类型指要么是一个单例类型,要么是特征 scala.Singleton 的子类型。
类型映射
类型映射 T#x 指类型 T 的类型成员 x。如果 x 指向抽象类型成员,那么 T 必须是一个稳定类型。
类型指示
类型指示指一个命名值类型。它可以是简单的或限定的。所有的这些类型指示都是类 型映射的简写。
绑定在某类,对象或包 C 上的非限定的类型名 t 是 C.this.type#t 的简写,除非类 型 t 是类型模式的一部分。后者中的 t 是 C#t 的简写。如果 t 没有被绑定在某 类,对象或包上,那么 t 就是 ε.type#t 的简写。
一个限定的类型只是具有 p.t 的形式,p 是一个路径,t 是一个类型名。这 个类型指示等价于类型映射 p.type#t。
示例 :以下是一些类型指示以及扩展。我们假定一个本地类型参数 t,一个值 maintable 具有一个类型成员 Node,以及一个标准类 scala.Int
t <span style="white-space:pre"> </span>ε.type#t
Int <span style="white-space:pre"> </span>scala.type#Int
scala.Int <span style="white-space:pre"> </span>scala.type#Int
data.maintable.Node data.maintable.type#Node
参数化类型
参数化类型 T[U1,...,Un]包括类型指示 T 以及类型参数 U1,...,Un,n >=1。T 必 须指向一个具有个参数类型 a1,...,an 的参数构造方法。
类型参数具有下界 L1,...,Ln 和上界 U1,...,Un。参数化类型必须保证每个参数 与其边界一致:σLi<:Ti<:σUi,这里 σ 表示[a1:=T1,...,an:=Tn]。
示例1: 以下是一些类型定义(部分):
class TreeMap[A <: Comparable[A], B]{ ... }
class List[A] { ... }
class I extends Comparable[I] { ... }
以下是正确的参数化类型:
TreeMap[I, String]
List[I]
List[List[Boolean]]
示例 2:使用示例1的类型定义,以下是错误的参数化类型:
TreeMap[I] //错误的参数个数
TreeMap[List[I], Boolean] //类型参数越界元组类型
元组类型(T1,...,Tn)是类 scala.Tuplen[T1,...,Tn](n>=2)的别名形式。此类 型可以在结尾处有个额外的逗号,例:(T1,...,Tn,)。
元组类是 case 类,其字段可以用选择器_1,...,_n 来访问。在对应的 Product 特 征中有他们的抽象函数。这些元组类以及 Product 特征都是标准 Scala 类库的一部分, 其形式如下:
case class Tuplen[+T1,...,+Tn](_1: T1,...,_n: Tn) extends
Productn[T1,...,Tn]{}
trait Productn[+T1,...,+Tn]{
override def arity = n
def _1: T1
...
def _n: Tn
}
标注类型
标注类型 T a1,...,an 就是给类型 T 加上标注 a1,...,an.
复合类型
复合类型 T1 with ... with Tn {R}指一个拥有 T1,...,Tn 类型中的成员以及修 饰{R}的对象。如果对象中有声明或定义覆盖了成分类型 T1,...,Tn 中的声明或定义,就 会应用通常的覆盖规则;否则这个声明或定义就将是所谓的“结构化的”。在
一个结构化修饰的方法声明中,任何值参数的类型只是指修饰内部包含的类型参数或抽象 类型。也就是它必须指代一个函数本身的类型参数,或者在修饰内部的一个类型定义。该限制并不对函数的返回类型起作用。 如果没有修饰,那么默认就会添加一个空的修饰,例:T1 with ... with Tn 即是T1 with ... with Tn {}的简写。
一个复合类型可以只有 修饰 {R} 而 没 有 前 面 的 成 分 类 型 。 这 样 的 类 型 等 价 于AnyRef{R}。
示例 :以下是如何声明以及使用参数类型包含结构化声明修饰的函数。
case class Bird (val name: String) extends Object {
def fly(height: Int) = ...
...
}
case class Plane (val callsign: String) extends Object {
def fly(height: Int) = ...
...
}
def takeoff(
runway: Int,
r: { val callsign: String; def fly(height: Int) }) = { tower.print(r.callsign + “ requests take-off on runway “ + runway) tower.read(r.callsign + “ is clear for take-off”)
r.fly(1000)
}
val bird = new Bird(“Polly the parrot”){ val callsign = name }
val a380 = new Plane(“TZ-987”) takeoff(42, bird)
takeoff(89, a380)虽然 Bird 和 Plane 没有除了 Object 之外的任何父类,用结构化声明修饰的函数,takeoff 的参数 r 却可以接受任何声明了值 callsign 以及函数 fly 的对象。
中缀类型
中缀类型 T1 op T2 由一个中缀算符 op 应用到两个操作数 T1 和 T2 上得来。这个类型 等价于类型应用 op[T1, T2]。中缀算符可以是除*之外的任意的标识符,因为*被保留作 为重复参数类型的后缀。
函数类型
类型 (T1,...,Tn) => U 表示那些参数类型为 T1,...,Tn,并产生一个类型为 U 的 结果的函数。如果只有一个参数类型则(T)=>U 可以简写为 T=>U。类型(=>T)=>U 表示以 类型为 T 的传名参数并产生类型为 U 的结果。函数类型是右结合的,例: S=>T=>U 等价于 S=>(T=>U)。
函数类型是定义了 apply 函数的类类型的简写。比如 n 型函数类型(T1,...,Tn) => U 就是类 Functionn[T1,...,Tn,U]的简写。Scala 库中定义了 n 为 0 至 9 的这些类类 型,如下所示:
package scala
trait Functionn[-T1,...,-Tn, +R] {
def apply(x1: T1,...,xn: Tn): R
override def toString = “<function>”
}因此,函数类型与结果类型是协变的,与参数类型是逆变的。
传名函数类型(=>T)=>U 是类类型 ByNameFunction[T,U]的简写形式,定义如下:
package scala
trait ByNameFunction[-T, +R] {
def apply(x: => T): R
override def toString = “<function>”
}既存类型
既存类型具有 T forSome {Q} 的形式, Q 是一个类型声明的序列 。设 t1[tps1]>:L1<:U1,...,tn[tpsn]>:Ln<:Un 是 Q 中声明的类型(任何类型参数部分 [tpsi]都可以没有)。每个类型 ti 的域都包含类型 T 和既存子句 Q。类型变量 ti 就称为 在类型 T forSome {Q}中被绑定。在 T 中但是没被绑定的类型变量就被称为在 T 中是自 由的。
T forSome {Q}的类的实例就是类 σT,σ 是 t1,...,tn 上的迭代,对于每一个 i, 都有 σLi<:σti<:σUi。既存类型 T forSome{Q}的值的集合就是所有其类型实例值的集合的合集。
T forSome {Q}的斯科伦化是一个类实例 σT,σ 是[t‟1/t1,..., t‟n/tn 上的迭代, 每个 t‟i 是介于 σLi 和 σUi 间的新的抽象类型。
13.Scala变量
变量是一种使用方便的占位符,用于引用计算机内存地址,变量创建后会占用一定的内存空间。基于变量的数据类型,操作系统会进行内存分配并且决定什么将被储存在保留内存中。因此,通过给变量分配不同的数据类型,你可以在这些变量中存储整数,小数或者字字母。
变量声明
在学习如何声明变量与常量之前,我们先来了解一些变量与常量。
一、变量: 在程序运行过程中其值可能发生改变的量叫做变量。如:时间,年龄。
二、常量 在程序运行过程中其值不会发生变化的量叫做常量。如:数值 3,字符'A'。
在 Scala 中,使用关键词 "var" 声明变量,使用关键词 "val" 声明常量。
声明变量实例如下:
var myVar : String = "Foo"<span style="white-space:pre"> </span>var myVar : String = "Bar"以上定义了变量 myVar,我们可以修改它。
声明常量实例如下:
val myVal : String = "Foo"以上定义了常量 myVal,它是不能修改的。如果程序尝试修改常量 myVal 的值,程序将会在编译时报错。
变量类型声明
变量的类型在变量名之后等号之前声明。定义变量的类型的语法格式如下:
var VariableName : DataType [= Initial Value]
val VariableName : DataType [= Initial Value]
变量声明不一定需要初始值,以下也是正确的:
var myVar :Int
val myVal :String
任何声明或定义的变量的命名不能以_=结尾。
变量定义 var x: T = _只能以模板成员出现。该定义表示一个可变字段和一个默认 初始值。该默认值取决于类型 T:
- 0 如果 T 是 Int 或其子类型
- 0L 如果 T 是 Long
- 0.0f 如果 T 是 Float
- 0.0d 如果 T 是 Double
- false 如果 T 是 Boolean
- {} 如果 T 是 Unit
- null 所有其他类型
变量类型引用
在 Scala 中声明变量和常量不一定要指明数据类型,在没有指明数据类型的情况下,其数据类型是通过变量或常量的初始值推断出来的。
所以,如果在没有指明数据类型的情况下声明变量或常量必须要给出其初始值,否则将会报错。
var myVar = 10
val myVal = "Hello, Scala!"以上实例中,myVar 会被推断为 Int 类型,myVal 会被推断为 String 类型。
Scala 多个变量声明
Scala 支持多个变量的声明:
val xmax, ymax = 100 // xmax, ymax都声明为100如果方法返回值是元组,我们可以使用 val 来声明一个元组:
val (myVar1: Int, myVar2: String) = Pair(40, "Foo")也可以不指定数据类型:
val (myVar1, myVar2) = Pair(40, "Foo")
14.Scala访问修饰符
Scala 访问修饰符基本和Java的一样,分别有:private,protected,public。
如果没有指定访问修饰符符,默认情况下,Scala对象的访问级别都是 public。
Scala 中的 private 限定符,比 Java 更严格,在嵌套类情况下,外层类甚至不能访问被嵌套类的私有成员。
私有(Private)成员
用private关键字修饰,带有此标记的成员仅在包含了成员定义的类或对象内部可见,同样的规则还适用内部类。
class Outer{
class Inner{
private def f(){println("f")}
class InnerMost{
f() // 正确
}
}
(new Inner).f() //错误}(new Inner).f( ) 访问不合法是因为 f 在 Inner 中被声明为 private,而访问不在类Inner之内。
但在 InnerMost 里访问f就没有问题的,因为这个访问包含在 Inner 类之内。
Java中允许这两种访问,因为它允许外部类访问内部类的私有成员。
保护(Protected)成员
在 scala 中,对保护(Protected)成员的访问比 java 更严格一些。因为它只允许保护成员在定义了该成员的的类的子类中被访问。而在java中,用protected关键字修饰的成员,除了定义了该成员的类的子类可以访问,同一个包里的其他类也可以进行访问。
package p{class Super{
protected def f() {println("f")}
}
class Sub extends Super{
f()
}
class Other{
(new Super).f() //错误
}}上例中,Sub 类对 f 的访问没有问题,因为 f 在 Super 中被声明为 protected,而 Sub 是 Super 的子类。相反,Other 对 f 的访问不被允许,因为 other 没有继承自 Super。而后者在 java 里同样被认可,因为 Other 与 Sub 在同一包里。
公共(Public)成员
Scala中,如果没有指定任何的修饰符,则默认为 public。这样的成员在任何地方都可以被访问。
class Outer {
class Inner {
def f() { println("f") }
class InnerMost {
f() // 正确
}
}
(new Inner).f() // 正确因为 f() 是 public}作用域保护
Scala中,访问修饰符可以通过使用限定词强调。格式为:
private[x] 或
protected[x]这里的x指代某个所属的包、类或单例对象。如果写成private[x],读作"这个成员除了对[…]中的类或[…]中的包中的类及它们的伴生对像可见外,对其它所有类都是private。
这种技巧在横跨了若干包的大型项目中非常有用,它允许你定义一些在你项目的若干子包中可见但对于项目外部的客户却始终不可见的东西。
package bobsrocckets{
package navigation{
private[bobsrockets] class Navigator{
protected[navigation] def useStarChart(){}
class LegOfJourney{
private[Navigator] val distance = 100
}
private[this] var speed = 200
}
}
package launch{
import navigation._
object Vehicle{
private[launch] val guide = new Navigator
}
}}上述例子中,类Navigator被标记为private[bobsrockets]就是说这个类对包含在bobsrockets包里的所有的类和对象可见。
比如说,从Vehicle对象里对Navigator的访问是被允许的,因为对象Vehicle包含在包launch中,而launch包在bobsrockets中,相反,所有在包bobsrockets之外的代码都不能访问类Navigator。
15.Scala运算符
一个运算符是一个符号,用于告诉编译器来执行指定的数学运算和逻辑运算。
Scala 含有丰富的内置运算符,包括以下几种类型:
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
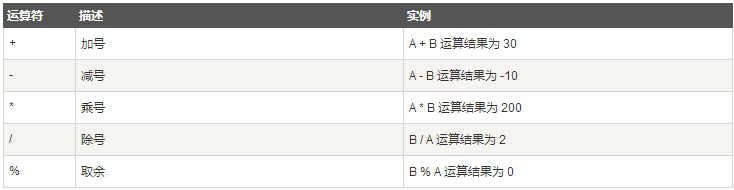
算术运算符
下表列出了 Scala 支持的算术运算符。
假定变量 A 为 10,B 为 20:
关系运算符
下表列出了 Scala 支持的关系运算符。
假定变量 A 为 10,B 为 20:
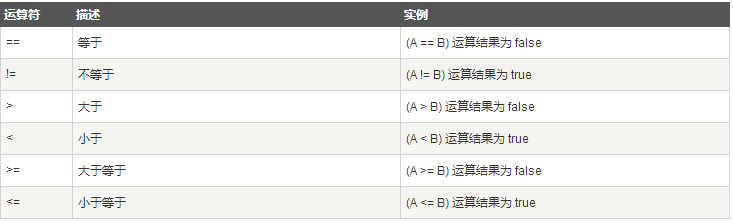
逻辑运算符
下表列出了 Scala 支持的逻辑运算符。
假定变量 A 为 1,B 为 0:

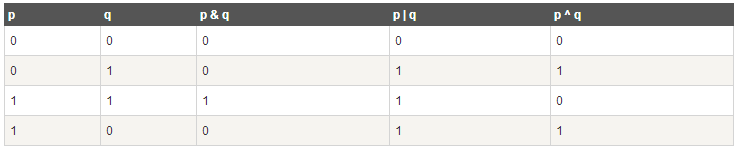
位运算符
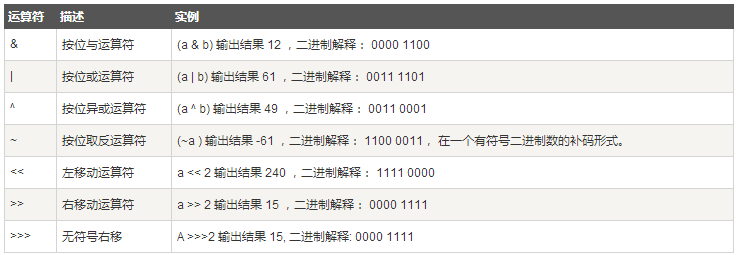
位运算符用来对二进制位进行操作,~,&,|,^分别为取反,按位与与,按位与或,按位与异或运算,如下表实例:
Scala 中的按位运算法则如下:
假定变量 a=60,b=13
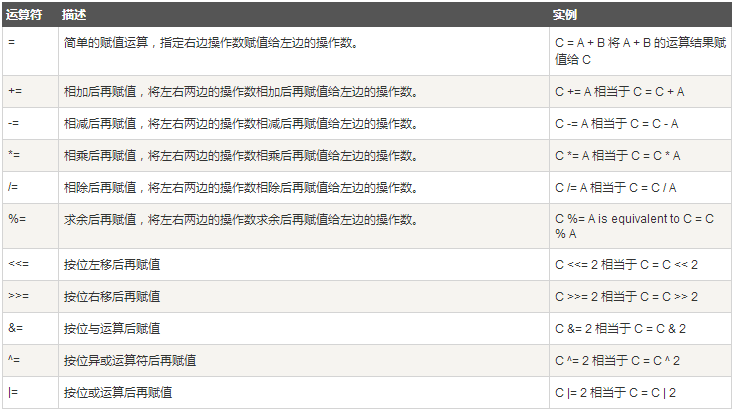
赋值运算符
以下列出了 Scala 语言支持的赋值运算符:
16.运算符优先级
在一个表达式中可能包含多个有不同运算符连接起来的、具有不同数据类型的数据对象;由于表达式有多种运算,不同的运算顺序可能得出不同结果甚至出现错误运算错误,因为当表达式中含多种运算时,必须按一定顺序进行结合,才能保证运算的合理性和结果的正确性、唯一性。
优先级从上到下依次递减,最上面具有最高的优先级,逗号操作符具有最低的优先级。
相同优先级中,按结合顺序计算。大多数运算是从左至右计算,只有三个优先级是从右至左结合的,它们是单目运算符、条件运算符、赋值运算符。
基本的优先级需要记住:
- 指针最优,单目运算优于双目运算。如正负号。
- 先乘除(模),后加减。
- 先算术运算,后移位运算,最后位运算。请特别注意:1 << 3 + 2 & 7 等价于 (1 << (3 + 2))&7
- 逻辑运算最后计算
















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









