







一般线性表的顺序查找,有序表的二分查找,基于索引的分块查找等都是有独特特征的查找方式,但是有一种查找夹在一般线性表和有序下的二分查找中间,很容易被忽视,因此提出来单独讨论。
这个查找就是:有序表的顺序查找。
简单说,这个名字已经包含了所有的条件信息:数据有序,但是采用的是顺序查找。对于有序表还不采用二分查找实在有点浪费时间的感觉,但是也有特定的应用场景。这里只对它的查找性质做分析。
主要分析的问题是:查找关键字的平均长度与查找失败的平均长度。
一个长度是n的有序表,比如:1,2,3,4,5
查找1需要1次;
查找2需要2次;
…
查找5需要5次;
因此平均需要查找的次数和一般无序的是一样的,即
5+12=3次。一般规律是n+12
.
而有意思的是查找失败时的平均查找次数。这个需要借助树结构才能更加明白的看到本质。
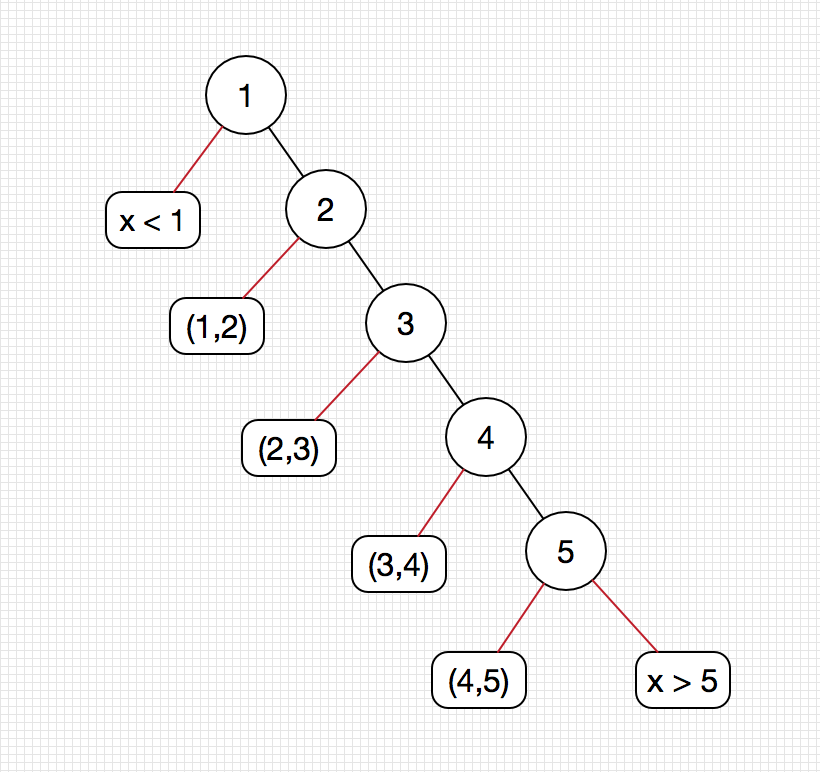
我以红线标识查找失败的路径。
查找在表中的关键字1,2,3,4,5自然没有问题。不在里面的时候,是不是像乱序的线性表一样,查到末尾才知道错了呢,不是的。只需要两个端点即可判定。比如查找1.5,和1比较一次,大于1对不对,那么往结点1的右边找,和2比较一次,现在比较两次了,1.5比2小,只能往2的左边跑,看吧,是红色的错误路线,因此,这次查找失败经过两次对比就可以显现出来了。
所以说,这个树其实是二叉排序树中最不平衡的倾斜树,为了避免这样的树形我们才引入了平衡树的概念。所以查找次数与树的深度相关,无论是成功还是失败,都是可以由深度计算。
可以看到,圆角矩形结点对应的是失败结点,数目恰好是关键字数目+1,因为错误结点并不比较,所以到错误结点的深度还是红色边的出发点,也就是我们可以这么看:
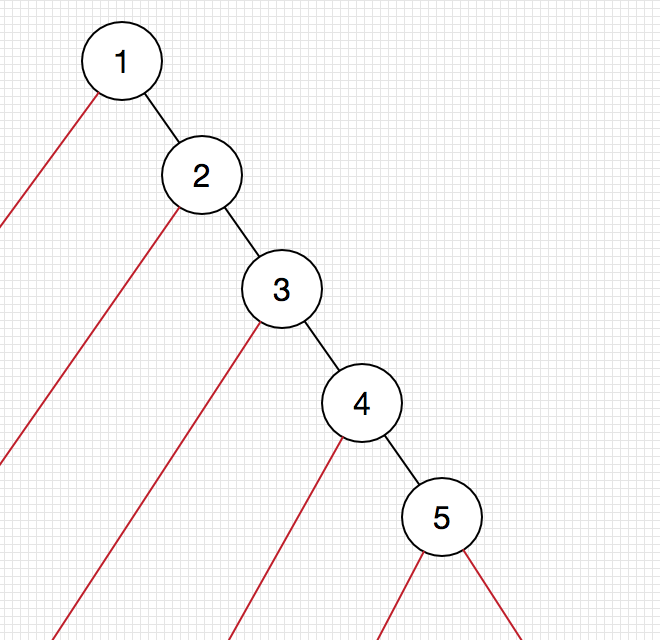
红色边对应的深度是边的起始结点的深度。
这么说是为了加深图像的认识。
因此,总的查找失败次数是:
1+2+3+4+..+n+n
,值得强调的是最后一个结点对应两个红色边。
这样得到的平均查找失败的次数是: (1+2+3+4+..+n+n)÷(n+1)
n+1是失败结点的个数。















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









