







编译spark源码
参考spark官方文档build spark,我这里编译的是目前最新版本spark2.0.0,使用ubuntu需要环境如下:
- java
- git
- sbt
- Intellij idea
环境准备
配置java环境这个不用说了,因为spark是用scala写的,而scala需要java的环境,配好java的环境变量。
git的环境变量可配可不配,可以用来下载spark源码包,或者直接去上面我说的build spark的里面的一个download页面下载spark源码包,记得选择source code的下载,选合适的镜像会快点,国内的网比较蛋疼。配置的原因还有在后面用sbt编译的时候会git一些东西,但是不配的话也是可以编译通过的,下载的东西没有影响。
sbt是一个scala的一种编译工具,相当于java和maven的关系。[sbt官网]
下载sbt或者不下载都是可以的,因为在spark2.0.0的源码中的build这个目录中
提供了sbt这个shell脚本,我们直接运行./build/sbt,第一次的时候就会去网上自动下载sbt的对应版本,然后开始编译,所以不配置sbt也是ok的,如果window下那么shell脚本不可以使用,所以还是要自己下载和配置环境变量。
Intellij idae是用来方便看编译以后的源码。用过eclipse但是各种问题,所以后来改用idea了,问题少一点,而且电脑不卡啊,我8g电脑i7的cpu用eclipse导入项目以后卡的一笔。[下载地址]
下载社区版本,免费使用,用来看源码够用了.
编译
建议使用java1.8以后的版本。
进入spark项目的目录
$ ./build/sbt -Pyarn -Phadoop-2.6 clean package
这里指定了hadoop的版本为2.6,根据自己的需要指定。参考官方文档。
等待很多,因为第一次会下载很多依赖,如果不可以请使用科学的上网方式,我等了一个半小时左右。
显示如下就表示编译成功了。
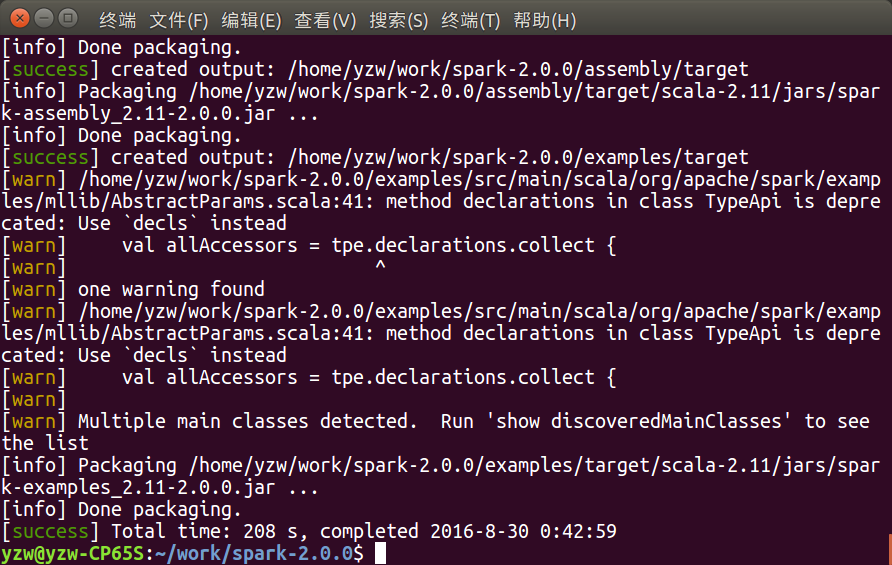
项目和子项目下生成target目录。图中[success]那部分。
导入Intellij idea
安装Intellij idea:
[下载]安装包以后,先解压,然后进入解压以后的项目目录看Install-Linux-tar.txt文件,可以知道需要运行./bin/idea.sh
$ tar -xzf ideaIC-2016.2.2.tar.gz #解压tar.gz文件
$ cd idea-IC-162.1628.40/
$ .bin/idea.sh #运行安装脚本
安装过程中要安装scala插件。
安装号以后打开如下:

从这里开始选择import maven项目。然后默认next就可以,中途最好把import
maven projects automatically 选上,然后就是要指定一下jdk的路径。
导入以后会有红色的线报错,不过无所谓,用这个来看代码和改代码的,
编译还是通过sbt命令行。
遇到的问题
1.编译的过程中有可能会报java heap OutOfMemory错误,这个时候换1.8版本以上的可以解决,window下可能还是不可以,需要设置环境变量
JAVA_OPTS=”-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m”















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









